告别AI逻辑跑偏!即插即用BST,给你的模型装上“未来导航仪”
《信念状态变换器(BST)》提出了一种革命性的双向预测模块,旨在解决传统前向Transformer在规划任务中的局限性。该模块通过双编码器架构(前向和后向编码器)同时处理前缀和后缀序列,并采用双重预测目标(预测前后token)来学习紧凑的信念状态表示。实验证明,BST在星图导航等复杂任务中达到100%准确率,远超传统方法的20%-50%。该技术为Transformer在规划密集型任务中的应用开辟了
BST 模块
论文《The Belief State Transformer》
论文地址: https://edwhu.github.io/bst-website
发表期刊: 2025年最新论文
深度交流Q裙:607618759
全网同名 【大嘴带你水论文】 B站定时发布详细讲解视频
详细代码见文章最后

1、作用
BST(Belief State Transformer)是一个革命性的双向预测模块,专门解决传统前向Transformer在规划任务中的局限性。该模块通过同时接收前缀和后缀作为输入,预测前缀的下一个token和后缀的前一个token,学习到紧凑的信念状态(Belief State)来捕获所有相关信息。BST能够有效解决传统前向Transformer难以处理的挑战性问题,如星图导航、目标条件文本生成等规划密集型任务。实验表明,BST在星图问题上达到100%准确率,而传统方法仅能达到随机猜测水平(20%-50%)。该模块还支持目标条件解码、测试时推理规划和高质量文本表示学习,为Transformer架构在复杂推理任务上的应用开辟了新方向。
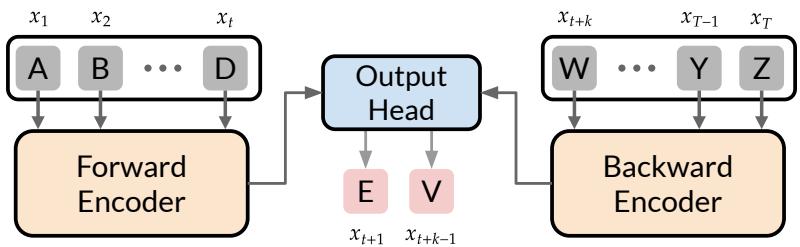
图1. BST的双编码器架构:前向编码器处理前缀,后向编码器处理后缀
2、机制
1、双编码器架构(Dual Encoder Architecture):
BST包含两个独立的编码器:前向编码器F(x₁:t)处理前缀序列,后向编码器B(x_{t+k:T})处理后缀序列。两个编码器都采用GPT2风格的Transformer架构,但处理方向相反。前向编码器按正常顺序处理token,后向编码器则反向处理。这种设计使模型能够同时利用过去和未来的信息来做出更准确的预测。
2、双重预测目标(Dual Prediction Objective):
BST的训练目标是同时预测两个方向的token:下一个token预测器T_n预测前缀后的下一个token,前一个token预测器T_p预测后缀前的前一个token。损失函数为:L = E[log(1/T_n(x_{t+1}|F(x₁:t), B(x_{t+k:T}))) + log(1/T_p(x_{t+k-1}|F(x₁:t), B(x_{t+k:T})))]。这种双重目标迫使模型学习更完整的序列表示。
3、信念状态学习(Belief State Learning):
信念状态是包含预测未来所需全部信息的紧凑表示。BST通过双向预测自然地学习到这种表示,因为模型必须在前向编码中保留足够信息来准确预测后向序列。理论分析证明,理想的BST能够恢复完整的信念状态,而传统的前向或多token预测方法无法保证这一点。
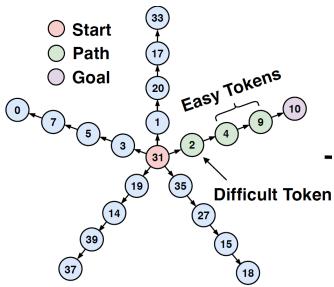
图2. 信念状态的学习过程和表示能力
3、代码
完整代码见gitcode地址:https://gitcode.com/2301_80107842/research
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
from typing import Optional, Tuple, Dict, Any
class LayerNorm(nn.Module):
"""LayerNorm with optional bias"""
def __init__(self, ndim, bias=True):
super().__init__()
self.weight = nn.Parameter(torch.ones(ndim))
self.bias = nn.Parameter(torch.zeros(ndim)) if bias else None
def forward(self, input):
return F.layer_norm(input, self.weight.shape, self.weight, self.bias, 1e-5)
class CausalSelfAttention(nn.Module):
"""多头因果自注意力机制"""
def __init__(self, config):
super().__init__()
assert config.n_embd % config.n_head == 0
# QKV投影
self.c_attn = nn.Linear(config.n_embd, 3 * config.n_embd, bias=config.bias)
# 输出投影
self.c_proj = nn.Linear(config.n_embd, config.n_embd, bias=config.bias)
# 正则化
self.attn_dropout = nn.Dropout(config.dropout)
self.resid_dropout = nn.Dropout(config.dropout)
self.n_head = config.n_head
self.n_embd = config.n_embd
self.dropout = config.dropout
def forward(self, x, mask=None):
B, T, C = x.size() # batch size, sequence length, embedding dimensionality
# 计算QKV
q, k, v = self.c_attn(x).split(self.n_embd, dim=2)
k = k.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
q = q.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
v = v.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
# 注意力计算
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
# 应用掩码
if mask is not None:
att = att.masked_fill(mask == 0, float('-inf'))
att = F.softmax(att, dim=-1)
att = self.attn_dropout(att)
y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
y = y.transpose(1, 2).contiguous().view(B, T, C) # 重新组装所有头的输出
# 输出投影
y = self.resid_dropout(self.c_proj(y))
return y
class MLP(nn.Module):
"""多层感知机"""
def __init__(self, config):
super().__init__()
self.c_fc = nn.Linear(config.n_embd, 4 * config.n_embd, bias=config.bias)
self.gelu = nn.GELU()
