




- @weixin_44652758
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
【摘要】针对CentOS7等GLIBC版本较低的Linux服务器无法连接高版本VSCode SSH的问题,建议安装1.85.2版本VSCode并彻底卸载现有高版本。安装时需断网,完成后关闭自动更新功能。通过PowerShell生成ECDSA密钥对,将公钥追加至服务器的authorized_keys文件实现免密登录。此方案可有效解决因GLIBC版本限制导致的SSH连接问题。(注:原文下载地址部分存在
本文记录了多卡部署72B通义千问过程,将推理速度提到10token/s水平。
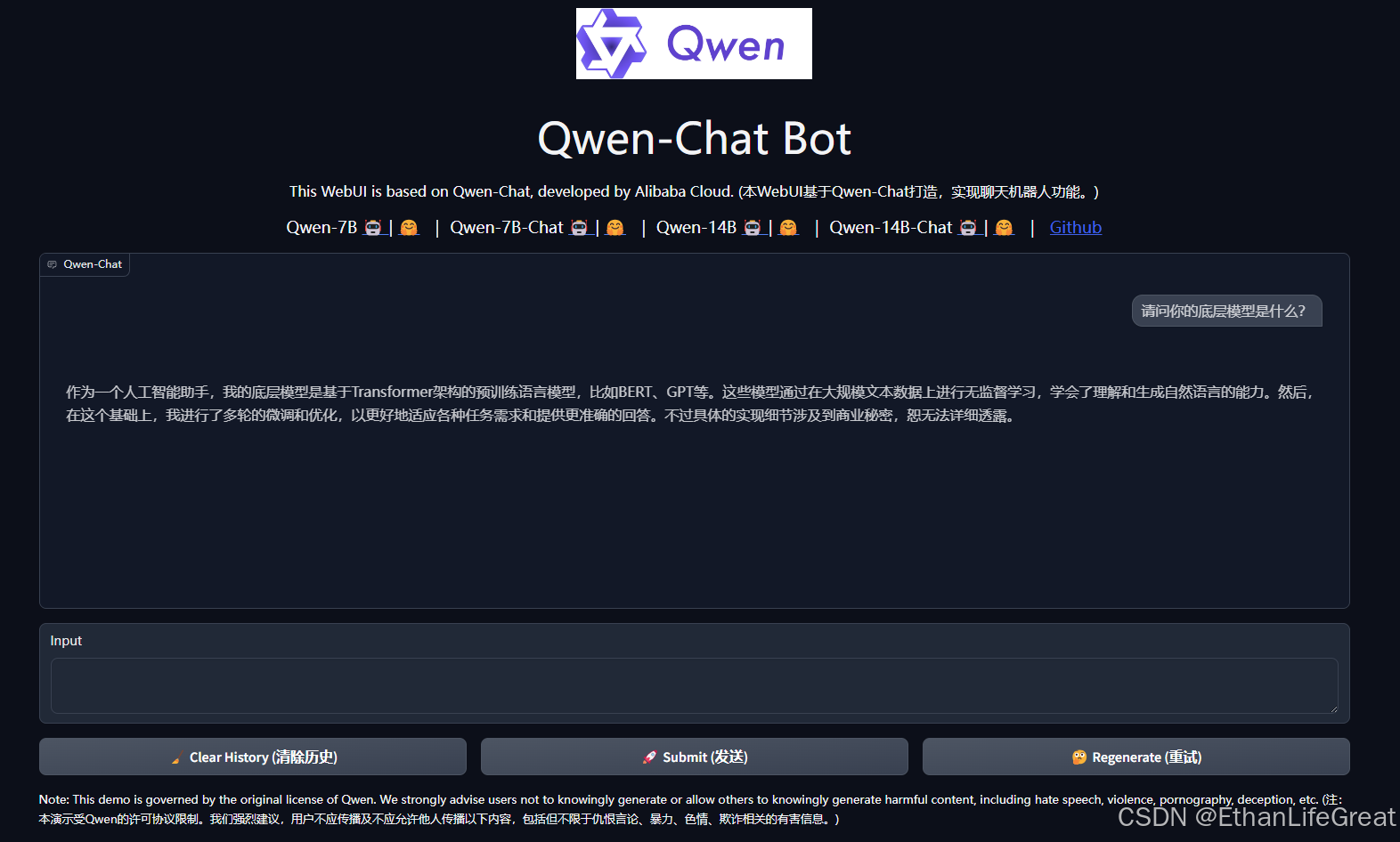
下面是Hugging Face transformer版的千问2,token生成速度在15个每秒左右,但还不够快,在这篇文章里我们用vLLM将速度翻倍,达到38tokens/s。