




- @2303_77224751
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Adam 优化器通过结合动量和自适应学习率进行参数更新。详细的更新公式在上面的回答中已经给出。计算当前梯度∇θL∇θL的加权平均,用来估计梯度的期望。这个一阶动量主要是累积之前的梯度,使得更新方向更加平滑。mtβ1mt−11−β1∇θLmtβ1mt−11−β1∇θLβ1\beta_1β1是一阶动量的衰减率,通常取值为 0.9。mtm_tmt是当前的动量(梯度的指数加权平均)。

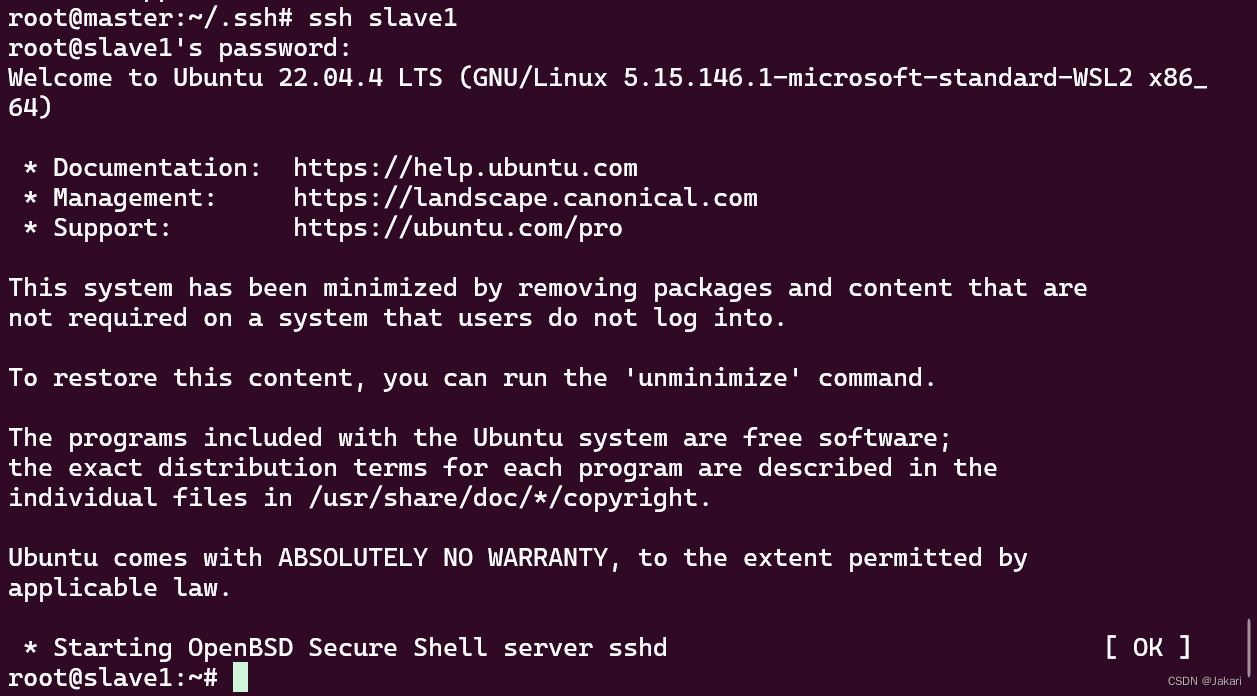
我在使用docker部署hadoop集群时,想测试三台节点的ssh连接情况,ssh一直不通,甚至ssh lcoalhost 也会出现Permission denied, please try again的问题,后来想到这三台节点是从同一个镜像运行出来的容器,是不是没有设置密码(类似于Linux第一次进入root时需要sudo passwd 设置新密码),后来设置密码后,过来ssh 成功了。如果这样
【代码】java: error while loading shared libraries: libjli.so: cannot open shared object file: No such file。

在搭建hadoop伪分布式环境时,开启hdfs-site.sh后,web端访问不到,但是节点已经正常开启:在尝试关闭防火墙后也没有效果,后来在/etc/hosts文件中加入本机的ip和主机名映射后,重新初始化namenode,web端可以正常访问(hadoop版本3以后默认端口是9870,之前的是50070):

