




- @xuejianxinokok
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍 TorchScript,它是 PyTorch 模型(nn.Module的子类)的中间表示,可以在 C++ 等高性能环境中运行。forward我们希望在您完成本教程后,您将继续 学习,该教程将引导您了解从 C++ 实际调用 TorchScript 模型的示例。

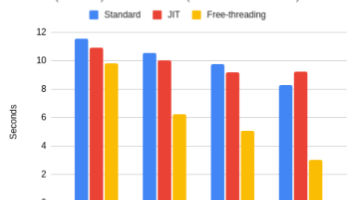
Python 3.14性能测试报告:新版本带来显著提速 本文对Python 3.14进行了性能基准测试,重点比较了不同版本Python在斐波那契数列计算和冒泡排序上的表现。测试结果显示,Python 3.14相比3.13版本提速约27%,比早期版本提升更为明显(3.11是性能转折点)。Pypy 3.11表现优异,比Python 3.14快5倍,而Rust则以近70倍的优势遥遥领先。 测试还考察了P
易于学习、快速、适合 Web 服务丰富的内置功能。我们仅使用标准库就做了很多事情。例如,我们不需要添加模板引擎或单独的身份验证库。我们唯一的外部依赖项是Gin和sqlx快速、安全、不断发展的网络服务生态系统内置功能较少。我们必须添加大量依赖项才能获得与 Go 中相同的功能并编写我们自己的小型中间件。最终的处理程序代码没有分散注意力的错误处理,因为我们使用了自己的错误类型和?运算符。这使得代码非常可

复制拓扑1. 软件版本操作系统: window 7数据库: Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit ProductionOracle GoldenGate 12.3.0.1.5 for Oracle on Windows 64 bit.zipOracle GoldenGate for Big Data 12
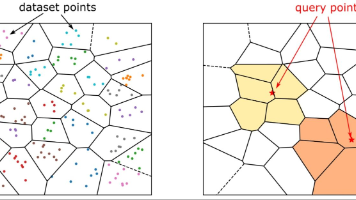
pgvector在生产环境中的实践困境:理想与现实差距显著。现有技术文档普遍只展示本地小规模测试,却忽略了关键生产问题:索引选择上,IVFFlat存在聚类失衡问题,HNSW则面临高内存消耗和构建耗时;实时搜索场景中,新数据插入与索引维护存在根本性冲突,导致必须采用离线构建、双索引等复杂方案;查询过滤面临预过滤与后过滤的两难选择,既要保证结果质量又要兼顾性能。这些未充分讨论的痛点表明,pgvecto
Rust 的 trait 相比传统 OOP 具有 7 个核心优势:1)支持同类型约束(如 Eq),避免非法运算;2)基于"能力"而非"身份"进行抽象;3)消除菱形继承问题;4)支持对第三方类型进行扩展;5)默认静态分发实现零运行时成本;6)通过类型系统使非法状态不可表示;7)更贴近数学抽象,适合构建通用库。其本质突破在于:trait 通过编译期验证精确约束类
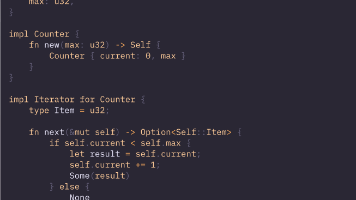
本文深入探讨了Rust中的迭代器机制,重点介绍了其惰性求值和可组合性的特点。文章详细讲解了Iterator trait的核心原理、三种创建迭代器的方法(iter()、into_iter()、iter_mut())以及转换(map/filter)、消费(collect/fold)和重塑(step_by/rev/enumerate/zip)迭代器的多种操作方式。通过具体示例展示了如何实现自定义迭代器,
从顶点着色器开始,因为 GPU 也将从这里开始!顶点着色器被定义为函数,GPU 会针对中的每个顶点调用一次该函数。由于包含六个位置(顶点),因此您定义的函数会被调用六次。每次调用该方法时,都会将中的其他位置作为参数传递给该函数,顶点着色器函数的作用是在裁剪空间中返回对应的位置。也务必要理解,系统不一定会按顺序调用它们。相反,GPU 擅长并行运行上述着色器,这可能会同时处理数百(甚至数千!)顶点!G

利用 Tokio、Tower 和 Hyper 建立强大的生态系统。很棒的开发者经验。仍处于 0.x 版本,因此可能会发生重大更改。强大、独立的生态系统。通过主要版本保证实现稳定的 API。很棒的文档。丰富的内置功能。不像以前那样积极发展。对于初学者来说仍然是一个不错的选择。Functional approach. 函数式方法。Very expressive. 非常富有表现力。靠近 Tokio、To

有许多库可以在 Rust 中输出日志,有时很难选择该使用哪一个。当println!dbg!和eprintln!无法解决问题时,找到一种方便记录日志的方法就很重要,尤其是在生产级应用程序中。本文将帮助您深入了解在 Rust 日志记录方面最适合您的用例的日志 crate。
