- @ylguoguo6666
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
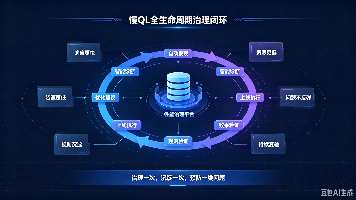
本文探讨了慢SQL治理的最后一公里问题,强调优化上线不等于治理结束。文章提出了全生命周期治理的三个关键环节:效果验证(通过多维指标自动对比、异常预警和持续跟踪确保优化效果)、闭环沉淀(将治理经验转化为SQL审核规则实现源头预防)以及长效运营(建立分级治理机制和可视化治理大盘)。这套体系将原本依赖个人经验的治理转变为标准化流程,通过持续验证、经验沉淀和定期复盘,实现从"事后治理"
麦聪QuickAPI低代码平台可快速将MySQL数据转为RESTful API,只需编写SQL查询即可生成接口,支持多种数据库和本地部署。操作步骤包括配置数据源、创建API及验证调用,适合企业快速构建数据服务。该方案显著提升开发效率,但需注意安全性和性能优化。
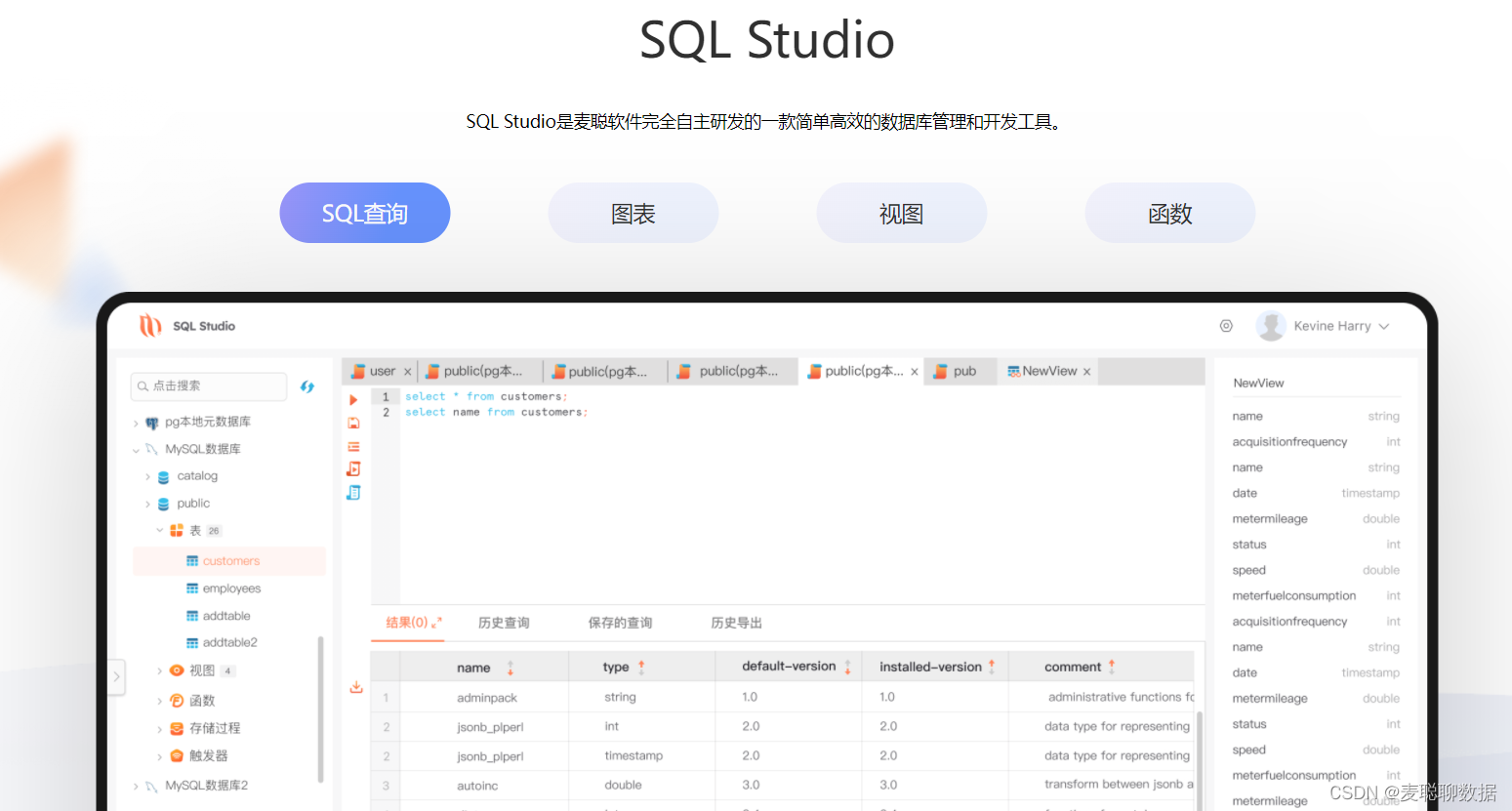
很多国内SQL学习者和开发者对Navicat、DBeaver等国外数据库管理工具已经很熟悉了。但是,有没有比他们更适合SQL开发者的数据库管理/SQL工具呢?这里,笔者结合自己的调研来聊一下。
