




- @zuochang_liu
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
distinct算子原理:贴上spark源码:/*** Return a new RDD containing the distinct elements in this RDD.*/def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope ...
参考自:http://spark.apache.org/docs/latest/running-on-yarn.html#preparations在spark on yarn模式下,/usr/local/spark-current2.3/conf下的spark-defaults.conf配置文件有一个spark.yarn.archive配置项1.如果没有配置#spark.yarn.a...
{"job": {"setting": {"speed": {"channel": 1},"errorLimit": {"record": 0,"percentage": 0.02}},"content": [{"reader": {"name": "oraclereader","pa...
http://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.VarianceThreshold.html1.特征选择原因冗余:部分特征的相关度高,容易消耗计算性能噪声:部分特征对预测结果有负影响2.什么是特征选择特征选择就是单纯地从提取到的所有特征中选择部分特征作为训练集特征, 特征在选...
Traceback (most recent call last):File "pg2drg2pg.py", line 259, in post2DrgAndGetSqldata = json.dumps(i_params)File "/usr/local/python3/lib/python3.6/json/__init__.py", line 231, in dumps...
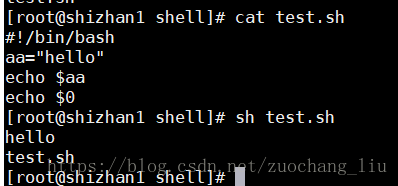
目录1 shell介绍1.1 什么是shell1.2 shell脚本的执行方式2 shell中的变量2.1 系统变量2.2定义变量2.3 将命令的返回值赋给变量2.4 特殊变量3 运算符4 流程控制4.1 for循环4.2 while循环4.3 case4.4 if判断4.5 常用判断条件5 read命令6 shell自定...
目录一 Scala概述1.1 什么是scala1.2 为什么要学scala1.3 Spark函数式编程初体验二 Scala开发环境2.1 安装JDK2.2 安装Scala2.2.1 Windows安装Scala编译器2.2.2 Linux中安装Scala编译器2.3 IDEA安装2.4 Scala插件离线安装2.5 IDEA创建Scala工程...
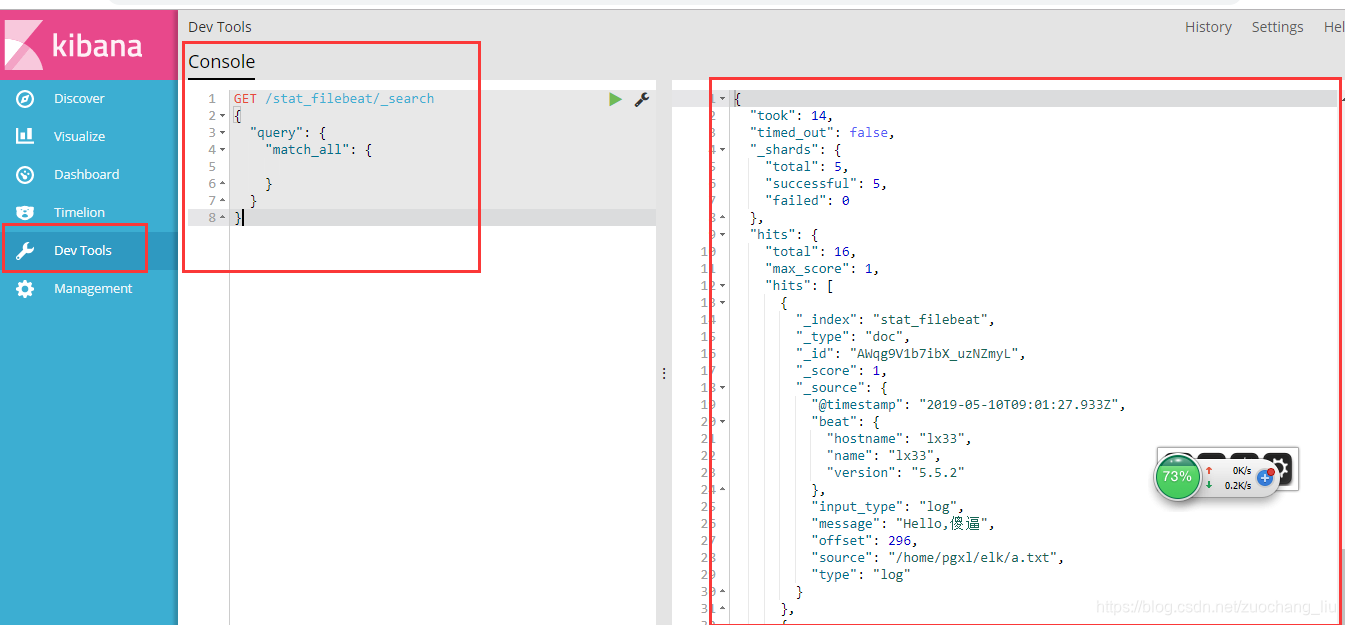
日志采集的工具有很多种,如logagent, flume, logstash,betas等等。首先要知道为什么要使用filebeat呢?因为logstash是jvm跑的,资源消耗比较大,启动一个logstash就需要消耗500M左右的内存,而filebeat只需要10来M内存资源。常用的ELK日志采集方案中,大部分的做法就是将所有节点的日志内容通过filebeat送到kafka消息队列,然后使用l
1.sklearn降维APIsklearn. decomposition2.PCA本质:PCA是一种分析、简化数据集的技术目的:是数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息。作用:可以削减回归分析或者聚类分析中特征的数量3.通过公式计算4.PCA语法# coding=utf-8_author_ = 'liuzc'from sklear...