




- @2301_76225313
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
通俗来说,人工智能就是让计算机像人类一样思考、学习和做出决策。通过利用各种技术(如机器学习、深度学习、专家系统等),人工智能系统可以处理和分析大量数据,自主地学习和优化算法,从而完成各种复杂的任务。人工智能的应用非常广泛,包括但不限于语音识别、图像识别、自然语言处理、智能推荐、智能客服等。具体的,从技术层面来看(如下图),现在所说的人工智能技术基本上就是机器学习(含深度学习)方面的技术。机器学习、

2024年2月,OpenAI发布其首款视频生成模型Sora,用户仅需输入一段文字即可生成长达一分钟场景切换流畅、细节呈现清晰、情感表达准确的高清视频,与一年前的AI生成视频相比,在各维度均实现了质的提升。这一突破再次将AIGC推向大众视野。AIGC即通过大量数据训练而成的人工智能系统,可根据用户的个性化指令生成文本、音频、图像、代码等内容。自2022年频频出圈的ChatGPT推出以来,生成式AI在
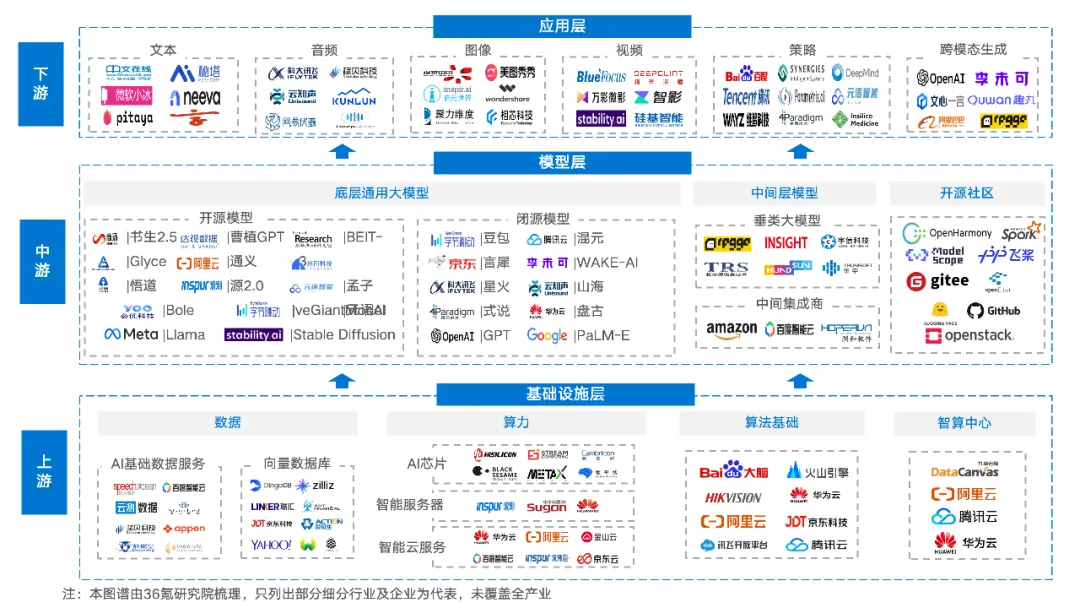
AI大语言模型(Large Language Models, LLMs)是近1-2年来人工智能领域的重要发展,它们通过深度学习技术,特别是基于Transformer的架构(如GPT、BERT等),实现了对自然语言处理的巨大突破。AI大语言模型的主要功能和作用有:文本生成、创意写作、对话生成、问答系统、文本翻译、代码生成、代码解释、文档生成、辅助写作、辅助设计等。1.讯飞星火大模型-AI大语言模型-
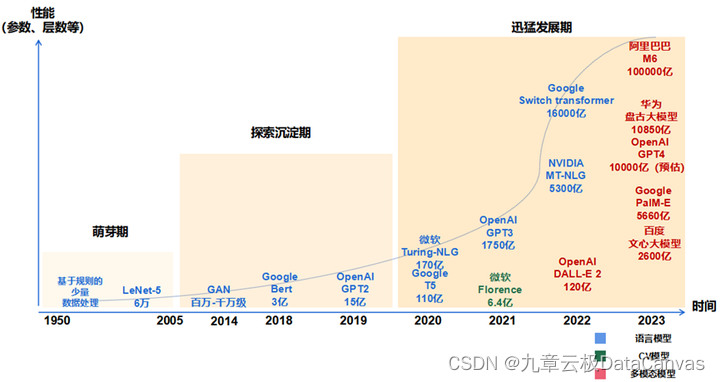
Meta旗下第三代大模型Llama 3终于在本周正式亮相:最大参数规模超4000亿,训练token超15万亿,对比GPT-3.5多种人类评估测评胜率超六成,官方号称“地表最强开源模型”。在各大科技巨头的“内卷”中,大模型终于来到了一个关键的转折点。摩根士丹利指出,世界正在进入一个由硬件和软件共同推动的大模型能力快速增长的新时代,大模型在创造力、战略思维和处理复杂多维任务方面的能力将显著提升。报告强

