




- @zhangkaiadl
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
基于 Simon Willison 7 月 2 日发布的 llm-coding-agent,拆解 Claude Code 风格编码 Agent 的核心架构——5 个工具(edit_file、execute_command、list_files、read_file、write_file)加一个 Agent 主循环,附安装配置、三种运行模式(交互/--yolo/--allow 白名单)和踩坑提示。

但如果奖励信号只来自特定工具环境下的表现,模型学到的就不是"如何正确调用工具"这个通用能力,而是"如何在某个特定工具的 API 格式下拿到高分"。新模型在 RL 训练中"背下"了 Claude Code 工具的参数结构,当遇到 Pi 的不同 schema 时,它会不自觉地"补齐"那些在 Claude Code 里存在、但在 Pi 里不存在的字段。Armin 的经历说明,从旧模型升级到新模型,不一定

但如果奖励信号只来自特定工具环境下的表现,模型学到的就不是"如何正确调用工具"这个通用能力,而是"如何在某个特定工具的 API 格式下拿到高分"。新模型在 RL 训练中"背下"了 Claude Code 工具的参数结构,当遇到 Pi 的不同 schema 时,它会不自觉地"补齐"那些在 Claude Code 里存在、但在 Pi 里不存在的字段。Armin 的经历说明,从旧模型升级到新模型,不一定
基于 Simon Willison 7 月 2 日发布的 llm-coding-agent,拆解 Claude Code 风格编码 Agent 的核心架构——5 个工具(edit_file、execute_command、list_files、read_file、write_file)加一个 Agent 主循环,附安装配置、三种运行模式(交互/--yolo/--allow 白名单)和踩坑提示。
基于 Simon Willison 7 月 2 日发布的 llm-coding-agent,拆解 Claude Code 风格编码 Agent 的核心架构——5 个工具(edit_file、execute_command、list_files、read_file、write_file)加一个 Agent 主循环,附安装配置、三种运行模式(交互/--yolo/--allow 白名单)和踩坑提示。
基于 Addy Osmani 最新博文《Agentic Code Review》的思路,从零搭建 AI 驱动的代码审查流水线——Claude Code 作为审查引擎,Git pre-push hook 触发,自动检查安全性、逻辑和风格问题,附完整可运行脚本。
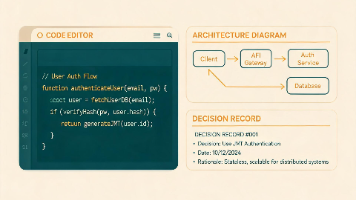
基于 Addy Osmani《The Intent Debt》的概念,用 80 行 Python 脚本 + Git pre-commit hook + Claude Code 搭建自动 ADR(架构决策记录)生成流水线,每次提交自动附带设计意图文档,从源头消除意图债。
在会话末尾告诉 Claude:请用 memory_save 保存本次会话的关键决策和注意事项Stop hook 会自动做合并,但手动触发一次能确保重要信息被标记高优先级。

基于 Greg Slepak(okTurtles 创始人)7 月 2 日发布的《The Short Leash AI Coding Method》,拆解短绳法的核心原则——绝不 YOLO、审查每个 diff、频繁拒绝、AI+人双重审查,给出在 Claude Code 中的完整落地配置和 PR 审查流程。

基于 Greg Slepak(okTurtles 创始人)7 月 2 日发布的《The Short Leash AI Coding Method》,拆解短绳法的核心原则——绝不 YOLO、审查每个 diff、频繁拒绝、AI+人双重审查,给出在 Claude Code 中的完整落地配置和 PR 审查流程。