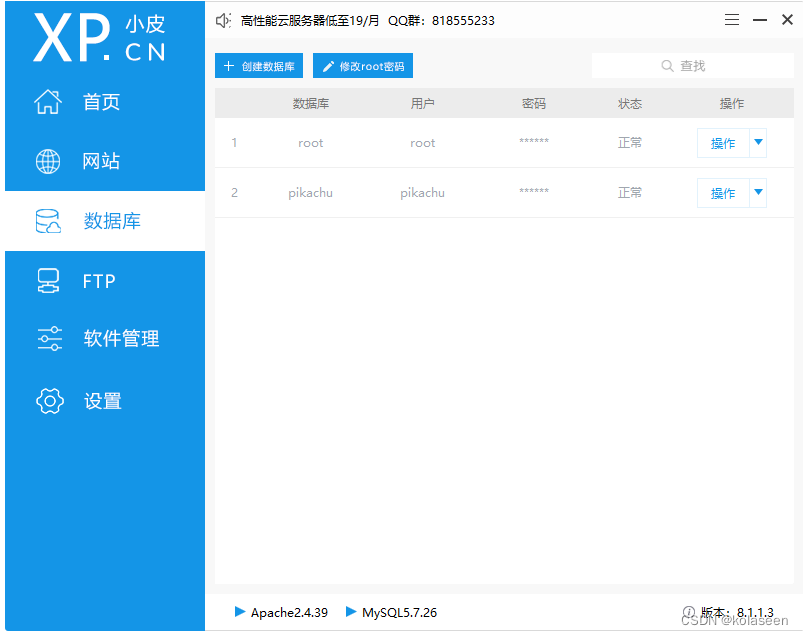
再创建一个新的数据库,进入pikachu-master/inc/config.inc.php文件中修改数据库的名称和密码即可。将下载好的Pikachu解压后放到PHPStudy中的www目录下。
每个窗口传输独立,如果某个窗口在传输中丢包,对方会将该数据包后面的数据重传,即使在其他窗口已经接受过该数据包,确保数据包的有序性。总长度,整个IP数据报的长度,包括首部和数据之和,单位为字节,最长65535,总长度必须不超过最大传输单元MTU。首部长度,如果不带Option字段,则为20,最长为60,该值限制了记录路由选项。首部检验和,只检验数据包的首部,不检验数据部分。这里不采用CRC检验码,而
CUDA是由NVIDIA开发的并行计算平台和编程模型,允许开发者利用支持CUDA的NVIDIA GPU来加速计算密集型任务。CUDA提供了扩展的C/C++语言,以及用于在GPU上执行并行计算的API。线程线程块线程的集合:线程块是多个线程的集合,组成一个可在 GPU 上执行的基本调度单元。线程块索引:通过 、、 获取线程块的索引。线程块大小:通过 、、 获取线程块的维度大小。全局线程索引:结合线程

VRP是华为公司从低端到高端的全系列路由器、交换机等数据通信产品的通用网络操作系统。VRP可以运行在多种硬件平台上,并拥有一致的网络界面、用户界面和管理界面。VRP以TCP/IP模型为参考,通过完善的技术架构设计,将路由技术、MPLS技术、VPN技术、安全技术等数据通行技术,以及实时操作系统、设备和网路管理、网络应用等多项技术完美的集成在一起,满足了运营商和企业用户的各种网络应用场景的需求。
CUDA是由NVIDIA开发的并行计算平台和编程模型,允许开发者利用支持CUDA的NVIDIA GPU来加速计算密集型任务。CUDA提供了扩展的C/C++语言,以及用于在GPU上执行并行计算的API。线程线程块线程的集合:线程块是多个线程的集合,组成一个可在 GPU 上执行的基本调度单元。线程块索引:通过 、、 获取线程块的索引。线程块大小:通过 、、 获取线程块的维度大小。全局线程索引:结合线程
在 PyTorch 中,当多个算子(operators)和内核(kernels)被并行执行时,PyTorch 通过 CUDA 的和机制来管理并发和同步。CUDA 是一个异步计算平台,计算任务会被放入一个队列中异步执行,PyTorch 为了确保不同算子之间的依赖关系正确,使用了流和事件来管理任务的调度和同步。