
写文章




- @weixin_64261178
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
开源项目有哪些机遇与挑战?
在当今技术迅猛发展的时代,开源项目已经成为软件开发的重要组成部分。无论是初创公司、大型企业还是个人开发者,开源项目都提供了前所未有的机会。然而,开源项目的蓬勃发展也带来了许多挑战。本文将探讨开源项目的机遇与挑战,并探讨如何有效地利用这些机遇和应对这些挑战。

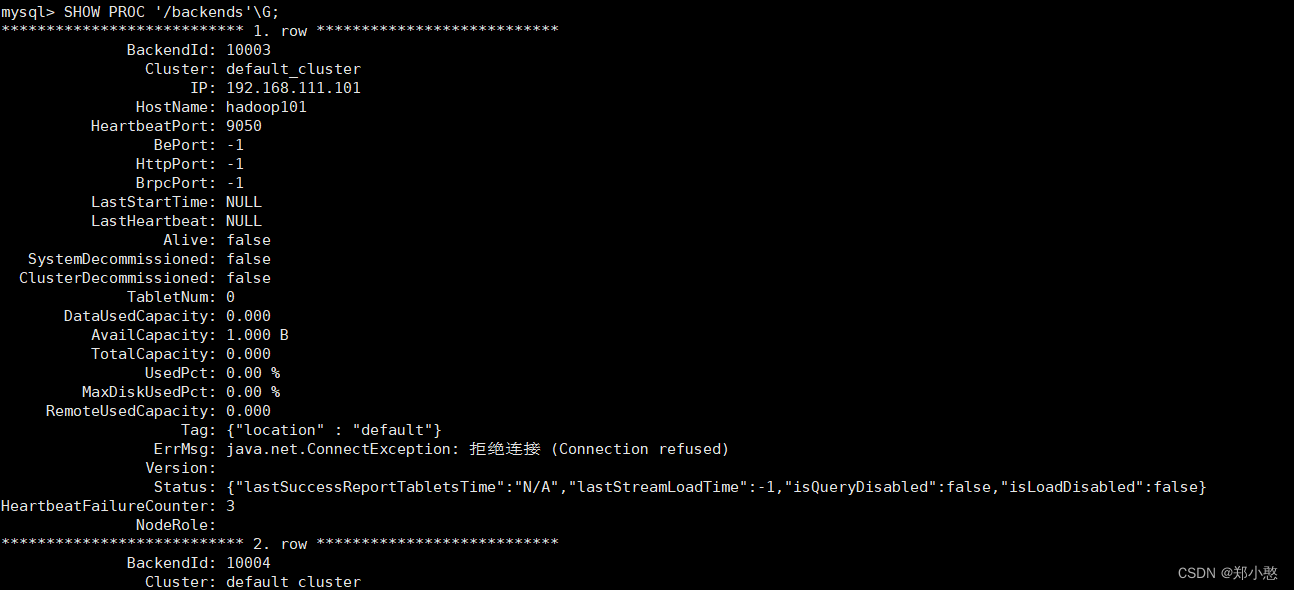
doris 启动be报错
报错:./start_be.sh: 行 325: 11605 段错误 ${LIMIT:+${LIMIT}} "${DORIS_HOME}/lib/doris_be" "$@" 2>&1 < /dev/null
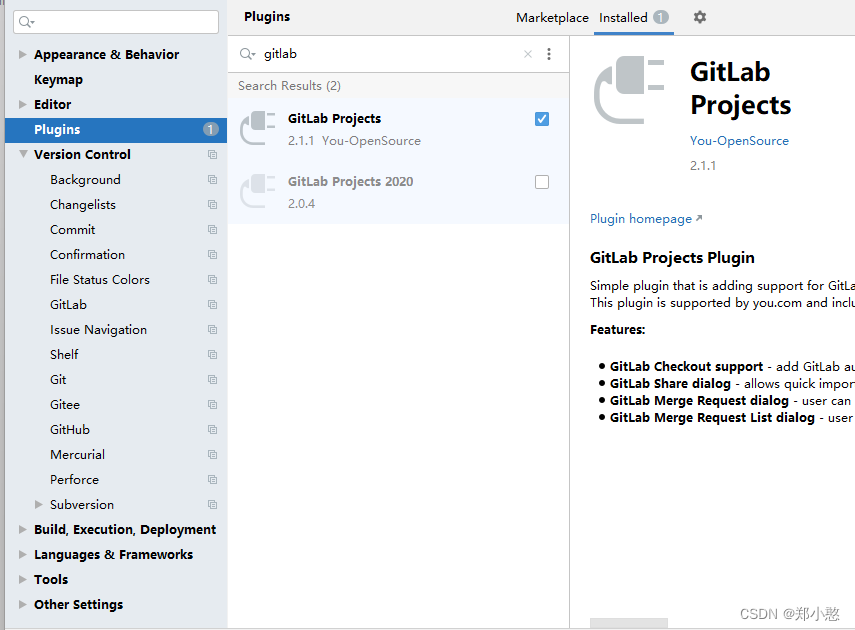
Idea连接GitLab的过程以及创建在gitlab中创建用户和群组
