




- @weixin_45193103
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
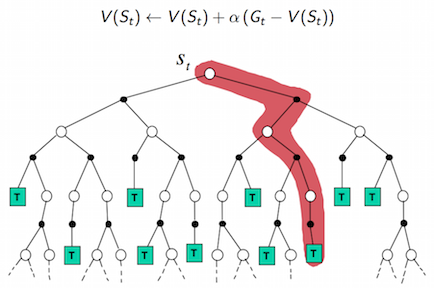
强化学习算法可以分为三大类:(1)value based,(2) policy based 和 (3)actor critic。常见的是以DQN为代表的value based算法,这种算法中只有一个值函数网络,没有policy网络,以及以DDPG,TRPO为代表的actor-critic算法,这种算法中既有值函数网络,又有policy网络。说到DQN中有值函数网络,这里简单介绍一下强化学习中的一个
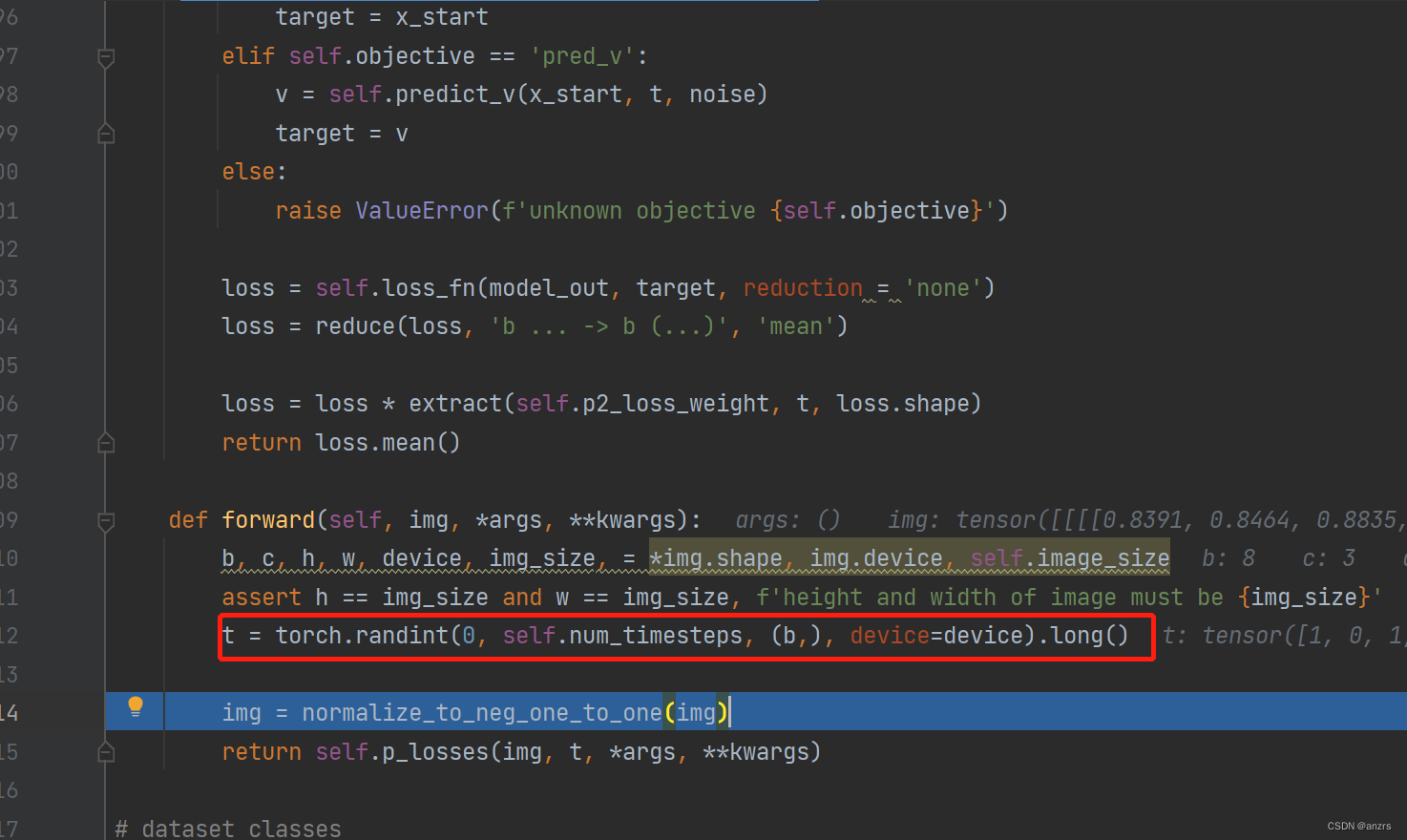
他这个normalize_neg_one_to_one,只有一行,就返回了img,我们接下来试一下,这个操作会产生什么样的变化,因为他变化一下就输入到了p_losses里面,可以看到在p_losses之前的操作都是特别简单的,这说明整个需要操作的大部分应该都在p_losses里面。12.看一下这个extract 是干什么的,他需要传入三个值,这些都是一些基本的属性,并没有传入x_start本身,所
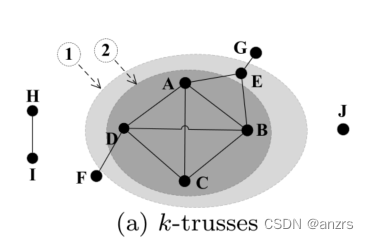
