




- @weixin_61736777
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了当前主流的大模型推理部署框架,包括vLLM、SGLang、TensorRT-LLM、Ollama和XInference。vLLM基于PagedAttention技术实现95%以上的显存利用率;SGLang采用RadixAttention提升多轮对话吞吐量;TensorRT-LLM通过NVIDIA深度优化提供极低延迟;Ollama是轻量级本地推理平台;XInference专注于分布式推理。

本文介绍了当前主流的大模型推理部署框架,包括vLLM、SGLang、TensorRT-LLM、Ollama和XInference。vLLM基于PagedAttention技术实现95%以上的显存利用率;SGLang采用RadixAttention提升多轮对话吞吐量;TensorRT-LLM通过NVIDIA深度优化提供极低延迟;Ollama是轻量级本地推理平台;XInference专注于分布式推理。
本文深入探讨了AI领域的"预训练+微调"技术范式。预训练作为AI的"通识教育",通过Transformer架构等先进技术在大规模数据上学习通用知识,为模型奠定基础能力。文章揭示了预训练的技术奥秘与挑战,包括自注意力机制、海量数据需求和高昂计算成本。微调则使AI成为领域专家,通过参数调整让预训练模型适应特定任务,介绍了全量微调和参数高效微调(如LoRA)等方法

AI 幻觉,听起来有点神秘,其实指的是生成式 AI 在输出内容时,产生一些看似合理,实际却与事实不符、逻辑混乱,或者偏离上下文语义的信息。简单来说,就是 AI “一本正经地胡说八道”。它和人类幻觉有着本质区别。人类幻觉往往是因为精神状态不佳、感官受到刺激、药物影响等因素,导致大脑对现实的感知出现偏差 ,比如一个人在高烧时可能会看到不存在的东西,听到奇怪的声音,这些幻觉大多是主观的、因人而异的,而且

大模型正在从简单的对话功能向金融、医疗和内容创作等专业领域拓展。在金融行业,大模型通过分析多源数据提升风控能力,并优化投资决策;医疗领域,大模型辅助医生诊断和管理医疗数据,提高诊疗效率;内容创作方面,大模型为创作者提供写作灵感和多媒体生成工具。尽管面临数据安全、伦理和原创性等挑战,大模型与区块链、5G等技术的融合将推动更深度的应用创新,重塑各行业发展格局。

大模型推理加速技术综述:量化、剪枝与蒸馏 当前大模型面临计算资源需求大、推理速度慢和能耗高等挑战。本文解析三种核心加速技术:量化通过降低参数精度(如32位→8位)减少计算量;剪枝通过移除冗余参数(结构化/非结构化)实现模型压缩;蒸馏则将大模型知识迁移至小模型。实践案例显示,量化可使模型体积缩小4倍、速度提升50%;剪枝框架LLM-Pruner通过分组剪枝和微调保持性能;蒸馏利用软标签传递知识,显著

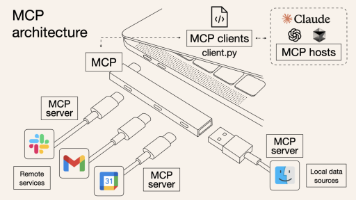
MCP,即 Model Context Protocol,模型上下文协议,是一种专为大模型与外部数据源和工具进行交互而设计的开放标准。简单来说,它就像是一个 “通用插座”,为大模型提供了一个标准化的接口,使得大模型能够轻松连接各种不同的外部资源 ,包括数据库、文件系统、API 接口等。通过 MCP,大模型不再局限于自身预训练的数据范围,能够实时获取和利用更广泛的信息,从而大大拓展了其应用能力和场景
本文深入解析了Transformer和扩散模型这两项推动AI大模型发展的关键技术。Transformer通过自注意力机制和多头注意力,突破了传统RNN/CNN处理序列数据的局限,成为NLP领域基石,并衍生出GPT等强大模型。扩散模型则创新性地采用反向去噪过程生成图像,相比GAN在质量和多样性上表现更优。文章详细剖析了Transformer的编码器-解码器架构、残差连接等核心组件,以及扩散模型的工作

本文系统介绍了大模型的基础知识、核心技术和学习路径。首先将大模型比作AI时代的魔法宝盒,展示了其在语音助手、智能写作等日常场景中的广泛应用。接着解析大模型的核心概念,包括GPT系列等主流模型及其强大的复杂任务处理能力。重点提供了学习大模型的"武功秘籍":夯实机器学习基础理论、研读Transformer架构等经典论文、通过Hugging Face等平台进行实战演练。文章还推荐了《

零基础入门大模型学习的完整指南 本文提供了从零开始学习大模型的系统路径。首先强调大模型作为"新时代魔法棒"在各领域的广泛应用,指出其学习价值。在知识准备方面,建议掌握数学基础、Python编程和机器学习原理;工具方面推荐PyTorch/TensorFlow框架和数据处理工具。学习方法推荐结合入门书籍、在线课程(如Coursera、B站等)和开源社区(Hugging Face)资