




- @weixin_46880696
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
弹性配额约束单人占用规模;近日,九章智算云(Alaya NeW Cloud)完成重大版本迭代,面向新的AI工厂范式——即像工厂流水线一样标准化、规模化生产AI模型和Token的能力——推出智能队列调度、资源配额管理、开发工具套件多项核心能力,在行业内率先构建起从“算力计量”到“算力治理”的全流程闭环,为大模型训练、推理、多模态开发及具身智能等场景提供标准化底层支撑。此次三大能力形成完整闭环:智能队

弹性配额约束单人占用规模;近日,九章智算云(Alaya NeW Cloud)完成重大版本迭代,面向新的AI工厂范式——即像工厂流水线一样标准化、规模化生产AI模型和Token的能力——推出智能队列调度、资源配额管理、开发工具套件多项核心能力,在行业内率先构建起从“算力计量”到“算力治理”的全流程闭环,为大模型训练、推理、多模态开发及具身智能等场景提供标准化底层支撑。此次三大能力形成完整闭环:智能队
DeepSeek-V2-Exp:一键部署,私有化轻松搞定,告别繁琐下载!
从Gemini 1到3,能明显感觉到AI的变化:以前是“我问你答”,现在是“我给目标,你给结果”。它不再是炫技的工具,而是真能帮你省时间、解决麻烦的“帮手”。现在Gemini 3 Pro已经全量开放,不管是学生、职场人还是程序员,都能直接去体验。不用怕学不会,它对指令的理解特别直接,越简单的要求反而做得越好。你最想用它解决啥问题?是帮你整理考研笔记,还是做菜谱、写代码?你可以在评论区大开脑洞。实操
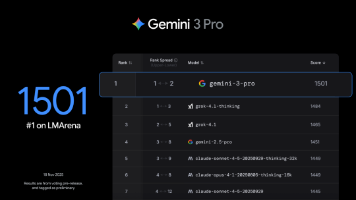
在多项测试中表现优异,SWE - Bench Verified 测试准确率 77.9%,Terminal - Bench 2.0 测试准确率 58.1%,均优于谷歌 Gemini 3 Pro,目前已集成到多款开发环境,助力开发者大幅提升工作效率。该 APP 依托阿里在大模型领域的技术积累,聚焦开源优势,为用户提供智能问答等基础功能。搭载该模型的机器人可在办公室制作咖啡、组装纸箱等,能连续一整天制作

Agentic AI不是“更聪明的工具”,而是新型生产力关系的重构 ——人类从“操作者”变为“监督者”,Agent从“执行者”变为“责任主体”。“In an agentic world, trust is not a feature. It must be the foundation.”(在智能体的世界里,信任不是一项功能,而必须是基石。所以,别再问“我们能不能上Agent?要问:“我们的安全水

OpenClaw凭借长期记忆、主动服务、全场景适配等特点,可精准满足企业管理者、个人用户、开发者与非技术用户等不同群体的需求,既能为管理者提供信息过滤、会议辅助、决策摘要、自动复盘等服务,也能为个人用户提供日程管理、生活提醒、情感陪伴等个性化支持,同时支持定制化开发与自然语言极简操作,让各类用户都能轻松使用AI助理能力。操作流程上,方案将模型接入、消息平台配置、技能加载等步骤整合为可视化流程,支持

本文将神经网络分成三个主要类别,并详细介绍了每个类别的主要神经网络模型,读完本文你将能迅速掌握常用的经典神经网络模型,属于深度学习的基础入门篇。
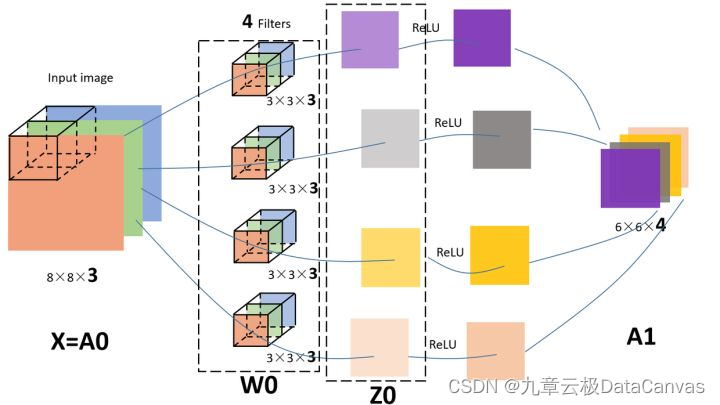
本文以特征工程的基本概念为引,着重介绍了特征工程的主要工作流程和实现方法,供大家学习参考。
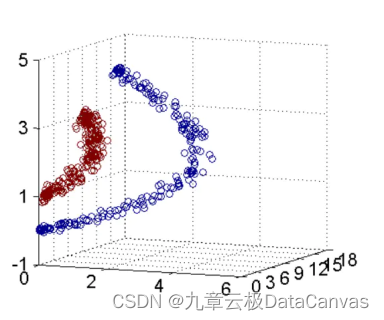
详细解析数据挖掘、机器学习、深度学习的概念和区别
