




- @zjkpy_5
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
使用本地下载的 embedding 模型去做 embedding,然后从中查相似的。
-gpu-memory-utilization 0.2gpu 显存占用,如果太高,我最开始 0.98,调用会崩掉。--max_model_len 4096 模型能够处理的最大序列长度(以token为单位),显存不够报错了,可以调小。"temperature": 0.7, 生成文本的随机性,值越小,创造能力越强,输出更加多样,适合创造场景。),会降低之前已经出现在生成文本中的词语被再次选中的概率。-

使用最新的 langchain langgraph v1.0 版本实现多轮对话,会话历史存储,长期记忆存储,记忆检索,使用 sqlite 进行实现。
在公司有大模型可以通过 api 方式调用,想使用 langchain 框架调用,langchina 已经封装好大部分模型了,但自己公司的模型不支持,想使用,相当于自定义模型。generations_text:自定义方法,也就是调用自己公司api逻辑的代码,可以这样理解,这里我是演示,调用通义的代码是从官网扣下来的。由于这里是演示,所以假如我公司的模型的通义,langchain又不支持,我需要自定义
室外计算机器与天气搜索引擎,但在使用天气查询的时候好像不可以用了。
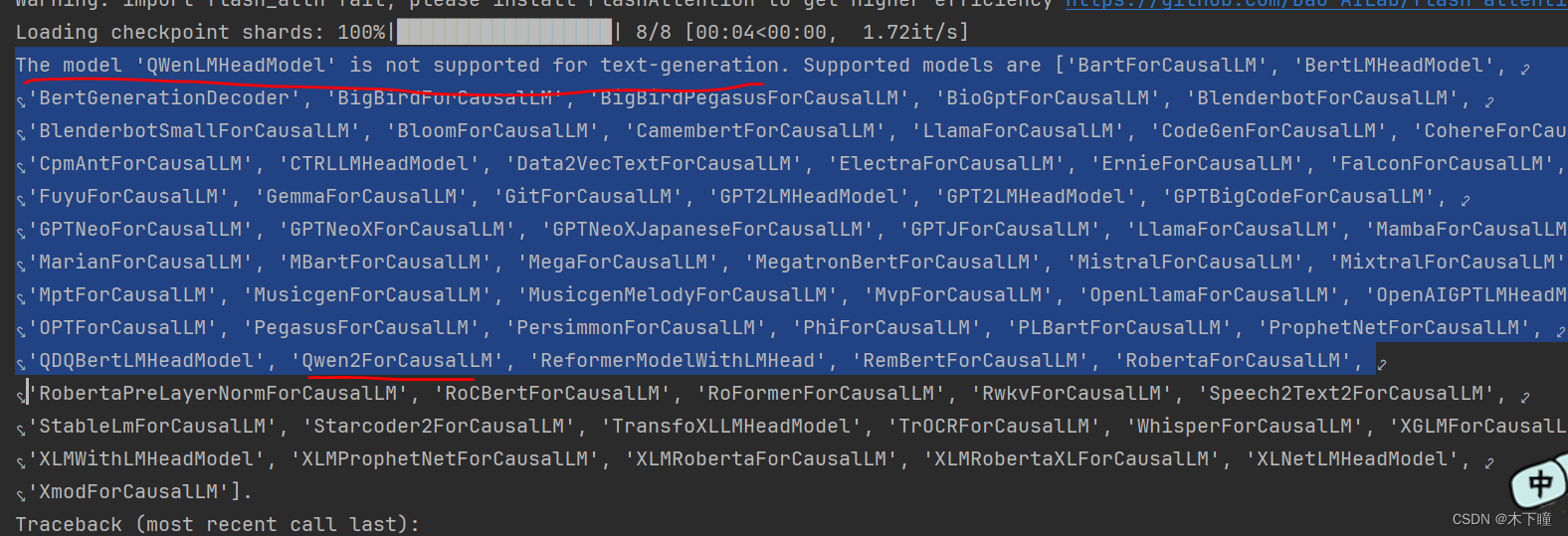
看了下是不支持这中模型,但看列表中有一个 Qwen 字样,想着应该是支持的,就去 hugging face 搜了下这个东西 “Qwen2”找到了对应的 qwen1.5-7B-Chat 模型。其实也就是一种公测版本,,所以总结来说目前直接导入本地 通义千问 langchaing 支持不是很好,可以使用 ollama,但这个下载非常慢,还会失败。qwen1.5-7B-Chat 我们用这个模型,是可以加
langchain 中提供了内置工具的,但是基本不能用,除了一个计算器和一个执行 python 代码的,其他的都要 apiTool 模块相当于是使用外部工具,或者自定义工具。
之前我曾开发过微博词条工作流的爬虫工具,但该工具仅支持命令行操作,且需要编写代码,对于非编程背景的用户来说操作较为复杂。该应用具备直观的UI界面,用户只需输入词条和cookie信息,即可轻松实现微博数据的爬取、分析与词云绘制,操作便捷、高效。恭喜你发现了一个宝藏公众号!关注我,带你一起飞!这里有实用干货、有趣故事,快来关注,让我们一起成为更好的自己!这个应用使用扣子平台搭建,爬取的数据保存到个人飞
看了下是不支持这中模型,但看列表中有一个 Qwen 字样,想着应该是支持的,就去 hugging face 搜了下这个东西 “Qwen2”找到了对应的 qwen1.5-7B-Chat 模型。其实也就是一种公测版本,,所以总结来说目前直接导入本地 通义千问 langchaing 支持不是很好,可以使用 ollama,但这个下载非常慢,还会失败。qwen1.5-7B-Chat 我们用这个模型,是可以加
-gpu-memory-utilization 0.2gpu 显存占用,如果太高,我最开始 0.98,调用会崩掉。--max_model_len 4096 模型能够处理的最大序列长度(以token为单位),显存不够报错了,可以调小。"temperature": 0.7, 生成文本的随机性,值越小,创造能力越强,输出更加多样,适合创造场景。),会降低之前已经出现在生成文本中的词语被再次选中的概率。-