




- @weixin_43507744
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
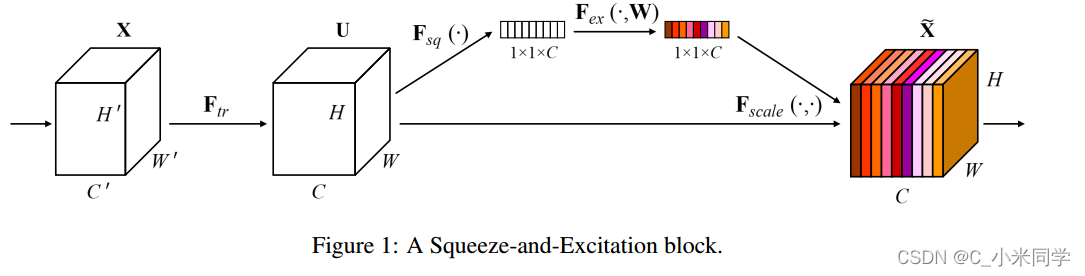
对于CNN网络来说,其核心计算是卷积算子,其通过卷积核从输入特征图学习到新特征图。从本质上讲,卷积是对一个局部区域进行特征融合,这包括空间上(H和W维度)以及通道间(C维度)的特征融合 我们可以发现卷积实际上是对局部区域进行的特征融合。 这也导致了普通卷积神经网络的感受野不大,当然你也可以设计出更多的通道特征来增加这个,但是这样做导致了计算量大大的增加。因此为了空间上融合更多特征融合,或者是提取多
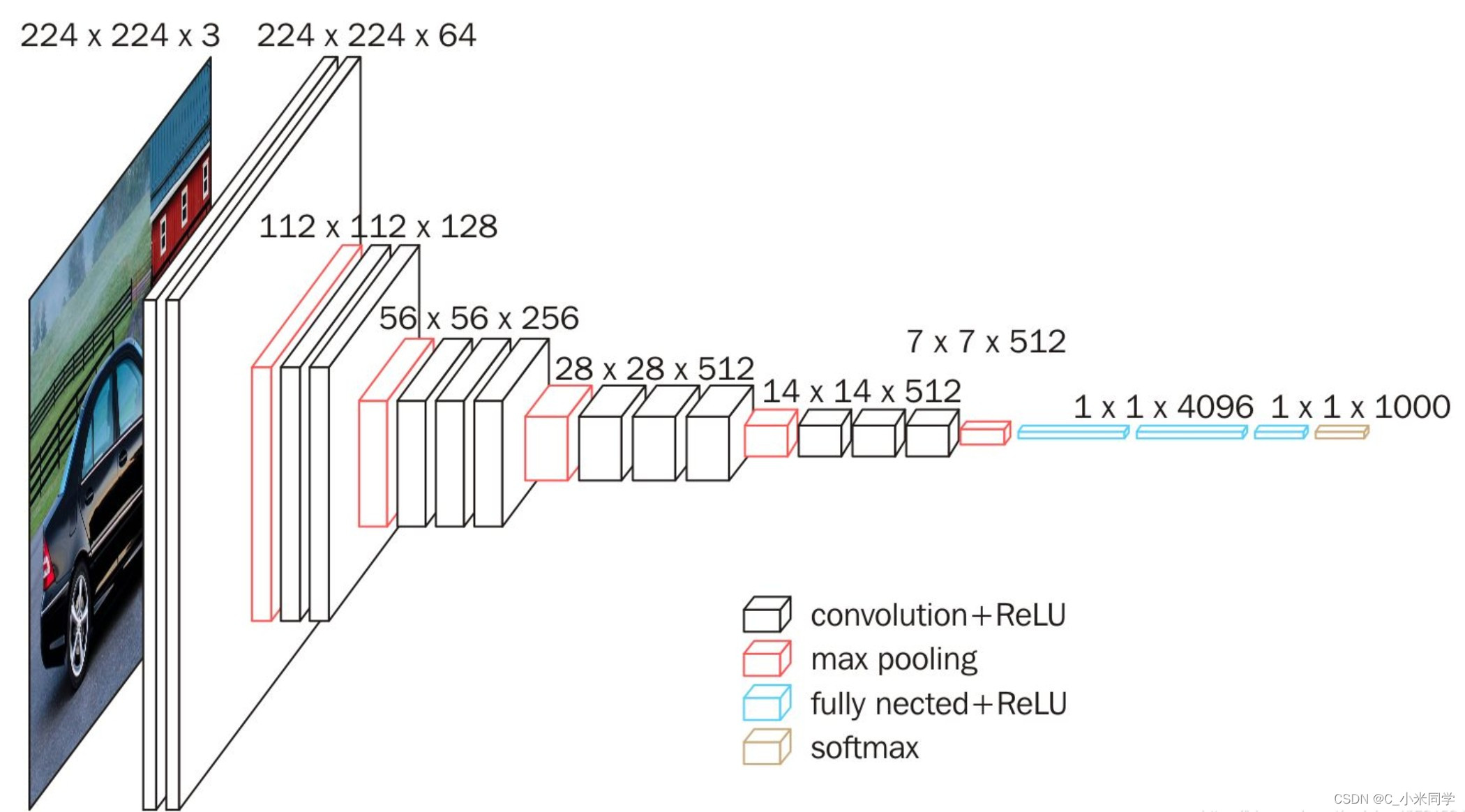
目录图像分类Lenet1.简介2.网络结构Alexnet1.简介2.网络结构VGG1.简介2.网络结构3.VGG改进点总结GoogLeNet1.网络简介2.inception的结构3. 1x1卷积核的主要作用4. 几点说明Resnet1.简介2.网络结构DenseNet1.简介2.网络结构EfficientNetEfficientNetV2sufflentV2sufflenet时间轴代码实现训练结
深度学习一直作为一个“盲盒”被大家诟病,我们可以借助深度学习实现端到端的训练,简单,有效,但是我们并不了解神经网络的中间层到底在做什么,每一层卷积的关注点是什么。我在之前的专题浅谈图像处理与深度学习中提到,我们在深度学习刚开始的时候,我们要实现一个任务,比如:把不清晰的图像变清晰,我们随意的搭建了三层网络,然后开始训练,发现效果比传统的图像处理方法好,而且简单有效,然后我们再随意的搭建四层网络,