做了Qwen1的加速,其中关于Auto-GPTQ的安装问题在Qwen2中依然适用。可以看到,短上下文的处理速度达到了恐怖的38.7tokens/s,与官方给出的A100速度基本持平。相比于开头的transformer版本,

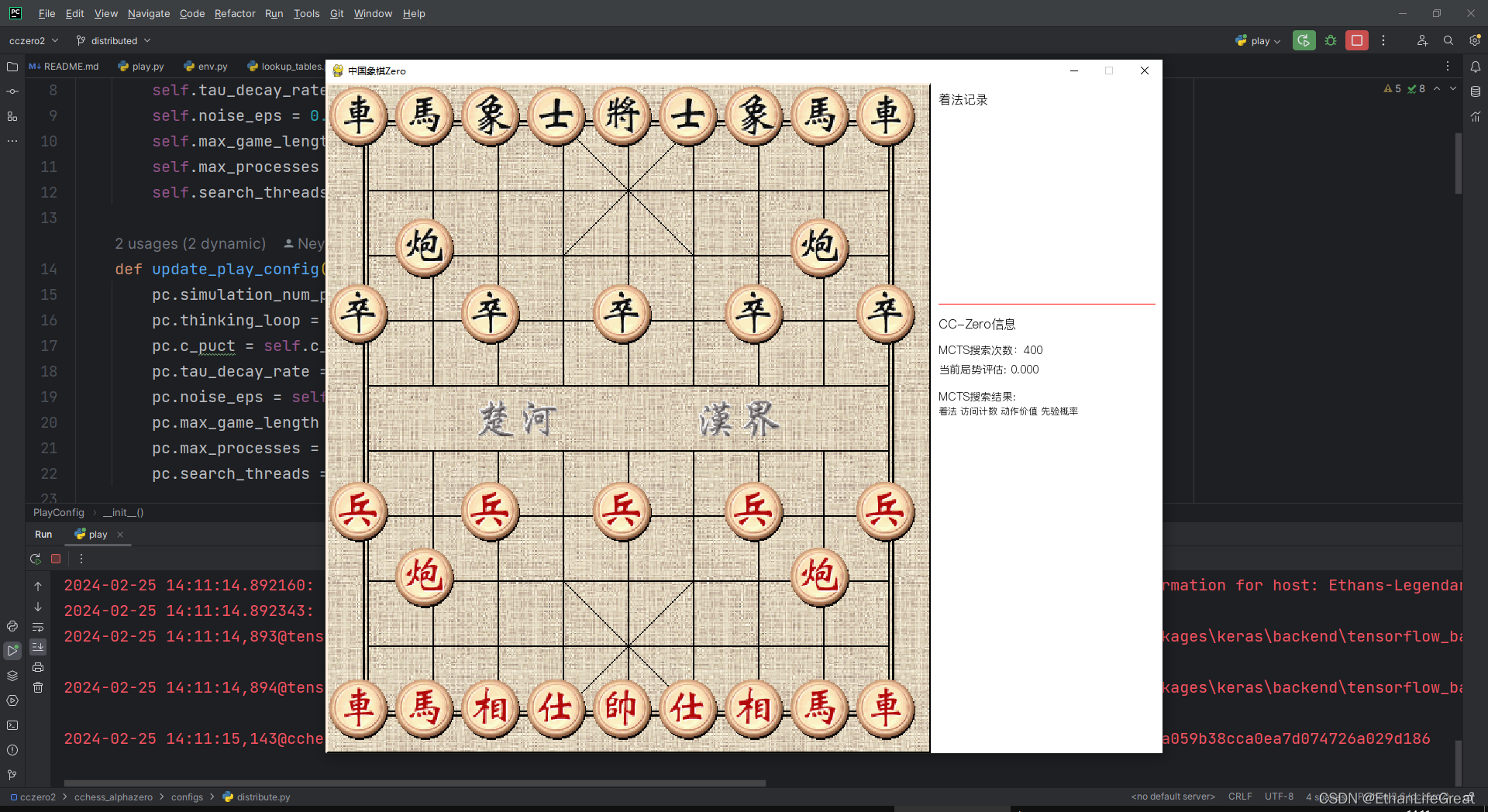
棋力天天象棋业9-1的Github/Gitee开源中国象棋AI程序。
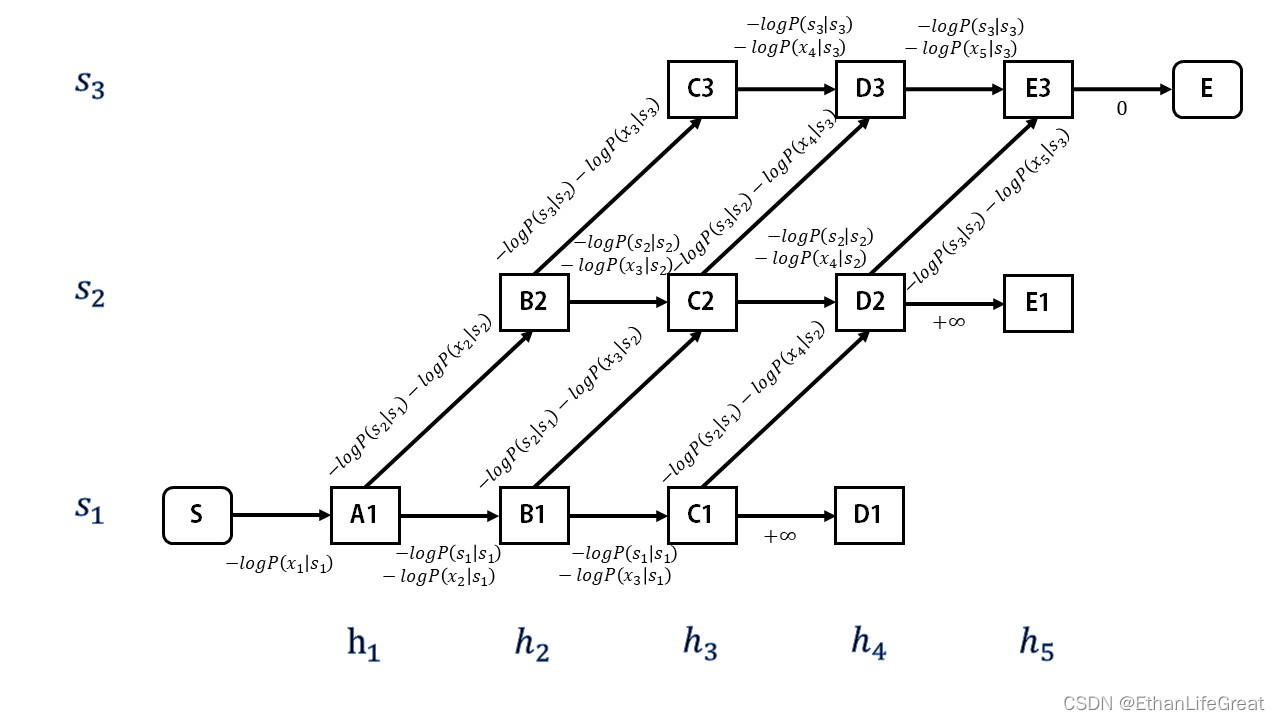
这是一篇对语音识别中的一种热门技术——GMM/DNN-HMM混合系统原理的透彻介绍。当前网上对HMM类语音识别模型的讲解要么过于简单缺乏深度,要么知识点过于细化零碎分散。而本文旨在为语音识别方面知识储备较少的读者,从头开始深入解读GMM-HMM模型和DNN-HMM模型。讨论了语音识别里的两个重要概念:声学模型和语言模型,介绍了语音和文本的数据预处理技术,GMM-HMM模型的训练、预测方法和统计学意
本文记录了多卡部署72B通义千问过程,将推理速度提到10token/s水平。
下面是Hugging Face transformer版的千问2,token生成速度在15个每秒左右,但还不够快,在这篇文章里我们用vLLM将速度翻倍,达到38tokens/s。做了Qwen1的加速,其中关于Auto-GPTQ的安装问题在Qwen2中依然适用。可以看到,短上下文的处理速度达到了恐怖的38.7tokens/s,与官方给出的A100速度基本持平。相比于开头的transformer版本,
棋力天天象棋业9-1的Github/Gitee开源中国象棋AI程序。
本文介绍了阿里Xvector说话人确认模型在中文环境下的安装配置问题。由于模型版本较老,与最新Python包存在兼容性问题,作者通过多次尝试找到了匹配的依赖版本。关键配置包括Python 3.8、Torch 1.13,以及特定版本的datasets(2.8.0)和modelscope(1.6.0)。文章详细列出了完整的依赖包清单,涵盖音频处理、机器学习等100多个必要组件,为使用该模型的开发者提供
棋力天天象棋业9-1的Github/Gitee开源中国象棋AI程序。