




- @2301_80107842
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
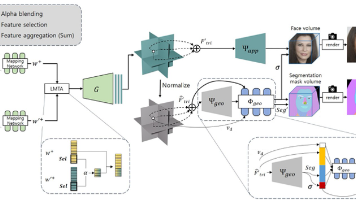
FFaceNeRF是一种基于神经辐射场的小样本3D人脸编辑方法,通过几何适配器将固定布局分割图调整为自定义蒙版布局。其核心创新包括:1)几何适配器和特征注入机制实现灵活编辑;2)三平面增强的潜在混合策略提升小样本学习效果;3)基于重叠的优化确保精细区域编辑精度。仅需约10个样本即可训练,支持用户自由定义编辑区域,在保持人脸身份特征的同时实现高精度局部编辑。该方法突破了传统NeRF人脸编辑对固定分割
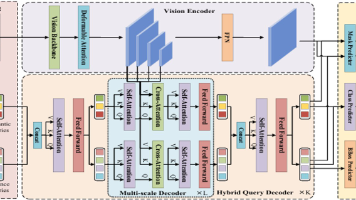
【论文摘要】DocSAM提出了一种统一文档图像分割框架,通过查询分解和异构混合学习解决现有方法泛化性差的问题。该模型采用实例查询和语义查询的双路径设计,在混合查询解码器中进行交互:首先通过自注意力交换信息,再分别与图像特征进行交叉注意力计算,最后通过开放集分类机制实现多任务统一处理。核心创新包括:1)将不同分割任务统一为实例/语义分割组合;2)利用Sentence-BERT生成语义查询;3)通过点
论文《LEARNING TRANSFORMER-BASED WORLD MODELS WITH CONTRASTIVE PREDICTIVE CODING》论文地址: https://openreview.net/forum?深度交流Q裙:1051849847全网同名 【大嘴带你水论文】 B站定时发布详细讲解视频详细代码见文章最后。
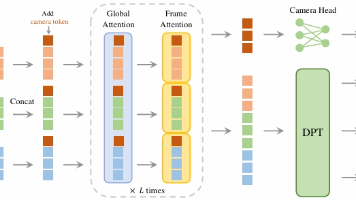
VGGT是一个统一的视觉通用模型,通过引导式Transformer架构同时处理点跟踪、深度估计、相机位姿估计和光流预测等多项视觉任务。其核心机制包括交替注意力(帧内和全局注意力)、专用Token(相机和寄存器Token)以及多任务预测头。代码实现展示了关键组件,如多头注意力模块和密集预测头。该模型通过单一架构实现多任务处理,无需为每个任务设计专用解码器,具有高效建模时空依赖关系的能力。
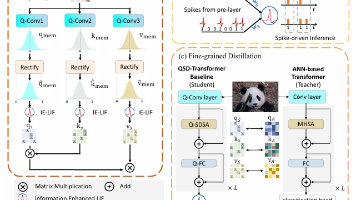
本文提出了一种量化的脉冲驱动Transformer模块(QSD-Transformer),用于解决脉冲神经网络在资源受限设备上的部署挑战。该模块通过将32位权重量化到2-4位,实现了显著的能耗降低和模型压缩。核心创新包括:1)量化脉冲驱动自注意力机制(Q-SDSA),大幅降低计算复杂度;2)信息增强LIF神经元(IE-LIF),在训练时保持丰富信息表达,推理时切换为高效二进制模式;3)细粒度蒸馏方

CogVideoX是一个基于扩散Transformer的文本到视频生成模型,能够生成10秒768×1360分辨率的高质量视频。其核心创新包括:1)3D因果变分自编码器在时空维度压缩视频;2)专家自适应LayerNorm处理多模态特征;3)3D全注意力机制实现连贯运动生成。模型通过渐进训练和多分辨率帧打包技术,显著提升了视频时长和运动连贯性,在定量和定性评估中均优于现有方法。完整实现代码已开源。

《信念状态变换器(BST)》提出了一种革命性的双向预测模块,旨在解决传统前向Transformer在规划任务中的局限性。该模块通过双编码器架构(前向和后向编码器)同时处理前缀和后缀序列,并采用双重预测目标(预测前后token)来学习紧凑的信念状态表示。实验证明,BST在星图导航等复杂任务中达到100%准确率,远超传统方法的20%-50%。该技术为Transformer在规划密集型任务中的应用开辟了

《信念状态变换器(BST)》提出了一种革命性的双向预测模块,旨在解决传统前向Transformer在规划任务中的局限性。该模块通过双编码器架构(前向和后向编码器)同时处理前缀和后缀序列,并采用双重预测目标(预测前后token)来学习紧凑的信念状态表示。实验证明,BST在星图导航等复杂任务中达到100%准确率,远超传统方法的20%-50%。该技术为Transformer在规划密集型任务中的应用开辟了