- @2302_77513263
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文探讨了企业级AI知识库问答系统中多轮对话上下文记忆的解决方案。作者采用Redis+MySQL分层存储架构,Redis作为短期记忆存储最近10-20轮对话,MySQL作为长期记忆存储对话摘要和元数据。通过智能滑动窗口、消息顺序保证和格式化上下文处理,解决了消息乱序问题。同时优化AI回答格式,重构SystemPrompt并压缩上下文,提升用户体验。测试验证表明方案有效,数据库设计包含重要性评分字段

摘要: "约定大于配置"是Java生态中的重要设计哲学,通过预定义规则减少显式配置。SpringBoot自动启动Tomcat、JPA自动映射字段、Maven标准目录结构等典型案例展示了其价值:提升开发效率,降低入门门槛。但该模式也存在学习成本高、调试困难等陷阱。最佳实践包括遵循默认约定、理解底层原理、团队统一规范等。该设计适用于标准化场景,在特殊需求时可通过显式配置覆盖。本质上

本文深入解析了Tomcat、Nginx和Node.js在后端开发中的角色与区别。Tomcat是Java专用的Servlet容器,负责运行Java后端程序;Nginx作为高性能Web服务器,主要承担反向代理、负载均衡和静态资源处理;Node.js则是JavaScript运行时,用于编写后端服务。三者并非竞争关系,而是各司其职:Nginx作为流量入口,Tomcat处理Java业务逻辑,Node.js适

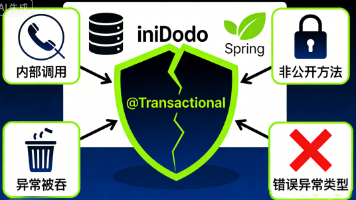
Spring 事务并非不存在,而是因为太“自动化”被初学者忽略。本文厘清核心误区:Spring 事务是基于 AOP 对 MySQL 事务的封装,不是替代品。重点剖析 8 大事务失效场景,包括内部调用、非 public 方法、异常被吞、异常类型不匹配等,并给出解决方案。同时对比 Spring 事务与 MySQL 事务在本质、粒度、传播行为、回滚规则等方面的差异。澄清另一误区:Spring 本地事务在
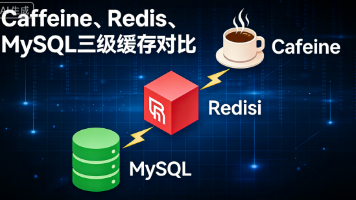
本文对比了MySQL、Redis、Caffeine三种数据源的定位与区别。MySQL是持久化存储,适合作为数据归宿;Redis是分布式内存缓存,适合跨进程共享热点数据;Caffeine是进程内本地缓存,能提供纳秒级访问延迟。文章分析了为什么在实际项目中Caffeine常常显得“多余”——多数场景Redis已足够快,而引入Caffeine会增加一致性和代码复杂度。但也给出了Caffeine真正适用的
2026年Java开发者的AI框架选择指南 随着AI技术普及,Java开发者面临框架选择难题。文章分析了三大主流框架:Python生态的LangChain(功能最全)、Java生态的SpringAI(与SpringBoot无缝集成)和LangChain4j(RAG支持最完整)。数据显示,78%的AI应用开发岗位要求Java技能,复合型人才薪资比纯Python开发者高40%。建议Java开发者:1)

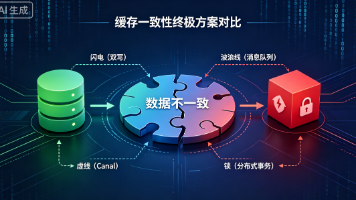
摘要 本文探讨了缓存(Redis)与数据库(MySQL)数据一致性的解决方案。作者从最初简单的"先更新数据库再删除缓存"方案入手,逐步分析了多种一致性方案:CacheAside模式、延迟双删、双写+消息队列、订阅binlog(Canal)以及分布式事务。每种方案都有其优缺点和适用场景,如Canal方案可实现业务无侵入但运维复杂,而分布式事务适合强一致性要求但性能较低。文章强调缓
本文总结了MyBatis-Plus的五大实用高级特性:逻辑删除通过标记字段实现数据"软删除";乐观锁通过版本号控制解决并发更新问题;自动填充简化公共字段(如创建时间)的维护;性能分析插件帮助识别慢SQL;多租户支持实现SaaS应用的数据隔离。作者结合电商项目实战经验,详细介绍了每个特性的配置方法、使用场景及注意事项,建议开发者根据业务需求合理选用这些特性,以提升开发效率和系统稳
从IP数据报到Nginx反向代理,这篇文章带你用后端开发的视角重新理解计算机网络的核心概念。文章先讲清IP协议的编址与封装,解释子网掩码、TTL等字段在实际排错中的意义;再深入路由表与最长前缀匹配,揭示路由器逐跳转发的本质。更重要的是,将这些408基础知识与Java开发场景一一对应:Nginx的location匹配就像一张URI路由表,Docker容器网络依赖Linux内核的路由与iptables

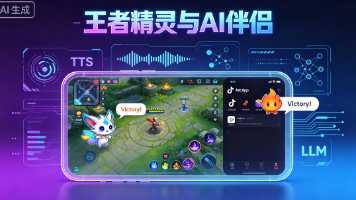
王者荣耀里的“灵宝”精灵和抖音的“小火人”,表面是可爱的游戏搭子,背后却是一套完整的AI Agent技术栈。它们能实时感知对局事件(击杀、买装备、输赢),通过大语言模型(LLM)生成符合人设的应答,再经语音合成(TTS)播报出来,实现“会说话、懂战术、有情绪”的交互体验。腾讯、网易、NVIDIA等巨头已纷纷布局,端侧AI正让这些能力跑在玩家的本地设备上。作为Java开发者,不必望而却步——Spri