




- @weixin_47933729
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
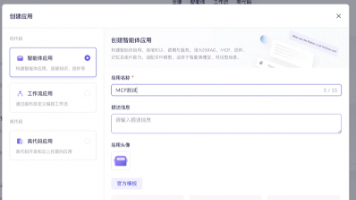
"会调接口"早已不是后端工程师的专利——在AI时代,这成了每个想用大模型创造业务价值的Agent开发者必备技能。通过MCP协议让Agent获取业务上下文,已成为行业标配,集团也提供了完善的工具链支持。但当你真正想弄懂MCP时,官网白皮书再精美,也逃不过"一看就懂,一写就懵"的困境。
文章强调知识库是RAG系统的核心和生命线,其质量直接决定智能问答系统的效果。知识库管理不仅是简单的文档切片和向量化,而是一套复杂系统,需处理多数据源、多格式文档,并进行标准化处理。完善的知识库系统需具备数据更新、版本管理、召回优化等功能,通过模块化架构设计实现。随着数据量增长,知识库架构设计变得至关重要,它是大模型时代的基础,能提升RAG系统的稳定性和扩展性。

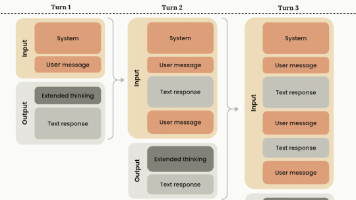
本文解析了Agent模型中的思维链(Thinking)概念,对比了Claude的Interleaved Thinking、Gemini的Thought Signature等不同实现方式。核心观点是:Agent通过将工具调用的思考内容带入上下文,可显著提升多轮长链路推理的稳定性,避免因思考内容丢弃导致的推理偏差。模型原生支持优于工程拼接,部分模型还添加签名校验和加密保护,已成为Agent多步骤推理的
LM Studio + DeepSeek R1 14B 本地大模型实测,内含收藏技巧!
本文介绍了如何通过Ollama快速部署DeepSeek、qwq、llama3、gemma3等大模型,无需GPU,普通电脑即可轻松搞定。文章提供了Ollama的安装指南和常用指令,并分享了如何获取更多开源模型。适合想保护隐私、需要定制AI功能的技术爱好者和开发者,帮助他们在本地实现AI聊天、写代码等功能。

“我们定义AI为研究从环境中接收感知并执行动作的智能体。”

本地运行大模型耗资源,需要选择较小的模型作为基础模型。在终端中运行时可能会出现 CUDA 错误,表示显存不足,导致提供的端口失效。中文支持不够完善。3. 文中提到的技术软件工具有:Ollama、Chatbox、Open WebUI、向量数据库、嵌入模型、本地模型 Gemma、AnythingLLM。

本文以Windows PC(RTX2060)为例,详细介绍了如何下载、安装和部署Ollama大模型,包括从模型仓库选择和部署通用模型,以及如何准备和部署自定义模型。此外,还提供了通过界面和API调用大模型的实用方法,适合想要学习大模型的小白和程序员参考。
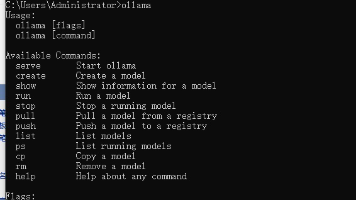
本文介绍了如何通过Ollama快速部署DeepSeek、qwq、llama3、gemma3等大模型,无需GPU,普通电脑即可轻松搞定。文章提供了Ollama的安装指南和常用指令,并分享了如何获取更多开源模型。适合想保护隐私、需要定制AI功能的技术爱好者和开发者,帮助他们在本地实现AI聊天、写代码等功能。
本文详细解析MCP(模型上下文协议)技术原理与实战实现,涵盖SSE传输、JSON-RPC 2.0消息格式等核心技术,并提供完整的Spring Boot + WebFlux实现示例。文章通过手把手教学,帮助读者掌握MCP Server开发流程,理解Agent与工具解耦机制,实现大模型调用接口标准化,是学习大模型Agent开发的必备指南。