Idea连接GitLab的过程以及在gitlab中创建用户和群组
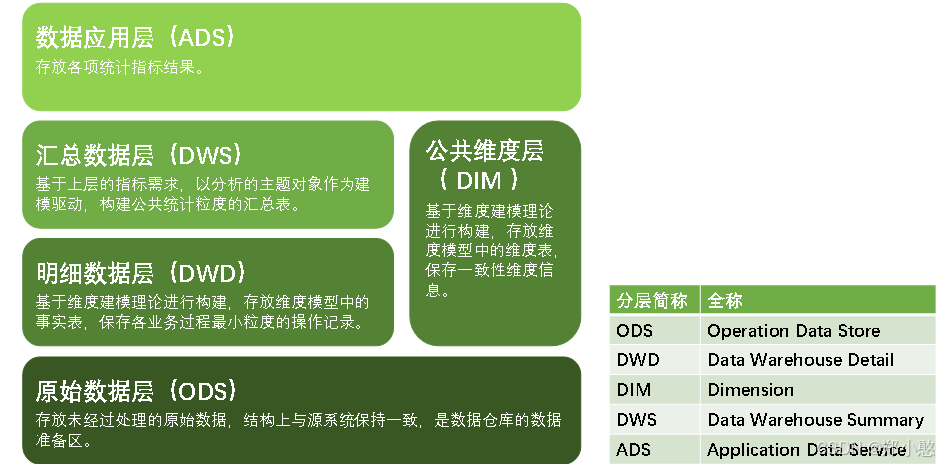
数据仓库介绍_数仓设计 (四)
优秀可靠的数仓体系,需要良好的数据分层结构。合理的分层,能够使数据体系更加清晰,使复杂问题得以简化。以下是该项目的分层规划
数据仓库介绍_数仓介绍(一)
数据仓库是一个为数据分析而设计的企业级数据管理系统。数据仓库可集中、整合多个信息源的大量数据,借助数据仓库的分析能力,企业可从数据中获得宝贵的信息进而改进决策。同时,随着时间的推移,数据仓库中积累的大量历史数据对于数据科学家和业务分析师也是十分宝贵的。数据仓库核心架构系统数据流程图Flink实时数仓数据流程图普通实时计算与实时数仓比较普通的实时计算优先考虑时效性,所以从数据源采集经过实时计算直接得

数据仓库介绍_维度表(三)
维度表是维度建模的基础和灵魂。前文提到,事实表紧紧围绕业务过程进行设计,而维度表则围绕业务过程所处的环境进行设计。维度表主要包含一个主键和各种维度字段,维度字段称为维度属性。

到底了