
写文章




- @ww596520206
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
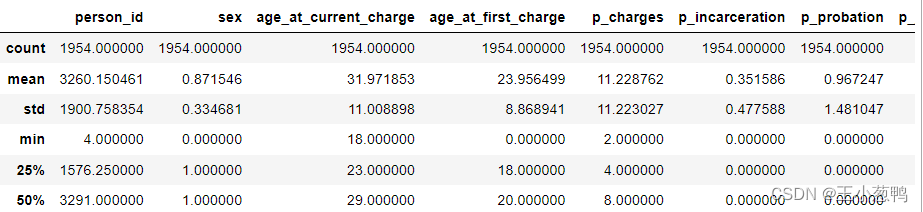
基于Broward犯罪数据集机器学习分类
包含详细的数据分析,数据可视化、特征处理、机器学习模型分类。
基于计算机视觉的坑洼道路检测和识别-MathorCup A(深度学习版本)
赛道 A:基于计算机视觉的坑洼道路检测和识别使用深度学习模型,pytorch版本进行图像训练和预测,使用ResNet50模型。

基于yolov8-paddleocr-车牌识别
使用yolov8模型进行车牌区域识别,然后使用paddlecor模型将字体提取出来,由于数据量很大,支持复杂环境下的识别。数据集共29642张,其中27642张用了做训练,2000张用来做验证。


利用reddit的api进行爬虫
Reddit是一个社交新闻聚合网站,用户可以发布、评价和讨论各种话题。Reddit的内容涵盖了广泛的主题,可以从中获取大量的文本数据进行情绪分析。

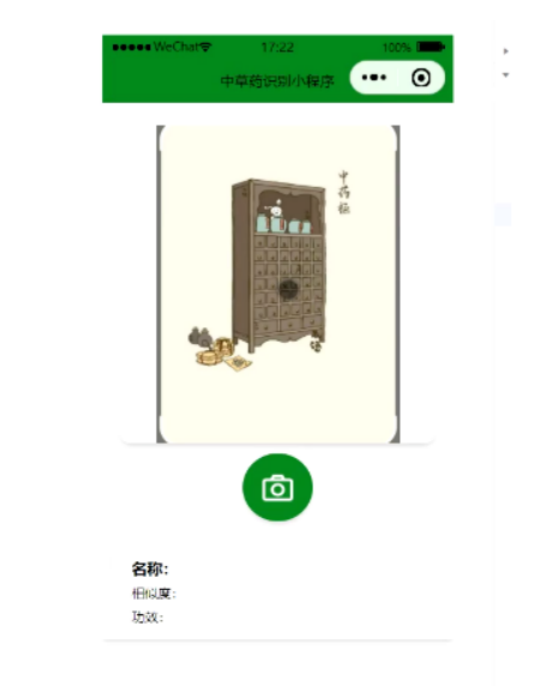
毕设--基于深度学习的中草药识别【子木工作室】
我们开发了一款基于深度学习的中草药识别小程序,基于restnet50模型。
使用paddlerocr识别固定颜色验证码
本文使用opencv和paddlerocr识别出固定颜色的验证码

基于Broward犯罪数据集机器学习分类
包含详细的数据分析,数据可视化、特征处理、机器学习模型分类。
基于yolov8-paddleocr-车牌识别
使用yolov8模型进行车牌区域识别,然后使用paddlecor模型将字体提取出来,由于数据量很大,支持复杂环境下的识别。数据集共29642张,其中27642张用了做训练,2000张用来做验证。
Python实现基于LDA的文本主题分析与情感分析
摘要:本文介绍了一个基于Python开发的文本分析系统,采用LDA主题模型和情感分析技术对中文文本进行处理。系统包含数据预处理、主题分析、情感分析和可视化四大模块,支持中文分词、停用词过滤、主题词提取和情感得分计算等功能。通过jieba分词、SnowNLP等工具实现中文文本处理,并生成词云图等可视化结果。系统采用模块化设计,具有完整性、易用性和可扩展性特点,为用户提供了从数据预处理到结果展示的完整
