




- @zcs2312852665
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文围绕 MySQL 索引展开,先介绍索引本质、作用、特点、底层 B + 树结构及适用与不适用场景,再分类说明按功能、物理存储、字段数量划分的索引类型及选择建议。接着提供数据准备的 SQL 脚本,最后详细阐述索引管理操作,包括创建(建表时与建表后)、查看(SHOW INDEX 与 EXPLAIN 分析)、修改(删除旧索引重建新索引)和删除(单索引与批量删除)的语法、参数解释及实操示例,助力优化数据

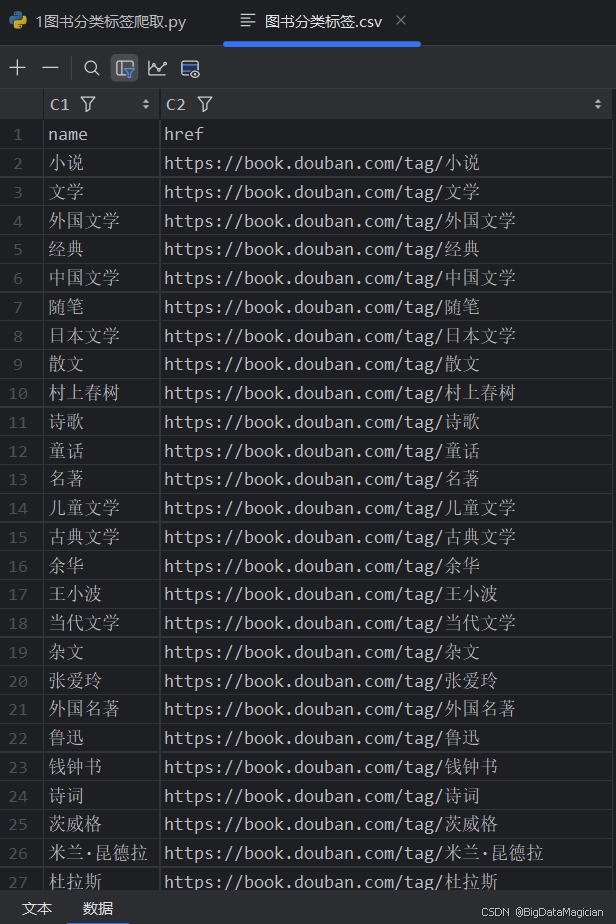
并将这个数据表格保存为一个 CSV 文件,文件名为 “图书分类标签.csv”,存储在 “原始数据层” 文件夹下,保存时不包含索引列,并使用特定的编码格式(utf-8-sig)以确保中文字符的正确保存和读取。将提取到的每个图书分类标签的名称和对应的链接地址,以字典的形式存储,字典的键分别为 ‘name’ 和 ‘href’,值分别为标签名称和链接地址。对于每个选中的链接元素,提取其文本内容作为图书分类
数据库视图实验练习 上机操作题
本文介绍了数据可视化的基本概念与常用图表类型,并总结了Python中主流可视化工具库的特点。数据可视化通过图形化呈现数据规律与趋势,核心流程包括数据读取、图表选择、绘制与保存。常见图表如折线图、柱形图、散点图等各有适用场景,能直观展示趋势、对比、分布等不同数据特征。
数据库视图实验练习 上机操作题
本文首先介绍了find命令的基本语法和常用选项,包括按照名称、类型、修改时间和文件大小进行搜索,以及执行命令和删除文件等操作。接着,我们提供了一些find命令的示例用法,包括搜索指定目录下的文件和目录,按照条件进行搜索,并执行相应的操作。然后,我们介绍了scp命令的基本语法和常用选项,包括从本地复制文件到远程主机和从远程主机复制文件到本地,以及递归复制整个目录等操作。最后,我们给出了一些scp命令

Pyecharts 是一个基于 Python 的开源数据可视化库,依赖 JavaScript 的 ECharts 库,能够生成交互式、高可定制的动态图表。它支持多种图表类型,如折线图、柱状图、地图等,并具备丰富的交互功能。Pyecharts 的优势在于易用性和表现力,能够与 Pandas 等数据处理库结合,适用于数据分析师、开发人员和科研人员。安装 Pyecharts 可通过 pip 命令完成。
本文介绍了awk命令的基本概念、语法和常用选项。awk是一种文本处理工具,可以用于从文本文件中提取和处理数据。它通过逐行读取文件并根据指定的规则执行操作来实现功能。
sort命令是一个用于对文本文件进行排序的常用工具。它可以按照指定的排序规则对文件中的行进行排序,并输出排序后的结果。本文将介绍sort命令的基本语法和常用选项,帮助读者了解如何使用sort命令来对文本文件进行排序。sort命令是一个用于对文本文件进行排序的工具。它可以按照指定的排序规则对文件中的行进行排序,并输出排序后的结果。sort命令默认按照字典顺序对文本行进行排序,但也可以根据需要进行自定

uniq命令是一个强大的文本处理工具,可以帮助我们快速删除重复行、统计行数以及进行排序等操作。通过灵活运用uniq命令的不同选项,我们可以根据需求对文本数据进行精确的处理和分析。以上是对uniq命令的简要介绍和常用选项的说明,希望本文能够帮助读者更好地理解和使用该命令。更多详细信息和其他选项,请参考uniq命令的官方文档或使用man uniq命令查看帮助文档。
