- @weixin_43875437
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
B站优质深度学习课程推荐:AI技术日新月异,深度学习课程资源日益丰富。本文推荐了B站上值得学习的几门课程:1) 吴恩达《深度学习》系列(30小时),适合零基础入门;2) 邱锡鹏《神经网络与深度学习》,建议学习前四章;3) 李沐《动手学深度学习》(50小时),结合PyTorch实战;4) 霹雳吧啦Wz的实战导向课程。此外还推荐了尚硅谷、李宏毅等课程。建议学习者不必全部看完,可根据自身基础选择重点内容

本文详细介绍了如何将YOLOv5应用于自定义数据集训练。首先解析了COCO数据集的结构,包括路径配置和标签格式。然后重点讲解了使用labelimg工具制作自定义数据集的方法:创建规范的目录结构,标注图片并生成YOLO格式的标签文件。接着说明了如何编写适配自己数据集的yaml配置文件,包括设置数据路径和类别名称。最后给出了训练和测试模型的完整命令流程,生成的模型将保存在指定目录中。整个过程强调保持与

HuggingFace是机器学习领域的知名开源社区,被誉为"机器学习界的GitHub"。最初作为聊天机器人服务商,却因开源Transformer库意外走红。平台主要提供两大核心服务:1)丰富的预训练模型库(如GPT、BERT等),通过简洁API实现文本分类、翻译等任务;2)海量数据集资源(81万+),涵盖NLP、CV等领域。用户可通过简单pip安装快速调用模型和数据集,无需重复

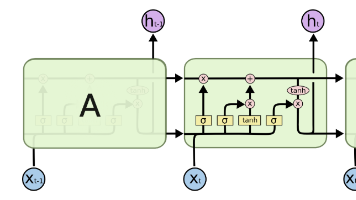
LSTM我们主要把握好它的输入输出,以及门控机制的几个公式,就可以迅速掌握啦。如果之前了解过RNN的小伙伴就会知道,RNN天然有着许多不足,比如梯度爆炸和梯度消失的问题,不能解决长距离依赖。LSTM针对以上几点,通过门控机制对其作出了改进,使得LSTM大放异彩,同时有了很多变种,在NLP领域表现非常出色。
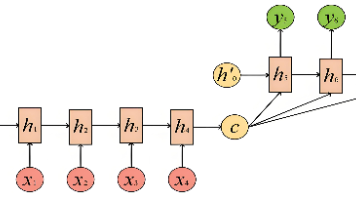
介绍了RNN(循环神经网络)的基础知识和应用场景。RNN作为NLP领域的重要模型,RNN通过循环连接的网络结构处理序列数据,解决了CNN难以处理变长序列的问题。文章详细解析了RNN的四种典型结构(1to1、NtoN、Nto1、1toN)及其工作原理,重点说明了隐状态h的信息传递机制。同时探讨了RNN在机器翻译、情感分析等任务中的应用,以及其存在的梯度爆炸和长距离依赖等缺陷。
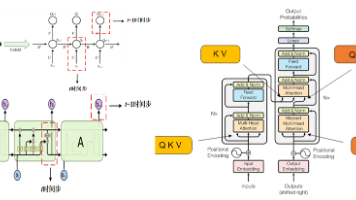
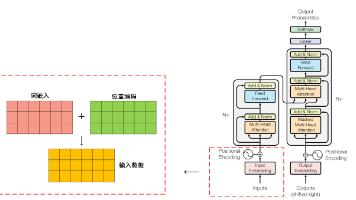
文章重点讲解了Transformer输入处理的两个关键步骤:词嵌入和位置编码。词嵌入通过将词语映射到高维向量空间来保留语义信息,而位置编码则通过正弦和余弦函数为模型提供位置信息。文中详细说明了词嵌入矩阵的构建方法、维度选择以及位置编码的计算公式,并解释了如何将两者相加作为Transformer的最终输入。这些处理使Transformer能够有效捕捉序列中词语的语义和位置关系,为后续的自注意力机制等
YOLO26是新一代计算机视觉模型,专为边缘设备和低算力平台优化。其创新点包括移除DFL模块、实现端到端无NMS推理、采用ProgLoss+STAL提升小目标检测能力,以及使用MuSGDOptimizer优化训练过程,CPU推理速度提升43%。该模型支持分类、检测、分割等任务,适用于机器人、无人机、制造业和嵌入式设备等场景。用户可通过Ultralytics平台快速部署,提供本地训练和直接预测两种使

YOLO26是新一代计算机视觉模型,专为边缘设备和低算力平台优化。其创新点包括移除DFL模块、实现端到端无NMS推理、采用ProgLoss+STAL提升小目标检测能力,以及使用MuSGDOptimizer优化训练过程,CPU推理速度提升43%。该模型支持分类、检测、分割等任务,适用于机器人、无人机、制造业和嵌入式设备等场景。用户可通过Ultralytics平台快速部署,提供本地训练和直接预测两种使
主要包含四部分内容:1、代码目录结构2、使用方法(如何训练,如何预测)3、代码详解(模型具体的搭建过程)4、结果分析(参数如何调整)
本文系统总结了Transformer核心机制的原理与作用。首先回顾了Transformer的关键组件:词嵌入与位置编码解决了并行计算丢失序列位置信息的问题;点积注意力机制通过矩阵乘法高效计算相似度,并采用√dk缩放防止梯度消失;层归一化通过通道级归一化降低BatchSize影响,更适合NLP任务。特别对比了Encoder-Decoder结构的差异:Decoder采用掩码注意力处理目标序列,第二层注