超分辨率(super-resolution)、去模糊(deblurring)等视频恢复任务越来越受到计算机视觉界的关注。在NTIRE19挑战赛中发布了一个名为REDS的具有挑战性的基准测试。这个新的基准测试从两个方面挑战了现有的方法:(1)如何在给定大运动的情况下对齐多个帧(2)如何有效地融合不同运动和模糊的不同帧。在这项工作中,我们提出了一种新的视频恢复框架,增强可变形卷积,称为EDVR,以解决
目录图像分类Lenet1.简介2.网络结构Alexnet1.简介2.网络结构VGG1.简介2.网络结构3.VGG改进点总结GoogLeNet1.网络简介2.inception的结构3. 1x1卷积核的主要作用4. 几点说明Resnet1.简介2.网络结构DenseNet1.简介2.网络结构EfficientNetEfficientNetV2sufflentV2sufflenet时间轴代码实现训练结
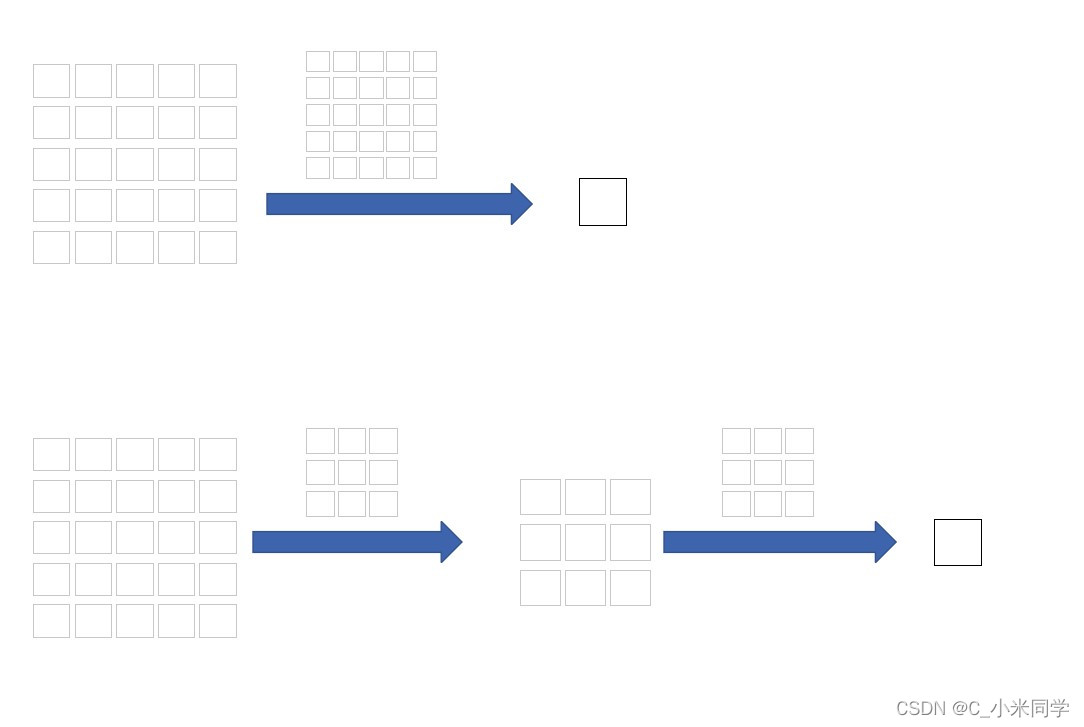
感受野基本概念1.输出feature map上的一个单元对应输入层 上的区域大小2.感受野的增速是直接和卷积步长累乘相关,想要网络更快速的达到某个感受野尺度,可以让步长大于1的卷积核更靠前,这样可以增加网络推理速度,特增图的分辨率会迅速变小3.当有效感受野的区域能够覆盖全图时,这时的特征表达能力是最好的(有效感受野跟关注中间的内容)4. 1x1的卷积相当于全连接层,可以用前者代替后者,形成全卷积.