官网介绍的比较中肯,我直接搬过来了:SQL Studio是一款可创建多个连接的Web版数据库管理开发工具,让你从单一应用程序可同时连接PostgreSQL、MySQL、SQLite、SQL Server、Oracle、DM(达梦)、KingBase(人大金仓)等数据库。主窗口直观完善的图形用户界面和强大的SQL编辑器功能极大简化了大家的数据库管理开发工作,随时随地的团队协作,完整的审计功能,让用户
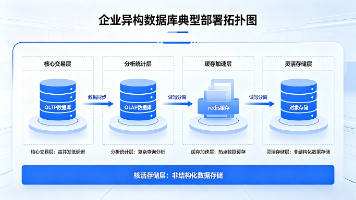
数据架构师在业务环境中进行监督,他们将业务需求转化为技术需求,并为业务提供适当的原则和标准。他负责设计和可视化企业数据框架和管理。因此,该框架解释了计划中的流程,指定、允许、开发、获取、管理、使用、维护、检索、清除和归档数据。他提供标准的业务报表、流程战略需求,表达实现需求的高级集成框架。他与与业务架构相关的分析观点保持一致。数据架构师的角色是开发安全且可访问的复杂数据库系统。它有助于定义数据库的

《SQL2API:云原生时代的数据访问范式演进》摘要 在云原生与微服务架构下,传统ORM模式暴露出计算下推受阻、全链路维护成本高和协议开销大等问题。SQL2API作为应用层协议转换器,通过AST解析、零拷贝反序列化和动态Schema感知等技术,实现了数据库协议到API的直接映射。相比传统ORM,SQL2API在性能、变更成本和简单查询场景中具有显著优势,但不适用于复杂状态逻辑和跨源事务场景。这一技

《异构数据库统一管控的技术挑战与核心解法》摘要 随着企业业务场景不断细分,数据库技术栈呈现多元化发展趋势,"专库专用"架构已成行业标配。然而技术红利背后,分散式运维管理带来四大痛点:多工具切换降低效率、权限体系割裂增加管理成本、审计标准不一导致合规困难、运维标准缺失影响质量。 实现异构数据库统一管控面临四大核心技术难点:1)协议适配与SQL方言兼容,需平衡准确性与功能性;2)权