K-core:什么叫k-core,给定一个正整数k(k>=0),k-core是一个G的最大子图(也就是说k-core是一个图的限制),将这个子图定义为Hk,对于Hk中的每个顶点v,他的度数都是大于等于k的。k-core是内嵌的,如下图所示,集合{ABCD}是H3,也就是3-core的子图。而集合{ABCDE}是H2,也就是2-core的子图,集合{ABCDEGF}是H1,也就是1-core的
对于Model这个类,第一句:定义一个初始化函数,第二句:从父类nn.Module中继承了父类的初始化函数,第三和第四句都是自己写的。class Model(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(1, 20, 5)self.conv2 = nn.Conv2d(20, 20, 5)def forw
#方式1,加载模型model = torch.load("vgg16_method1.pth")print(model)查看读取的模型,如下:VGG((features): Sequential((0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU(inplace=True)(2): Conv2

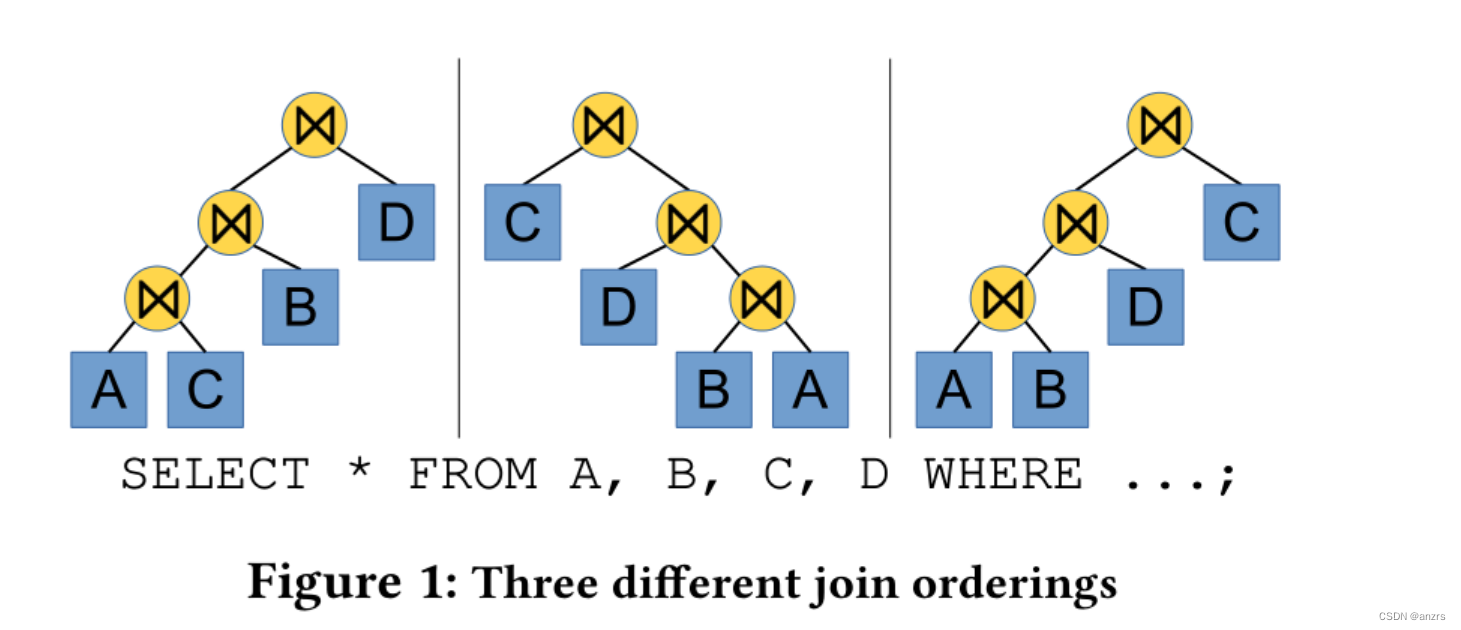