self.c_proj = nn.Linear(4 * config.n_embd, config.n_embd, bias=config.bias)
self.dropout = nn.Dropout(config.dropout)
def forward(self, x):
x = self.c_fc(x)
x = self.gelu(x)
x = self.c_proj(x)
x = self.dropout(x)
return x
class TransformerBlock(nn.Module):
"""Transformer块"""
def __init__(self, config):
super().__init__()
self.ln_1 = LayerNorm(config.n_embd, bias=config.bias)
self.attn = CausalSelfAttention(config)
self.ln_2 = LayerNorm(config.n_embd, bias=config.bias)
self.mlp = MLP(config)
def forward(self, x, mask=None):
x = x + self.attn(self.ln_1(x), mask=mask)
x = x + self.mlp(self.ln_2(x))
return x
class TextHead(nn.Module):
"""双向预测头"""
def __init__(self, config):
super().__init__()
self.config = config
input_dim = config.n_embd * 2 # 前向和后向编码拼接
# MLP融合前向和后向嵌入
self.mlp = nn.Sequential(
nn.Linear(input_dim, input_dim, bias=config.bias),
nn.GELU(),
nn.Dropout(config.dropout),
nn.Linear(input_dim, input_dim, bias=config.bias),
)
self.norm = LayerNorm(input_dim, bias=config.bias)
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
def forward(self, forward_emb, backward_emb, targets_next=None, targets_prev=None):
"""
前向传播
Args:
forward_emb: 前向编码 (batch_size, n_embd)
backward_emb: 后向编码 (batch_size, n_embd)
targets_next: 下一个token目标
targets_prev: 前一个token目标
Returns:
logits或loss
"""
# 拼接前向和后向嵌入
x = torch.cat([forward_emb, backward_emb], dim=-1)
# 残差连接和归一化
x = x + self.mlp(x)
x = self.norm(x)
# 分割为下一个和前一个token的表示
x_next, x_prev = x.chunk(2, dim=-1)
if targets_next is None and targets_prev is None:
# 返回logits
logits_next = self.lm_head(x_next)
logits_prev = self.lm_head(x_prev)
return torch.stack([logits_next, logits_prev], dim=1)
else:
# 计算损失
loss_next = loss_prev = None
if targets_next is not None:
logits_next = self.lm_head(x_next)
loss_next = F.cross_entropy(logits_next, targets_next)
if targets_prev is not None:
logits_prev = self.lm_head(x_prev)
loss_prev = F.cross_entropy(logits_prev, targets_prev)
return loss_next, loss_prev
class TransformerEncoder(nn.Module):
"""双向Transformer编码器"""
def __init__(self, config):
super().__init__()
self.config = config
# 共享的token嵌入
self.token_embedding = nn.Embedding(config.vocab_size, config.n_embd)
self.position_embedding = nn.Embedding(config.block_size, config.n_embd)
# 前向Transformer
self.transformer_f = nn.ModuleDict(dict(
blocks=nn.ModuleList([TransformerBlock(config) for _ in range(config.n_layer)]),
norm=LayerNorm(config.n_embd, bias=config.bias),
))
# 后向Transformer
self.transformer_b = nn.ModuleDict(dict(
blocks=nn.ModuleList([TransformerBlock(config) for _ in range(config.n_layer)]),
norm=LayerNorm(config.n_embd, bias=config.bias),
))
self.apply(self._init_weights)
def _init_weights(self, module):
if isinstance(module, nn.Linear):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
if module.bias is not None:
torch.nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
def forward_encode(self, tokens, mask=None):
"""前向编码"""
b, t = tokens.size()
pos = torch.arange(0, t, dtype=torch.long, device=tokens.device)
# Token和位置嵌入
tok_emb = self.token_embedding(tokens)
pos_emb = self.position_embedding(pos)
x = tok_emb + pos_emb
# 通过前向Transformer块
for block in self.transformer_f.blocks:
x = block(x, mask=mask)
x = self.transformer_f.norm(x)
return x
def backward_encode(self, tokens, mask=None):
"""后向编码"""
b, t = tokens.size()
# 反转token序列
tokens = torch.flip(tokens, dims=[1])
