




- @weixin_65875490
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
集成学习是「多模型组合作战」的思路,核心价值是高精度、高稳定,工作中重点掌握随机森林(入门)和XGBoost(落地),调参只记3个核心参数,不用做复杂特征预处理,比单棵基础模型更靠谱;它不是“万能的”,但却是程序员从“原型验证”到“正式落地”的首选方案,和前3种基础算法互补,根据需求(速度、精度、可解释性)选型,就能高效落地机器学习需求。
逻辑回归的核心是 “线性得分 + 概率映射”,工作中记住 3 点:① 预处理必须做特征缩放和编码;② 用精确率 / 召回率 / F1 评估(别只看准确率);③ 类别不平衡用调整。它是入门分类算法的 “基石”,也是面试和业务落地中最常被问到、用到的算法之一,一定要吃透!
L1正则化:删特征,适合“特征多、噪音多”的场景;L2正则化:缩系数,适合“特征都有用、怕过拟合”的场景;弹性网:两者结合,适合“特征多且高度相关”的场景。正则化的核心逻辑很简单:通过“惩罚”模型的复杂程度,逼着模型学习数据的核心规律,而不是死记硬背噪音。记住3个核心方法的适用场景,再结合实战技巧,就能轻松用正则化提升模型的泛化能力。如果你的项目中遇到了过拟合问题,不妨试着用今天的代码和思路调一调
建模流程是 “骨架”,保证步骤不出错;特征工程是 “血肉”,决定模型效果。新手不用一开始就追求复杂模型,把数据清洗和特征选择做好,往往能得到超出预期的结果。
高性能:基于Starlette和Pydantic,性能媲美NodeJS和开发效率:自动生成交互式文档,减少开发时间类型安全:基于Python类型提示,减少约40%的错误异步支持:原生支持异步编程,适合高并发场景标准化:基于OpenAPI和JSON Schema标准。
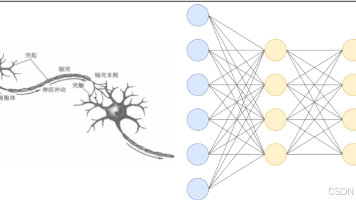
深度学习是机器学习的一个分支,核心是用 “多层神经网络” 模仿人脑神经元的工作方式,让计算机从大量数据里自动学规律,不用人工手动设置规则。简单说,人脑靠神经元相互传递信号处理信息,深度学习就用 “人工神经元”(软件模块)搭成网络,通过数值计算传递信息,给它喂足够多数据,它就能自己学会识别图片、理解语言这些复杂任务。
适合复杂结构(比如多分支、特殊逻辑),需要手动定义层和数据流向。步骤:继承,在__init__里定义各层(比如全连接层、激活层),并初始化权重(比如 Xavier 适配 Tanh,He 适配 ReLU)。在forward里写数据传播路径:输入→第一层→激活函数→第二层→...→输出。优势:想怎么改就怎么改,支持各种复杂逻辑。第1个隐藏层:使用Xavier 正态分布初始化权重,激活函数使用 Tanh

1.在数据库连接编辑设置里的‘’ 选项设置的命令参数框增加。
本文基于LangChain官方文档,系统介绍了10种AI聊天前端开发的核心模式。主要内容包括:1)Markdown消息流式渲染,实现富文本实时展示;2)工具调用可视化,支持加载/成功/失败三种状态;3)人机协同审批流程,确保高危操作安全执行;4)分支对话管理,支持消息编辑和版本回溯;5)推理过程可视化,增强AI决策透明度;6)结构化输出渲染,直接映射为定制UI组件;7)消息队列处理,支持批量发送和
我们需要让节点之间共享信息。最简单的状态就是一个字典。# 定义状态结构messages: list # 所有的对话历史code: str # 生成的代码output: str # 代码执行结果error: str # 错误信息attempts: int # 当前重试次数coder_node: 负责写/改代码。: 负责执行代码并记录结果。# 初始化模型"""根据当前状态生成或修复代码"""# 如果是