- @ym1593572486
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
ECCV 机器人研究是当下智能装备领域的颠覆性进展,它整合了计算机视觉与自主控制的精髓,攻克了传统机器人在复杂环境中感知滞后、决策僵化的难题,达成了精度与适应性的同步飞跃机器人这一领域不仅在工业制造、服务医疗等诸多场景中大显身手,在各大顶会顶刊的录用率也居高不下,简直是学术圈的 “热门焦点”!特别适合想产出高水平论文、推动技术落地的研究者。
当人工智能跨越单一模态的局限,融合文本、图像、音频、视频等多维度数据时,一场认知革命正在发生。在未来,多模态大模型将向更人性化、泛在化的智能跃迁,轻量化架构推动端侧普及,量子计算或从根本上突破算力瓶颈,而人形机器人的实用拐点、脑机接口的模态扩展,更将打开AGI时代人与AI协同进化的新维度。
多模态是一种融合文本、图像、音频、视频等异构数据形式进行智能处理的技术范式,通过整合不同感官模态的信息,模仿人类多维度认知世界的方式,旨在构建更完整、准确且贴近真实场景的智能系统。目前,多模态技术已深度渗透至生成式 AI、工业质检、医疗影像诊断、智慧教育等领域,展现出融合创新驱动通用人工智能发展的巨大潜力。
多模态融合正迎来技术与应用的双重爆发,从视觉+语言到语音+传感器,各种模态的组合不断涌现新玩法。随着跨模态对齐、轻量化建模和任务协同优化等方法的快速演进,学术界不断刷新SOTA,产业界也在医疗、自动驾驶、AIGC等场景大规模落地。CVPR 2025的赛场上,这一领域无疑将继续成为焦点,谁能抓住下一个突破口,谁就能定义多模态的未来。
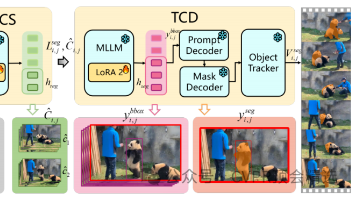
多模态技术指融合视觉、听觉、文本等异构信息以增强机器对复杂场景的理解与生成能力,其核心在于跨模态对齐与协同推理。作为CVPR的前沿热点,多模态模型通过扩散算法、动态梯度优化及统一学习框架显著提升跨模态任务的泛化性与可控性。多模态的发展正深刻重塑影视制作、人机交互及具身智能等领域——例如动态神经辐射场实现电影级视频编辑,视听语义手势合成技术推动人形机器人自然交互,未来将加速通用人工智能的演进,实现跨

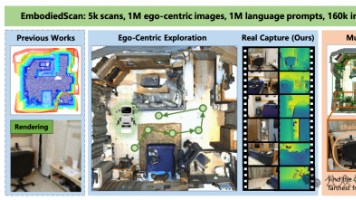
具身智能作为人工智能的重要分支,近年来在CVPR等国际顶级会议上受到广泛关注。其背景源于对自主智能体在复杂物理环境中感知、推理与行动能力的需求。目前,具身智能在单臂系统和双臂协作系统等方面取得了显著进展,但仍面临多模态信息融合、跨场景泛化等挑战。未来,具身智能有望在适应性与增量学习、多模态感知融合等方面取得突破,推动其向通用人工智能迈进,为机器人技术的发展带来新的机遇。
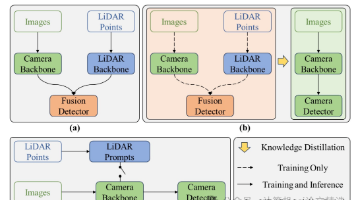
在人工智能领域,3D技术作为关键研究方向,近年来通过多模态融合、生成模型与无监督学习等创新实现显著突破。AAAI 2025提出的MSP-MVS方法通过多粒度分割先验解决了弱纹理区域的3D重建难题,大幅提升深度估计精度。3D技术其未来前景聚焦在技术深化和应用扩展两个方面,同时正从算法创新迈向跨领域赋能,成为驱动产业智能化升级的核心引擎。
医学图像分析在疾病诊断与治疗规划中发挥着关键作用,但其面临多模态差异显著、标注数据稀疏、复杂解剖结构建模困难等核心挑战。现有方法在处理多源异构数据时,常受限于模态特异性特征难以融合、模型泛化性不足等问题 。对于不同目标的研究者,创新路径可灵活选择:若想快速产出成果,可聚焦架构创新并在特定场景验证;若瞄准高区论文,则可深耕高效训练策略,为医学图像的通用化建模提供理论支撑。
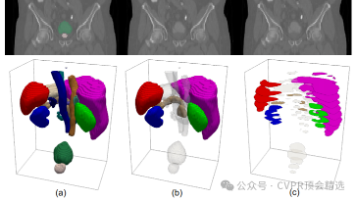
文章首先利用知识蒸馏技术,充分挖掘原始SAM大模型的表征能力,引导小模型学习关键特征表达。接着,通过灵活的量化策略,将模型权重和计算过程压缩至低比特,实现资源占用极小化。最后,结合优化的轻量解码器以及端到端训练,使TinySAM能在多种实际场景下以极低算力完成高精度分割任务,兼顾速度与准确率。
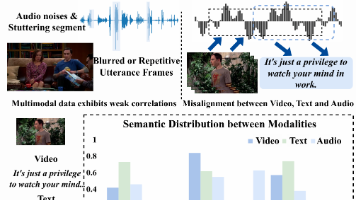
多模态正成为AI科研的前沿方向,它通过融合视觉、语言、语音等多源信息,打破单一模态的局限,推动模型更接近人类智能。近年来,从基础大模型到跨模态应用,多模态已成为顶会热点。而在市场层面,无论是智能医疗、自动驾驶还是人机交互,企业都在加速布局,产业价值潜力巨大,未来或将引领新一轮AI革命。