pos = torch.arange(0, t, dtype=torch.long, device=tokens.device)
# Token和位置嵌入
tok_emb = self.token_embedding(tokens)
pos_emb = self.position_embedding(pos)
x = tok_emb + pos_emb
# 通过后向Transformer块
for block in self.transformer_b.blocks:
x = block(x, mask=mask)
x = self.transformer_b.norm(x)
return x
class BeliefStateTransformer(nn.Module):
"""信念状态Transformer"""
def __init__(self, config):
super().__init__()
self.config = config
self.encoder = TransformerEncoder(config)
self.text_head = TextHead(config)
def forward(self, prefix_tokens, suffix_tokens=None, targets_next=None, targets_prev=None):
"""
前向传播
Args:
prefix_tokens: 前缀token序列 (batch_size, prefix_len)
suffix_tokens: 后缀token序列 (batch_size, suffix_len),可选
targets_next: 下一个token目标
targets_prev: 前一个token目标
Returns:
logits或loss
"""
# 前向编码
forward_emb = self.encoder.forward_encode(prefix_tokens)
forward_emb = forward_emb[:, -1, :] # 取最后一个位置的表示
# 后向编码
if suffix_tokens is not None:
backward_emb = self.encoder.backward_encode(suffix_tokens)
backward_emb = backward_emb[:, -1, :] # 取最后一个位置的表示
else:
# 推理时使用空后缀
batch_size = prefix_tokens.size(0)
backward_emb = torch.zeros(batch_size, self.config.n_embd,
device=prefix_tokens.device, dtype=prefix_tokens.dtype)
# 通过预测头
return self.text_head(forward_emb, backward_emb, targets_next, targets_prev)
def generate(self, prefix_tokens, max_length=50, temperature=1.0):
"""
自回归生成
Args:
prefix_tokens: 前缀token序列
max_length: 最大生成长度
temperature: 采样温度
Returns:
生成的token序列
"""
self.eval()
generated = prefix_tokens.clone()
with torch.no_grad():
for _ in range(max_length):
# 获取logits
logits = self.forward(generated)
next_logits = logits[:, 0, :] # 下一个token的logits
# 温度采样
if temperature > 0:
next_logits = next_logits / temperature
probs = F.softmax(next_logits, dim=-1)
next_token = torch.multinomial(probs, num_samples=1)
else:
next_token = torch.argmax(next_logits, dim=-1, keepdim=True)
# 添加到序列
generated = torch.cat([generated, next_token], dim=1)
# 检查结束条件
if next_token.item() == self.config.eos_token_id:
break
return generated
# 配置类
class BSTConfig:
def __init__(self):
self.block_size = 1024 # 最大序列长度
self.vocab_size = 50257 # 词汇表大小
self.n_layer = 12 # Transformer层数
self.n_head = 12 # 注意力头数
self.n_embd = 768 # 嵌入维度
self.dropout = 0.1 # Dropout率
self.bias = False # 是否使用bias
self.eos_token_id = 50256 # 结束token ID
# 测试代码
if __name__ == '__main__':
# 创建配置
config = BSTConfig()
config.vocab_size = 1000
config.block_size = 256
config.n_layer = 6
config.n_head = 8
config.n_embd = 512
# 创建模型
model = BeliefStateTransformer(config)
# 创建测试数据
batch_size = 2
prefix_len = 10
suffix_len = 8
prefix_tokens = torch.randint(0, config.vocab_size, (batch_size, prefix_len))
suffix_tokens = torch.randint(0, config.vocab_size, (batch_size, suffix_len))
# 前向传播
logits = model(prefix_tokens, suffix_tokens)
# 生成测试
generated = model.generate(prefix_tokens[:1], max_length=20, temperature=0.8)
# 打印结果
print('输入前缀尺寸:', prefix_tokens.size())
print('输入后缀尺寸:', suffix_tokens.size())
print('输出logits尺寸:', logits.size())
print('生成序列尺寸:', generated.size())
print('参数数量:', sum(p.numel() for p in model.parameters()) / 1e6, 'M')
print('前向编码器层数:', config.n_layer)
print('后向编码器层数:', config.n_layer)
print('注意力头数:', config.n_head)
print('嵌入维度:', config.n_embd)

纵情码海钱塘涌,杭州开发者创新动! 属于杭州的开发者社区!致力于为杭州地区的开发者提供学习、合作和成长的机会;同时也为企业交流招聘提供舞台!
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)