




- @2401_84080967
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
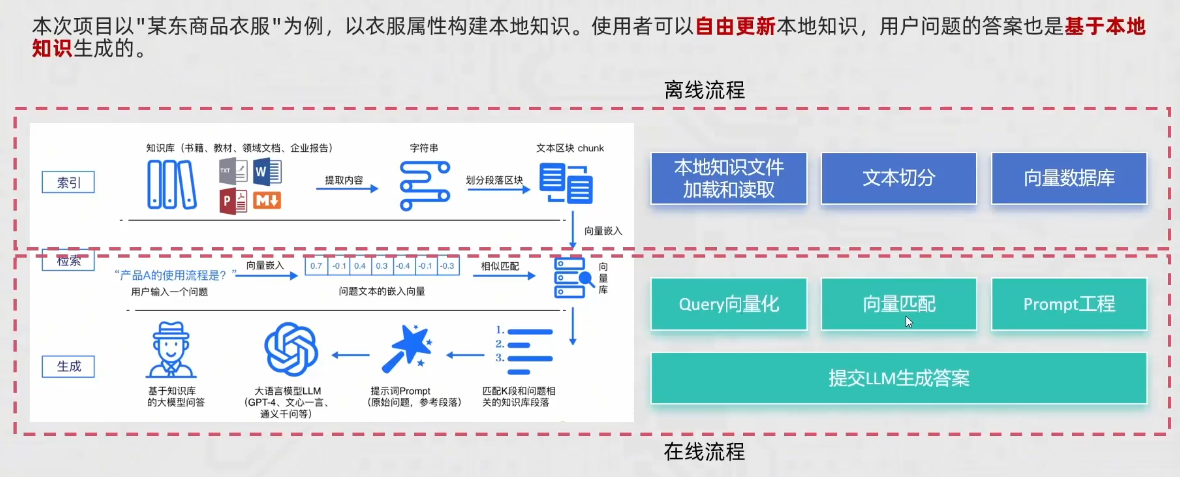
本文详细介绍了如何基于RAG(检索增强生成)技术实现智能客服系统。系统分为离线流程(构建向量数据库)和在线流程(用户交互)两部分:离线流程通过Embedding模型将文本向量化并存储到Chroma向量数据库,采用MD5技术防止重复上传;在线流程实现语义检索、提示词构建和大模型回答,支持对话历史存储。项目使用轻量级开源工具(SentenceTransformers、Chroma、LangChain等
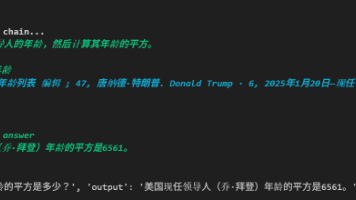
ReAct 并不是某种框架或组件,而是一种 推理-行动循环模式。思考 Thought分析当前问题,判断下一步该做什么行动 Action 调用某个工具或执行某个操作观察 Observation 获取工具返回的结果答案 Final Answer 当信息足够时,输出最终结论这种模式的核心价值在于:将语言模型的推理能力与外部工具的执行能力结合起来。ReAct 并不是一个固定的模块划分,而是一种让 LLM
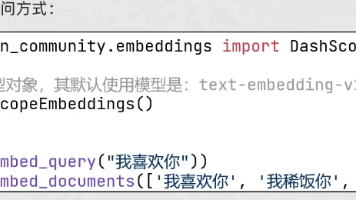
本文介绍了LangChain框架对大语言模型(LLMs)的集成应用,重点解析三类核心模型:1)LLMs基础语言模型,提供统一接口支持云平台和本地部署;2)ChatModels对话优化模型,支持多角色消息输入和流式输出;3)EmbeddingsModels文本嵌入模型,将自然语言转化为向量表示。通过代码示例展示了各类模型的具体调用方式,包括Azure云服务、本地Ollama部署及HuggingFac
本文详细介绍了如何基于RAG(检索增强生成)技术实现智能客服系统。系统分为离线流程(构建向量数据库)和在线流程(用户交互)两部分:离线流程通过Embedding模型将文本向量化并存储到Chroma向量数据库,采用MD5技术防止重复上传;在线流程实现语义检索、提示词构建和大模型回答,支持对话历史存储。项目使用轻量级开源工具(SentenceTransformers、Chroma、LangChain等
本文探讨了Prompt技术的本质及其工程化应用。作者指出Prompt已成为AGI时代的新型"人机接口语言",相当于编程语言,而Prompt工程则是相应的软件工程。文章强调Prompt工程的核心在于将随机性输出转化为稳定可用的系统功能,包含五个关键环节:需求定义、结构化设计、调优迭代、系统集成和持续运维。其中调优过程需考虑模型特性(如GPT偏好Markdown格式)、角色设定效果
本文介绍了如何本地部署AI代码助手作为Cursor/GitHub Copilot的替代方案。主要内容包括:1)分析本地部署在数据隐私和定制化方面的优势;2)选择Qwen2.5-14B-Instruct模型并完成部署;3)通过VSCode的Continue插件连接本地模型,详细说明了配置过程;4)测试验证功能实现。该方案特别适合企业内网开发等需要数据安全的场景,提供代码补全、对话交互等功能,同时保障
本文介绍了LangChain框架对大语言模型(LLMs)的集成应用,重点解析三类核心模型:1)LLMs基础语言模型,提供统一接口支持云平台和本地部署;2)ChatModels对话优化模型,支持多角色消息输入和流式输出;3)EmbeddingsModels文本嵌入模型,将自然语言转化为向量表示。通过代码示例展示了各类模型的具体调用方式,包括Azure云服务、本地Ollama部署及HuggingFac
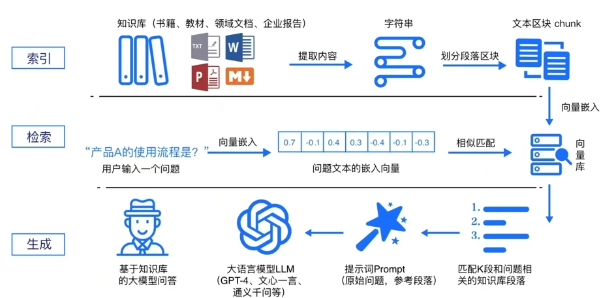
RAG(检索增强生成)通过为大模型配备一个可随时查阅的外部知识库,巧妙地解决了通用大模型知识静态、领域局限、易产生幻觉及数据安全等核心痛点。其核心思想检索+生成的双阶段协作,离线阶段将私有文档分块、向量化并构建索引,在线阶段将用户问题转为向量,从知识库中召回最相关的片段,再与问题一同输入大模型生成最终答案。在这个过程中,向量化扮演了关键角色——它将文本的语义转化为计算机可计算的数字表示,通过相似度
配置文件在实际开发中如何使用呢,接下去将通过Spring Boot整合mybatis来看配置文件如何在实际开发中被使用。
ReAct 并不是某种框架或组件,而是一种 推理-行动循环模式。思考 Thought分析当前问题,判断下一步该做什么行动 Action 调用某个工具或执行某个操作观察 Observation 获取工具返回的结果答案 Final Answer 当信息足够时,输出最终结论这种模式的核心价值在于:将语言模型的推理能力与外部工具的执行能力结合起来。ReAct 并不是一个固定的模块划分,而是一种让 LLM