- @weixin_44782294
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
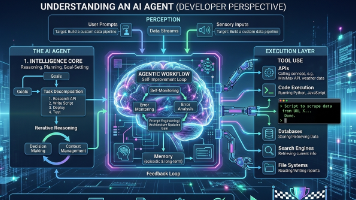
本文介绍了一种通过DispatchMap模式扩展AI Agent工具能力的方法。核心思路是保持主循环不变,通过字典映射将工具名与处理函数关联,实现零成本工具扩展。文章详细解析了路径沙箱(safe_path)安全机制、四个专用工具(read/write/edit文件及bash)的实现,以及如何通过TOOL_HANDLERS字典实现工具分发。这种设计遵循开放-封闭原则,新增工具只需注册到字典而无需修改

本文提出了一种为AI Agent添加结构化任务管理模块的方法,通过引入"Todo工具"解决多步任务执行中的注意力漂移问题。核心创新点包括: 设计了一个独立于对话历史的PlanningState状态,包含任务列表和健康指标 强制同一时间只能有一个进行中任务,确保执行焦点 实现自动提醒机制,当Agent长时间未更新计划时主动干预 提供可视化进度展示,使任务状态对开发者和模型都清晰可

ViduS1重新定义了实时AI交互模型,突破传统数字人技术局限,实现540P/25FPS的流式视频生成。其核心技术在于:1)双向感知能力,通过流式视频扩散模型实时生成符合语义和情绪的连贯反应;2)采用短窗口自回归+状态锚定技术解决无限时长生成的误差累积问题;3)三通道分离架构实现生成与传输解耦。当前虽存在分辨率限制(540P)和单次会话时长(10分钟)等边界,但已展现出实时视频对话的商业潜力。该技
摘要:Google DeepMind于2026年6月30日推出Gemini OmniFlash视频生成模型(ID:gemini-omni-flash-preview),支持多模态输入与对话式视频编辑。用户可通过文字、图片或视频混合输入生成10秒动态内容,并能通过自然语言指令实时修改(如调整灯光、替换文字等),无需重新生成完整视频。该模型定价0.10美元/秒,与Veo 3.1 Fast持平,但增加了

摘要:Google DeepMind于2026年6月30日推出Gemini OmniFlash视频生成模型(ID:gemini-omni-flash-preview),支持多模态输入与对话式视频编辑。用户可通过文字、图片或视频混合输入生成10秒动态内容,并能通过自然语言指令实时修改(如调整灯光、替换文字等),无需重新生成完整视频。该模型定价0.10美元/秒,与Veo 3.1 Fast持平,但增加了
AI时代HTML正取代Markdown成为文档新标准。Claude团队工程师Thariq Shihipar提出HTML比Markdown更适合AI生成内容,因其支持交互组件、结构化展示等优势。开源项目html-anything让本地AI直接输出HTML,实现"草稿→成品"的转换。这种转变反映了AI时代文档从"写作工具"向"阅读产品"的演进
MetaSAM3DBody的C++独立推理引擎实现单目摄像头实时3D人体动作捕捉,输出70关节BVH文件 【核心突破】 纯C++实现:基于ONNXRuntime+ggml,消除Python依赖,实现工业级部署 完整3D重建:单RGB输入即可生成含手指/面部细节的3D人体网格(62.9MPJPE精度) 动捕管线: 5ms级YOLO11m-pose检测 150ms级DINOv3-ViT特征编码 原生B

文章摘要 Anthropic突破性地构建了七层AI编程架构ClaudeCode,系统性解决大型代码库的协作难题。该架构通过CLAUDE.md实现持久上下文记忆,利用Hooks设置安全边界,整合Skills封装专业知识,结合LSP提升代码理解精度,通过MCP协议对接开发环境,运用子代理并行处理复杂任务。这种分层设计让AI从"智能补全"进化为"全栈协作者",开发

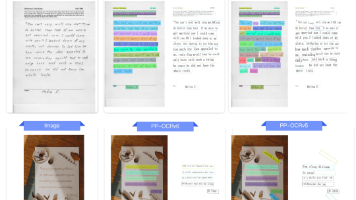
百度开源的PP-OCRv6模型凭借超小参数量(1.5M-34.5M)在OCR任务中全面超越GPT-5.5、Gemini等千亿级大模型,展现出专用轻量模型的优势。其核心创新包括:统一架构LCNetV4、改进的RepLKFPN检测模块和LightSVTR识别模块,解决了大模型存在的定位不准、文字幻觉和算力成本高等问题。PP-OCRv6在50种语言识别、CPU推理速度(比上代快5.2倍)等方面表现突出,
文章摘要:Agentic Loop(自主循环)的执行关键在于预设明确的停止机制,避免失控和资源浪费。核心设计包括:1) 明确定义任务范围与可验证的成功条件;2) 在每轮迭代中嵌入三层验证(动作/迭代/终止);3) 设置预算上限和重试限制;4) 编写清晰的停止条件(成功/失败/预算)。推荐测试驱动、差异评审和检查点摘要三种循环模式,强调外部验证优于模型自判。真正的挑战在于提前设计终止逻辑,而非技术实