- @2301_77193447
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文深入探讨了AI Agent停止策略的设计思路与实现方法。AI Agent本质是一个大循环,若无合理停止机制,会导致无限循环浪费资源或过早停止无法完成任务。文章分析了六种常用停止策略:硬性限制、任务完成检测、显式停止信号、循环检测、错误累积和用户中断。结合OpenManus和Gemini CLI的源码,详细展示了如何通过terminate工具、状态机管理、声明式输出系统和三层循环检测机制实现有效

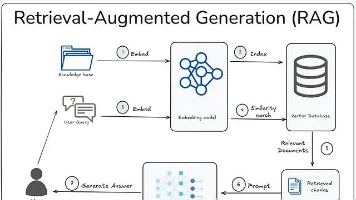
文章系统介绍了RAG系统中的21种文本分块策略,从基础方法(换行符分割、固定大小分块)到高级技术(语义分块、递归分块),每种策略均详细分析适用场景、技术要点并提供代码实现。这些方法针对不同数据类型和应用场景设计,能显著提升检索质量和生成效果,是构建可靠RAG系统的关键技术。
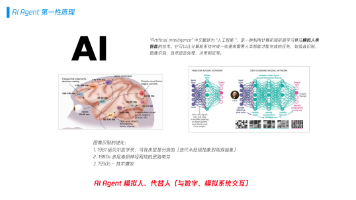
本文深入探讨了AI Agent的理论基础与第一性原理,详细分析了Agent协作技术从"手艺人"到"现代企业组织"的五个发展阶段,概述了Agent在算力、知识记忆、预测和动作执行方面的核心能力。文章展望了未来技术发展方向,包括大模型专业化、多模态能力提升、减少人类指令输入、数据共享与应用扩展,强调不同协作阶段各有适用场景,共同构成AI技术发展生态。
文章介绍谷歌开源的computer-use-preview项目,这是一个让AI直接操控电脑的Agent框架。它采用三层架构:BrowserAgent智能层、Computer接口抽象层和Playwright/Browserbase执行层。主要技术特点包括坐标归一化、截图滑动窗口和新页面劫持。该框架成本较高(每步约$0.002+),速度较慢(单步3-6秒),目前仅适配Chrome,面临页面加载完整性、
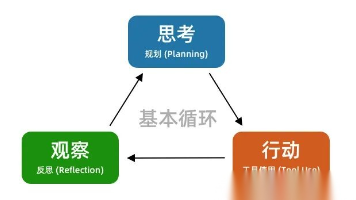
文章介绍了AI Agent(智能体)的底层逻辑和工作原理。AI应用正从简单的聊天助手进化为全能助理,其核心是"思考→行动→观察"的循环过程。Agent由大模型(大脑)、工具(手脚)和基本循环(流程)组成。文章提供了三个实用技巧:帮助Agent思考、提供精确的背景信息、创新式使用工具。理解这些原理能帮助用户更好地驾驭AI工具,发挥其最大效能。
文章介绍了使用腾讯IMA工具构建精简AI知识库的实践指南。强调知识库应"精"而非"多",建议为不同主题创建小型专业库。详细解释了RAG技术原理,分析了AI知识库的常见问题如幻觉和不精准检索,并提出了针对性解决方案。展望了未来多语种平行文本知识库的发展方向,指出AI知识库将改变传统研究方式,特别适合查缺补漏和文献整理。
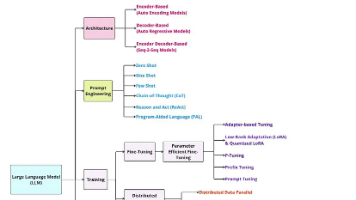
文章系统介绍了大模型微调技术的发展历程,从2018年全参数微调到2023年的偏好对齐技术,包括特征提取、Adapter、LoRA、提示微调、指令微调等方法。分析了各种微调技术的原理、特点和适用场景,解释了微调为何在大模型时代取代从零训练,并提供了根据实际业务需求选择合适微调方法的实用建议。
本文分析了LangChain与Python MCP集成的六大核心挑战:接口抽象冲突、状态管理不一致、性能损耗、版本兼容性问题、调试困难及安全管控缺口。提出标准化适配、统一状态管理、性能优化等解决方案,强调需平衡灵活性与标准化,根据场景取舍适配层设计。

Henon推出全球首个Zero-Error RAG系统,专为金融工作流设计,通过"零误差验证层"的四重保障机制,将AI幻觉率从传统RAG系统的8-15%降至接近零。该系统采用"生成中约束"架构,在智能解析、事实核查、交叉验证、溯源追踪和一致性检测方面实现突破,满足金融行业对AI"零容忍"的可靠性要求。虽然处理速度降低30%,但整体效率仍远超人工,为金融机构从"能用"到"敢用"AI提供了可靠路径。

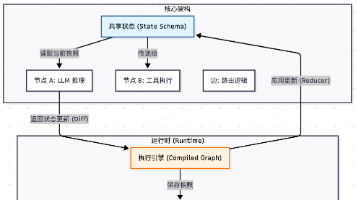
LangGraph是构建生产级Agent的底层操作系统,提供五大能力:持久化执行、人机协同、全方位记忆、调试支持和生产级部署。其架构基于状态在节点间的流转与演化,支持传统DAG不具备的循环功能,实现Agent的"思考-行动-观察"循环。LangGraph提供Graph API和Functional API两种开发模式,通过StateGraph、Nodes和Edges构建最小可用图,标志着LLM应用