超分辨率(super-resolution)、去模糊(deblurring)等视频恢复任务越来越受到计算机视觉界的关注。在NTIRE19挑战赛中发布了一个名为REDS的具有挑战性的基准测试。这个新的基准测试从两个方面挑战了现有的方法:(1)如何在给定大运动的情况下对齐多个帧(2)如何有效地融合不同运动和模糊的不同帧。在这项工作中,我们提出了一种新的视频恢复框架,增强可变形卷积,称为EDVR,以解决
目录图像分类Lenet1.简介2.网络结构Alexnet1.简介2.网络结构VGG1.简介2.网络结构3.VGG改进点总结GoogLeNet1.网络简介2.inception的结构3. 1x1卷积核的主要作用4. 几点说明Resnet1.简介2.网络结构DenseNet1.简介2.网络结构EfficientNetEfficientNetV2sufflentV2sufflenet时间轴代码实现训练结
深度学习一直作为一个“盲盒”被大家诟病,我们可以借助深度学习实现端到端的训练,简单,有效,但是我们并不了解神经网络的中间层到底在做什么,每一层卷积的关注点是什么。我在之前的专题浅谈图像处理与深度学习中提到,我们在深度学习刚开始的时候,我们要实现一个任务,比如:把不清晰的图像变清晰,我们随意的搭建了三层网络,然后开始训练,发现效果比传统的图像处理方法好,而且简单有效,然后我们再随意的搭建四层网络,
with torch.no_grad()或@torch.no_grad() 用法