




- @weixin_51692073
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了YOLO26改进中引入的MSHC多尺度异构卷积模块的创新应用。该模块通过方形核与条带核的组合,有效捕捉复杂空间纹理特征,在保持YOLO26原有检测框架的同时增强了特征表达能力。文章详细阐述了模块的数学原理、网络融合位置选择以及在医学图像、工业缺陷检测等场景中的优势。特别强调了该改进具有清晰的理论动机和可解释性,不仅提升了模型性能,更为SCI论文写作提供了完整的"动机-方法-验证
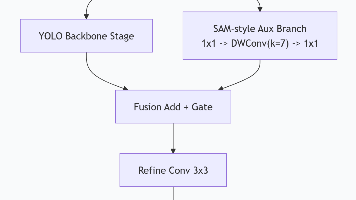
本文提出两种将SAM模型思想融入YOLO26目标检测框架的改进方法:模型A采用YOLO主干+SAM辅助分支的双主干结构,通过大核深度卷积增强空间上下文感知;模型B通过轻量适配器将SAM特征注入YOLO主干,以残差方式实现特征融合。两种方法均能提升模型对复杂边界和细粒度区域的检测能力,其中模型A侧重精度提升,模型B更注重保持推理速度。文章详细阐述了模块设计原理、结构图和参数配置,并提供了调优建议和性
本文提出将CVPR 2024 StarNet的核心思想迁移到YOLO26目标检测框架中,通过乘性特征交互提升轻量检测器的表达能力。StarNet利用逐元素乘法实现隐式高维特征映射,在不增加复杂结构的情况下获得丰富的二阶交互特征。针对检测任务特点,本文重构了StarStem、StarDown和StarBlock模块,保留YOLO26多尺度检测路径的同时引入乘性表达,并采用渐进式残差连接确保训练稳定性
本文提出一种基于HVI颜色空间的低照度图像增强方法HVIEnhanceStem,并将其融合到YOLO26目标检测框架中。该方法通过将RGB图像转换为包含水平、垂直和亮度信息的HVI颜色空间,有效缓解了传统颜色空间在暗光增强中的噪声和伪影问题。在YOLO26中,HVIEnhanceStem模块被部署在Backbone的首层Stem位置,通过并联RGB和HVI分支实现特征增强。实验表明,该方法在不改变
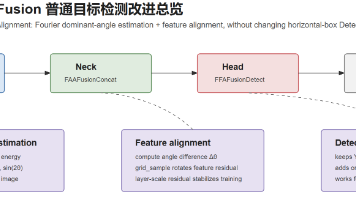
本文提出了一种基于傅里叶角度对齐(FAA)的YOLO26改进方法,通过将CVPR2026的FAAFusion技术迁移到目标检测任务中。该方法在Backbone、Neck和Head三个关键模块引入傅里叶主方向估计与特征对齐机制,显著提升了模型对方向变化的鲁棒性。具体改进包括:在Neck中使用FAAFusionConcat替代普通Concat实现多尺度特征对齐;在Backbone关键输出层添加FFAF
SCI写作避坑指南:6步拆解顶刊案例 摘要:本文通过拆解顶刊论文AMSA-YOLO,提出SCI写作6步法:1)选题聚焦审稿人关心的痛点;2)标题清晰体现贡献;3)Introduction递进式引出问题;4)方法部分建立因果链;5)实验构建多维度证据;6)投稿匹配期刊定位。案例显示,好论文需完成"痛点-方法-证据-边界"的闭环论证,而非简单堆砌创新点。特别强调实验设计要包含主指标、专项验证和性能代价
本文提出将轻量级视觉主干网络MicroViTv2与YOLO26目标检测框架融合的创新方案。MicroViTv2结合了CNN的局部特征提取能力和Transformer的全局建模优势,特别适合移动端和边缘计算场景。研究设计了三种融合方法:完整主干替换、主干适配器和局部块替换,在保持YOLO实时检测能力的同时增强模型对遮挡目标、小目标和复杂背景的处理能力。核心创新点在于将MicroViTv2的轻量混合模
本文通过可视化方式解析CNN如何“看见”图像,打破深度学习黑盒认知。核心要点包括:1)图像在模型中转化为三维数字张量;2)卷积运算本质是局部特征的乘加计算;3)CNN层级结构实现从边缘到语义的逐层抽象;4)YOLO通过Backbone-Neck-Head架构完成目标检测。文章提供7天学习路线和实操代码,帮助新手从图像张量、卷积计算到特征可视化和YOLO检测逐步掌握深度学习原理。建议通过打印网络结构

本文介绍了YOLO26检测模型的最新改进DRoRAE深度路由表征融合方法。该方法源自论文《Beyond the Last Layer》,通过深度路由和渐进校正机制,有效聚合多层视觉特征,解决传统方法仅使用最后一层特征导致的信息丢失问题。在YOLO26中,该创新被转化为多专家修正块,放置在P3/P4/P5节点后,实现内容敏感的特征修正。改进后的模型在语义细节协同、纹理处理和小目标检测等方面表现更优,

文章摘要: 本文介绍了将Upsample Anything(UA)的边缘感知上采样技术融入YOLO26检测模型的创新改进方法。UA通过各向异性高斯核实现无需训练的高分辨率特征恢复,解决视觉基础模型因下采样导致的细节丢失问题。在YOLO26中,该技术被优化为颈部(Neck)的边缘感知模块,替换传统最近邻上采样,显著提升小目标边缘对齐和多尺度融合质量。改进后的模型在不增加计算负担的前提下,通过细节补偿
