- @weixin_51422230
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在数据分析领域,数据可视化是指通过图形、图表、地图、仪表盘等形式,将抽象的数字数据转化为直观的视觉表达,以帮助人们更高效地理解数据、发现规律、支持决策的技术和方法。通过原始表格创建的图为普通图表;通过透视表创建的图表为数据透视图;• 基础操作:自动填充、地址引用、条件格式、数据验证• 数据处理:删除重复值,数据替换,填充缺失值,数据排序,数据筛选• 数据提取:字符串,日期,数值,关联表,条件函数•
RMM是从待分词句子的末端开始,也就是从右向左开始匹配扫描,每次取末端m个字作为匹配字段,匹配失败,则去掉匹配字段前面的一个字,继续匹配。双向最大匹配法(Bi-directional Maximum Matching,Bi-MM)是将正向最大匹配法得到的分词结果和逆向最大匹配法得到的结果进行比较,然后按照最大匹配原则,选取词数切分最少的作为结果。正向最大匹配法(Forward Maximum Ma

上完计算机网络的第一节课,所记录的笔记最简单的定义:计算机网络是一些互相连接的、 自主的/自治的(autonomous)计算机的集合。完整的定义:计算机网络是利用通信设备和链路 将分散在不同地点且具有独立功能的多个计算机系统 互连起来,通过网络协议和软件进行数据通信,实现 资源共享的计算机系统的集合。各计算机是独立自主的autonomous,具有各自的操作 系统,其运行不依赖于其他计算机。计算机之

在数据分析领域,数据可视化是指通过图形、图表、地图、仪表盘等形式,将抽象的数字数据转化为直观的视觉表达,以帮助人们更高效地理解数据、发现规律、支持决策的技术和方法。通过原始表格创建的图为普通图表;通过透视表创建的图表为数据透视图;• 基础操作:自动填充、地址引用、条件格式、数据验证• 数据处理:删除重复值,数据替换,填充缺失值,数据排序,数据筛选• 数据提取:字符串,日期,数值,关联表,条件函数•
基于统计的任务范式(Statistical Paradigm in NLP)通常遵循数据驱动的流程,依赖于大量的语料库和统计模型来处理和分析自然语言任务。单词向量化技术是将自然语言中的单词转换为数学向量的过程,这些向量能够捕捉到单词的语义信息。:每个单词表示为一个稀疏的向量,其中向量的维度等于词汇表的大小。:n-gram 是一种基于上下文的文本表示方法,它将文本分割成连续的 n 个词的组合(称为

文章摘要:本文介绍了词性标注在自然语言处理中的重要性,阐述了基于规则和统计模型(如HMM)的标注方法,并对比了北大和宾州两种主流标注标准。重点讲解了Jieba库的词性标注实现原理,包括词典匹配和HMM模型的结合应用,并提供了Python代码示例展示Jieba的实际标注效果。文章还指出在专业领域文本处理中,基于规则的方法仍具有独特价值。

摘要: 自然语言处理(NLP)经历了五个主要发展阶段:1)50-80年代的基于规则系统,依赖专家手工编写语言规则;2)90年代至2000年代的统计方法,使用概率模型和统计学习处理文本;3)2010年起的深度学习阶段,神经网络自动学习语言特征;4)2018年后的预训练模型时代,通过大规模预训练+微调范式实现任务迁移;5)2020年后的提示工程,通过设计提示词激活大模型能力。这一演变过程反映了NLP从

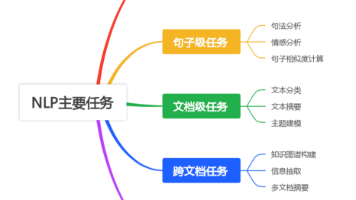
《NLP技术概述与应用全景》 自然语言处理(NLP)作为人工智能的核心领域,致力于实现人机间的自然语言交互。本文系统介绍了NLP的多层级任务体系:词级层面包含分词、词性标注和实体识别等基础处理;句子层面涉及句法分析和情感分析;文档层面涵盖文本分类、摘要和信息检索;跨文档任务则包括知识图谱构建和多文档摘要。此外,文章还探讨了对话系统、机器翻译和文本生成等高级应用。通过丰富的示例(如中文分词"
在数据分析领域,数据可视化是指通过图形、图表、地图、仪表盘等形式,将抽象的数字数据转化为直观的视觉表达,以帮助人们更高效地理解数据、发现规律、支持决策的技术和方法。通过原始表格创建的图为普通图表;通过透视表创建的图表为数据透视图;• 基础操作:自动填充、地址引用、条件格式、数据验证• 数据处理:删除重复值,数据替换,填充缺失值,数据排序,数据筛选• 数据提取:字符串,日期,数值,关联表,条件函数•
对于一般的有序搜索,总是选择f值最小的节点作为扩展节点。因此,f是根据需要找到一条最小代价路径的观点来估算节点的,所以,可考虑每个节点n的估价函数值为两个分量:从起始节点到节点n的代价以及从节点n到达目标节点的代价。熟悉和掌握启发式搜索的定义、估价函数和算法过程,并利用A*算法求解N数码难题,理解求解流程和搜索顺序。A*算法实验(35分)(本实验的结果提交,在超星上传附件)要求:(每个节点扩展后的