通俗来说,人工智能就是让计算机像人类一样思考、学习和做出决策。通过利用各种技术(如机器学习、深度学习、专家系统等),人工智能系统可以处理和分析大量数据,自主地学习和优化算法,从而完成各种复杂的任务。人工智能的应用非常广泛,包括但不限于语音识别、图像识别、自然语言处理、智能推荐、智能客服等。具体的,从技术层面来看(如下图),现在所说的人工智能技术基本上就是机器学习(含深度学习)方面的技术。机器学习、
大模型是指具有大规模参数和复杂计算结构的机器学习模型。这些模型通常由深度神经网络构建而成,拥有数十亿甚至数千亿个参数。大模型的设计目的是为了提高模型的表达能力和预测性能,能够处理更加复杂的任务和数据。大模型在各种领域都有广泛的应用,包括自然语言处理、计算机视觉、语音识别和推荐系统等。大模型通过训练海量数据来学习复杂的模式和特征,具有更强大的泛化能力,可以对未见过的数据做出准确的预测。
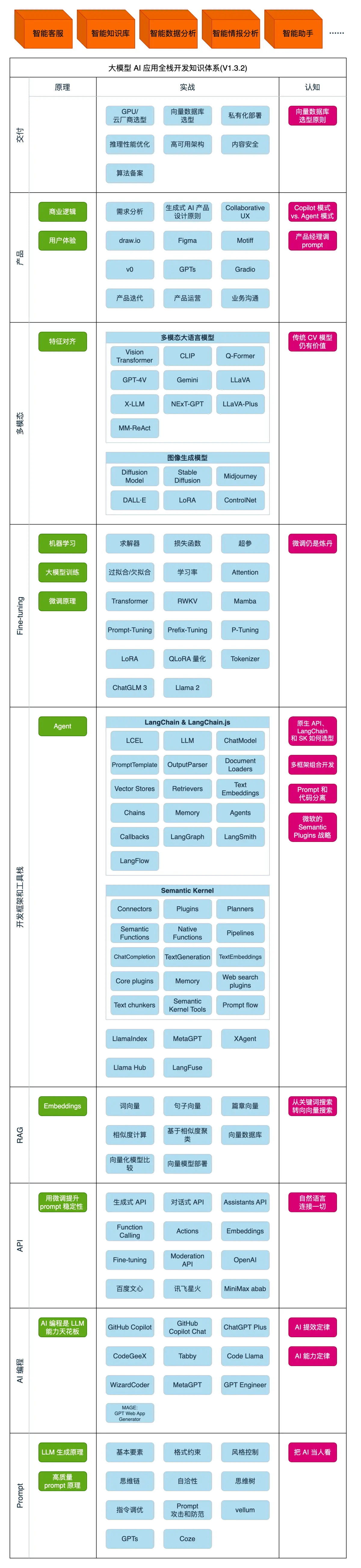
1、了解大模型能做什么2、整体了解大模型应用开发技术栈3、浅尝OpenAI API的调用AI全栈工程师:懂AI、懂编程、懂业务的超级个体,会是AGI(Artificial General Intelligence 通用人工智能)时代最重要的人。
在聊到AI的时候,我们都离不开“大模型”这三个字。百度李彦宏说 :大模型改变世界;360周鸿祎说:大模型是新时代“发电厂”;李开复博士说:AI大模型是不能错过的历史机遇;……那么,究竟什么是大模型?今天我想和你深度聊聊,欢迎和我链接,一起探讨大模型的更多可能性。
长按关注《AI科技论谈》LLM是如今大多数AI聊天机器人的核心基础,例如ChatGPT、Gemini、MetaAI、Mistral AI等。这些LLM背后的核心是Transformer架构。本文介绍如何一步步使用PyTorch从零开始构建和训练一个大型语言模型(LLM)。该模型以Transformer架构为基础,实现英文到马来语的翻译功能,同时也适用于其他语言翻译任务。

该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。大模型已经发布很久,网络上的大模型形