ABSTRACT:连接顺序选择对查询性能起着非常重要的作用。然而,现代的查询优化器通常使用静态的连接顺序枚举算法,并没有包含也有关质量的反馈。因此优化器经常会重复的选择一个糟糕的计划,因为他们没有从错误中进行学习的机制。在这里,我们认为(argue)深度强化学习技术可以用来应对这一挑战。这些由人工神经网络支持的技术可以通过结合反馈来自动的改善优化器的决策执行。为了实现这一个目标,我们提供了ReJO
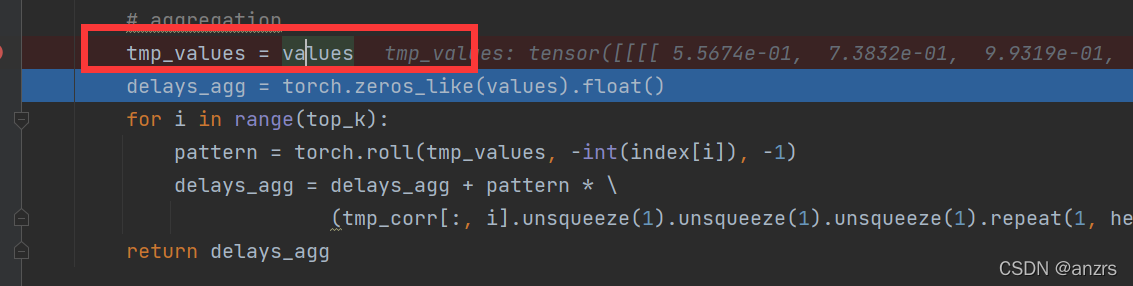
目录1.整个AutoCorrelation的结构2.对q和k进行处理3.对Value进行处理4.aggregation(最难的部分)1.整个AutoCorrelation的结构整个AutoCorrelation层初始化了三个函数,但是只用到了两个,这里存在疑问,不知道为什么是这样的。2.对q和k进行处理q_fft和k_fft是得到的傅里叶变换的一个向量,他的维度是(32,8,64,49)。res是
作者:王椗链接:https://www.zhihu.com/question/369075515/answer/994819222来源:知乎著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。我自己的理解是这样的。Transformer在训练的时候是并行执行的,所以在decoder的第一个sublayer里需要seq mask,其目的就是为了在预测未来数据时把这些未来的数据屏蔽掉,
