




- @2301_78217634
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
数据清洗是数据分析的第一步,它的好坏直接影响到后续分析的准确性和可靠性。下面我们将详细介绍 12 种常见的数据清洗技术,并通过实际的代码示例来帮助大家更好地理解和掌握这些技术。

发送电子邮件是个很常见的开发需求。比如你写了个监控天气的脚本,发现第二天要下雨,或者网站上关注的某个商品降价了,就可以发个邮件到邮箱来提醒自己。使用 Python 脚本发送邮件并不复杂。不过由于各家邮件的发送机制和安全策略不同,常常会因为一些配置问题造成发送失败。今天我们来举例讲讲如何使用 Python 发送邮件。本文主要内容包括,了解发邮件的思路,发送邮件需要的一些设置,发送一封简单的邮件,发送

游标对象代表数据库中的游标,用于指示抓取数据操作的上下文,主要提供执行sql语句,调用存储过程、获取查询结果等方法。sqlite将整个数据库,包括定义、表、索引以及数据本身,作为一个单独的、可跨平台使用的文件存储在主机中。sqLite——嵌入式数据库,它的数据库就是一个文件。以上就是本次分享的全部内容。python内置了sqlite3。

掌握这些高级应用和优化技巧,将使你在数据分析的道路上更加得心应手。好了,今天的分享就到这里了,我们下期见。【点击这里】领取!包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!①Python所有方向的学习路线图,清楚各个方向要学什么东西②100多节Python课程视频,涵盖必备基础

强推**《Excel+Python:飞速搞定数据分析与处理》**,这是一本专为数据工作者量身打造的效率提升宝典。<文末附带PDF>本书由撰写,深入浅出地讲解了Python与Excel的完美结合。无论你是Excel高手还是Python新手,都能在这本书中找到提升工作效率的秘诀。书中不仅包含Python基础知识和pandas库的应用,还教你如何用Python自动化处理Excel中的复杂任务。这本书适合

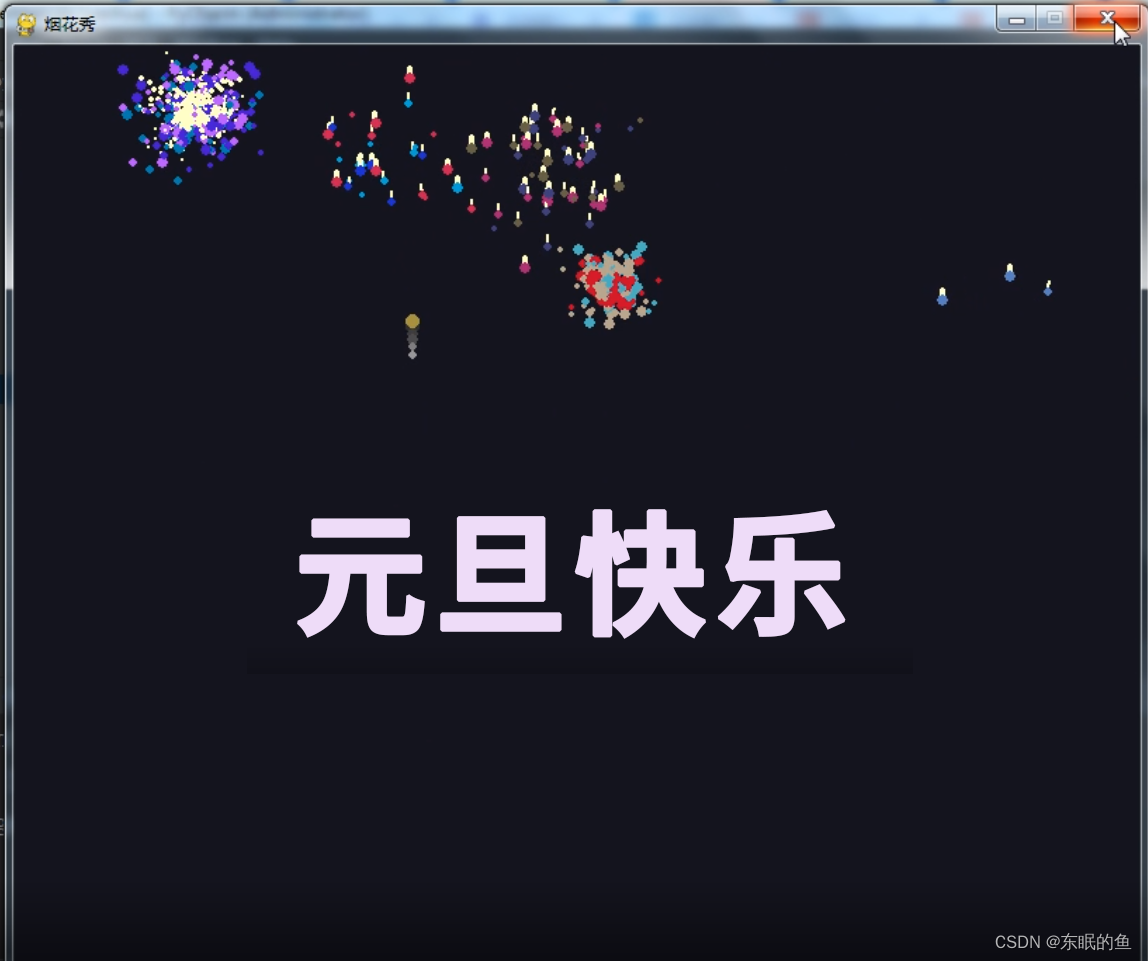
我用python代码带你看最绚烂的烟花,浪漫永不过时!
今天给大家带来用vscode、pycharm配置Python环境!

如果你对Python感兴趣的话,可以试试我整理的这份Python全套学习资料,【点击这里】领取!包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!① Python所有方向的学习路线图,清楚各个方向要学什么东西② 100多节Python课程视频,涵盖必备基础、爬虫和数据分析③ 10

存测试数据有时候有大批量的数据,存到TXT文件里面显然不是最佳的方式,我们可以存到Excel里面去,第一方便我们存数据和做数据,另一方面方便我们读取数据,比较明朗。测试的时候就从数据库中读取出来,这点是非常重要的。存测试结果可以批量把结果存入到Excel中,也是比较好整理数据点,比我们的TXT要好。

1. 打印 “Hello, World!2. 定义一个变量并打印其值3. 定义两个整数变量并计算它们的和4. 使用条件语句判断一个数是否为正数5. 使用循环打印从1到10的所有数字6. 使用while循环打印从1到10的所有数字7. 计算一个列表中所有元素的总和8. 判断一个字符串是否是回文9. 将一个字符串中的所有字母转换为大写10. 检查一个字符串是否包含特定子串11. 创建一个列表并添加元素
