




- @zxl52012
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
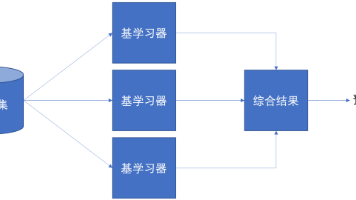
集成学习通过组合多个弱学习器构建更强模型。训练:依次训练多个弱模型预测:所有弱学习器联合决策优势:比单个模型更准、更稳、更不易过拟合集成学习 = 多个弱模型组合Bagging:并行、有放回、平权投票Boosting:串行、纠错、加权投票基于Bagging + 决策树有放回抽样随机选择部分特征训练多棵 CART 树平权投票输出结果随机森林 = Bagging + 决策树 + 双随机步骤:抽样 → 选
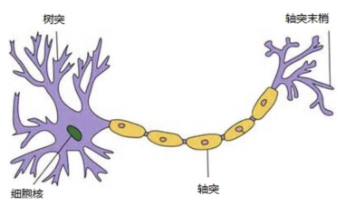
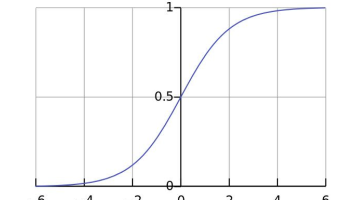
人工神经网络核心知识点摘要 人工神经网络(ANN)是一种模仿生物神经网络的非线性计算模型,由输入层、隐藏层和输出层构成。核心组件包括: 神经元:基本计算单元,通过加权求和(z=Wx+b)和激活函数(a=f(z))处理输入信号 激活函数:引入非线性因素,常见类型: Sigmoid(0-1输出) Tanh(-1到1输出) ReLU(解决梯度消失) Softmax(多分类概率输出) 参数优化: 初始化方
深度学习是机器学习的分支,通过多层神经网络自动提取特征,擅长处理图像、语音等高维数据。其发展经历了符号主义、统计主义、神经网络和大模型四个阶段,关键里程碑包括反向传播算法、AlexNet和Transformer的突破。主流框架包括TensorFlow、PyTorch和国产PaddlePaddle,核心模型涵盖CNN、RNN、Transformer和GAN等,分别适用于图像识别、序列处理、语言理解和
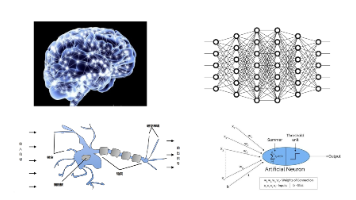
深度学习是机器学习的分支,通过多层神经网络自动提取特征,擅长处理图像、语音等高维数据。其发展经历了符号主义、统计主义、神经网络和大模型四个阶段,关键里程碑包括反向传播算法、AlexNet和Transformer的突破。主流框架包括TensorFlow、PyTorch和国产PaddlePaddle,核心模型涵盖CNN、RNN、Transformer和GAN等,分别适用于图像识别、序列处理、语言理解和
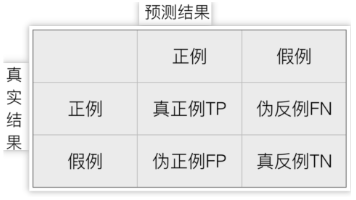
摘要 混淆矩阵是评估分类模型性能的重要工具,通过对比预测结果与真实标签,揭示模型的预测准确性。核心指标包括真正例(TP)、伪反例(FN)、伪正例(FP)和真反例(TN)。精确率(查准率)衡量预测正例的准确性,召回率(查全率)评估正例的覆盖程度,F1-score则综合两者表现。在癌症预测等不平衡数据场景中,仅依赖准确率可能产生误导,需结合多个指标全面评估模型性能。实际应用中,可通过Python的sk
逻辑回归是一种经典的二分类算法,广泛应用于疾病预测、贷款审批、情感分析等场景。其核心是通过Sigmoid函数将线性回归输出转换为概率值,利用阈值判断完成分类。算法涉及边际概率、联合概率和条件概率等数学基础,采用二分类交叉熵作为损失函数,通过极大似然估计进行优化。实战中可使用sklearn的LogisticRegression API,案例演示了癌症分类预测的完整流程,包括数据预处理、标准化、模型训
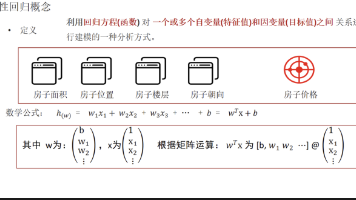
线性回归核心知识点摘要 本文系统介绍了线性回归的核心概念与应用。主要内容包括: 基础概念:定义线性回归模型,区分一元与多元线性回归,列举典型应用场景如房价预测等。 实践应用:通过身高预测体重的案例演示Sklearn API使用流程,包括数据准备、模型训练、参数查看和预测。 数学原理:解析线性回归四大要素(数据、模型、损失函数、优化方法),详细介绍导数、偏导数、矩阵运算等数学基础。 求解方法:对比正
KNN算法是一种基于距离度量的简单机器学习方法,核心思想是通过计算样本与K个最近邻居的距离进行分类(多数表决)或回归(平均值)。算法流程包括距离计算、排序、选取K个邻居和决策。常用距离度量有欧氏、曼哈顿和切比雪夫距离。K值选择对模型性能影响大,可通过网格搜索和交叉验证调优。特征预处理(归一化/标准化)是关键步骤,标准化更推荐。sklearn提供KNeighborsClassifier和KNeigh

AI → ML → DL 是包含关系学习方式分:规则学习、模型学习核心术语:样本、特征、标签、训练集 / 测试集四大算法:监督、无监督、半监督、强化学习建模六步:数据→处理→特征→训练→评估→上线特征工程决定模型上限欠拟合(太简单)、过拟合(太复杂)开发工具:scikit-learnAI的目标 → 用ML的方法实现 → 按数据类型选学习方式(监督/无监督等) → 按流水线建模(数据→特征→训练→评