电商大促期间,数据架构团队面临高并发写入和实时数据查询的双重压力。针对运营人员低效SQL导致数据库崩溃的问题,文章提出"运行时治理"方案:1)通过SQL网关进行AST解析和成本预估,拦截劣质查询;2)采用资源池化和物理隔离机制,保障核心业务优先级;3)实施网关级并发控制和熔断降级。这套主动防御体系将数据库从业务争抢中解放出来,显著提升了数据平台的稳定性,是应对极端流量考验的关键
摘要:SQLynx数据库管理平台通过B/S架构和精细化权限管控,解决了电商行业业务人员直连数据库的三大痛点:1.拦截高危SQL避免生产故障;2.集中配置消除账密泄露风险;3.全链路审计确保数据合规。该方案显著提升了生产稳定性,降低IT运维成本,实现数据流转透明化,为跨部门数据协作提供了安全高效的解决方案。(149字)
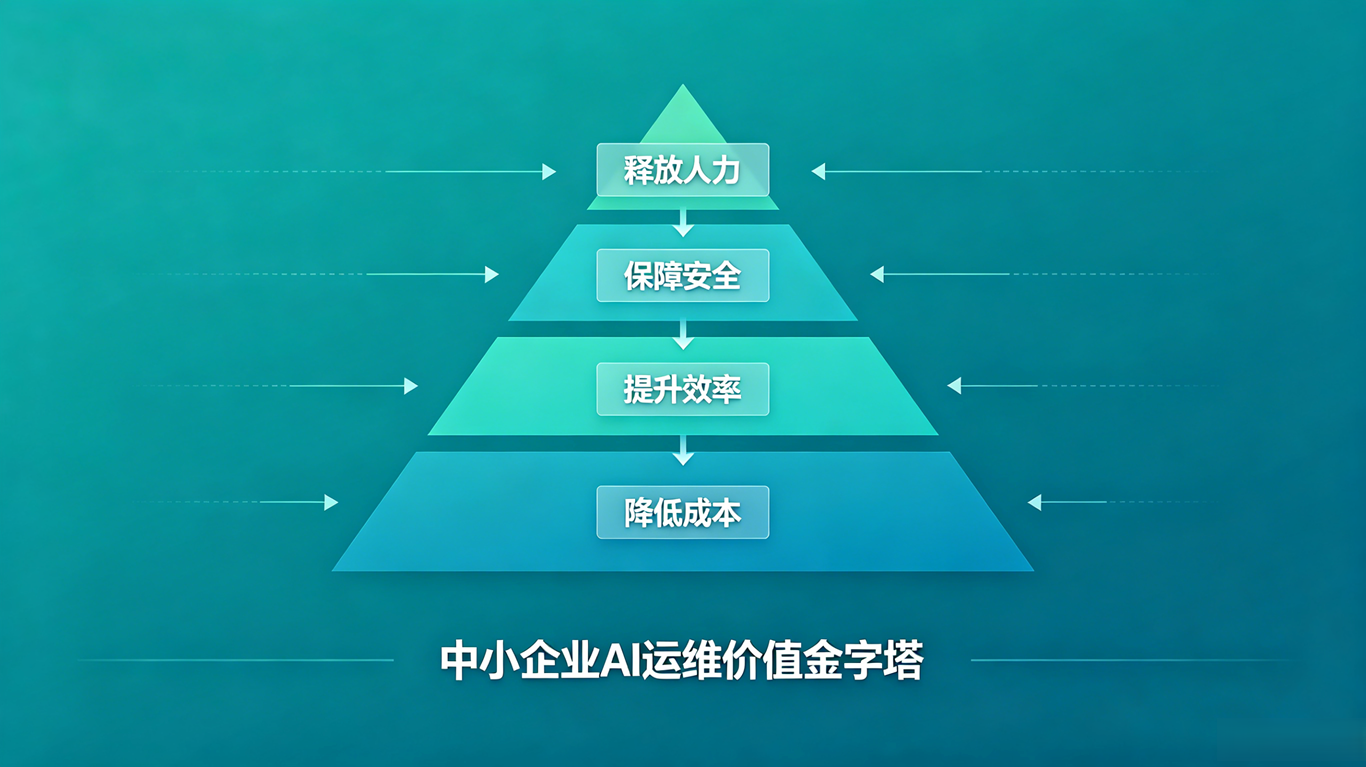
【摘要】本文针对中小企业数据库运维"缺人、缺钱、缺技术"三大困境,提出AI无头代理轻量化解决方案。该技术具有无需额外硬件、开箱即用、按需付费三大优势,支持中小企业低成本实现智能化运维。通过"单点切入-扩展应用-无人值守"三步落地法,某百人科技公司在三个月内实现运维效率提升90%,故障恢复时间从2小时缩短至15分钟。案例证明,AI无头代理能以极低门槛帮助中小企