- @2301_82275412
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Ollama,它来了,专为在本地机器便捷部署和运行大模型而设计。也许是目前最便捷的大模型部署和运行工具,配合Open WebUI,人人都可以拥有大模型自由。今天,就带着大家实操一番,从 0 到 1 玩转 Ollama。
2024年,AI大模型在医疗健康领域展现出强大的创新活力和商业潜力,各类应用场景不断深化,市场规模持续扩大。本文将从应用领域、市场发展及未来趋势等维度,全面回顾AI大模型在医疗健康领域的发展现状。1. 药物研发医药研发领域成为AI大模型最具突破性的应用场景之一。华为云"盘古大模型"和英矽智能"ChatPandaGPT"在肿瘤标志物挖掘和新药研发加速方面取得显著成果。耀速科技、水木分子等企业凭借其在

本文系统解析主流大模型推理部署框架(vLLM、SGLang、TensorRT-LLM、Ollama等)的核心技术、架构设计和适用场景。从显存优化、批处理技术、量化支持等方面对比各框架特点,帮助开发者根据业务需求、硬件资源和扩展规划选择合适的部署方案,为企业级应用和个人开发提供技术参考。

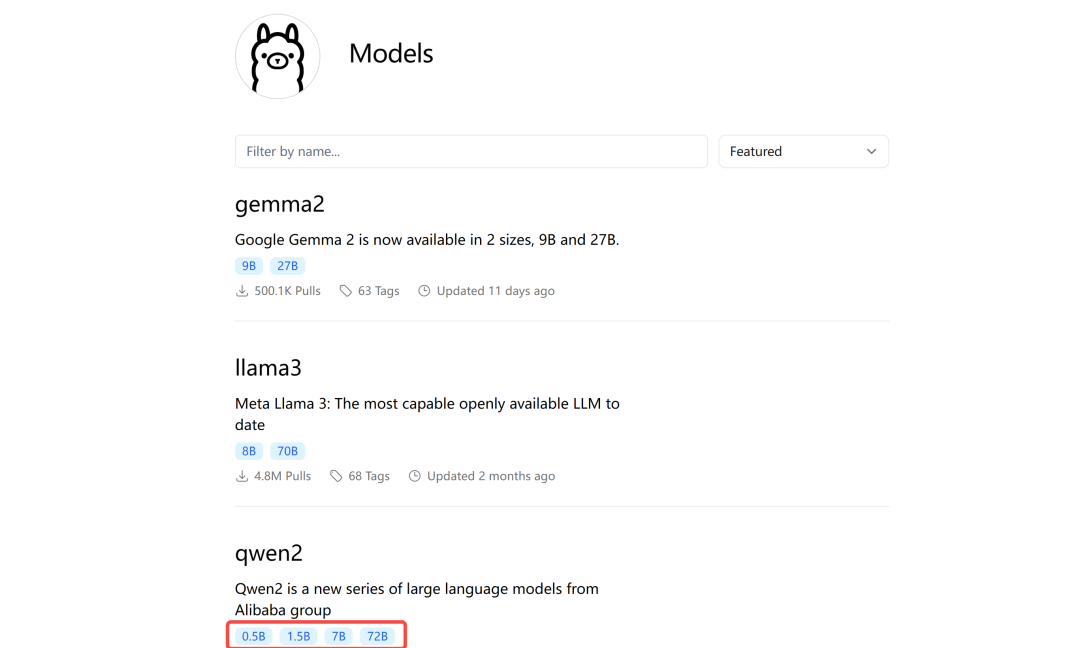
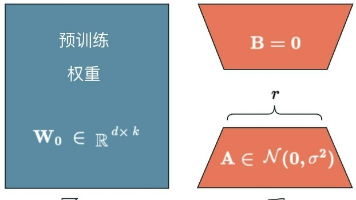
文章介绍大模型微调技术原理与实战,通过llama-factory工具实现零代码微调。详细讲解环境搭建、模型下载、数据集构建、参数设置及模型评测等完整流程,帮助读者将通用大模型转化为专业领域专家。以Qwen2.5为例,展示LORA高效微调方法,使读者快速掌握大模型微调技能,提升模型在特定专业领域的表现。
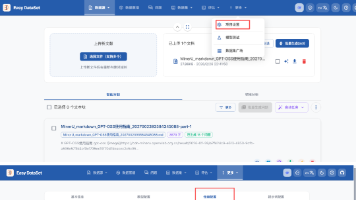
本文详解如何利用EasyDataset工具构建大模型微调所需的问答对数据集。涵盖问题生成(单条/批量)、答案生成(含思维链、多轮对话)、质量评估及导出为Alpaca/ShareGPT格式,手把手教你打造高质量SFT数据集。
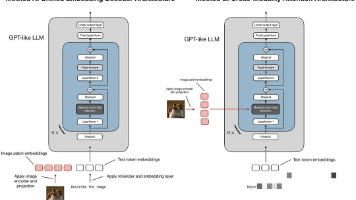
构建多模态线性线性模型主要有两种方法:* 方法 A:统一Embedding解码器架构方法* 方法 B:跨模态注意力架构方法
本文深入探讨LangChain与Python MCP集成的六大核心挑战:接口抽象冲突、状态同步问题、性能损耗、版本兼容性、调试困难及安全管控缺口。针对每个问题,提供系统化解决方案,如开发统一数据转换中间层、全异步改造、版本锁定策略等。强调在保持LangChain灵活性的同时,需平衡MCP的标准化,企业级应用应优先考虑适配层的精简与可维护性。
文章揭示了AI Agent的本质——即循环调用工具的大模型,并无神秘之处。重点解析了Agent Skills的概念,它是一套预设的工具、提示词和工作流组合,可理解为Meta-Tool(元工具),实现了从Agent到普通工具之间的能力抽象。Anthropic发布的Agent Skills开放标准提供统一实现,简化了开发者设计能力架构的心智负担,使Agent开发更加高效。

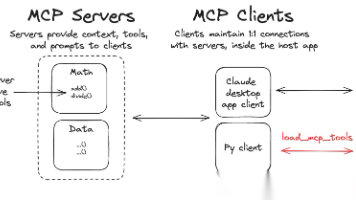
本文介绍了mcp-use,一个开源Python库,用于连接LLM和MCP服务器,简化AI智能体开发。它支持任何LangChain兼容的LLM提供商,提供多种连接方式、沙盒执行等功能,并允许通过JSON配置连接各种MCP服务器。使用mcp-use,开发者可以轻松构建具有工具访问能力的自定义智能体,降低大模型和AI Agent开发的门槛。
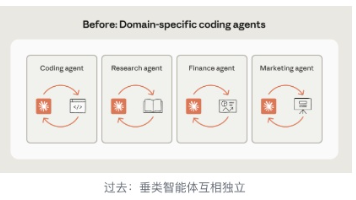
Anthropic提出“构建Skills而非专业Agent”的新范式,强调通过通用Agent结合Coding实现跨领域工作。文章介绍了Skills的概念、特点(设计简单、渐进式披露、含脚本工具)及其分类(基础、合作伙伴、企业技能)。此外,还探讨了Skills与MCP协同、非开发者应用等趋势,并给出了完整的Agent系统架构图。