- @weixin_42990464
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
特性传统枚举 (enum)有作用域枚举 (enum class)作用域无作用域,会污染外层有作用域,需要Enum::Value隐式转换允许隐式转换为int不允许,需要显式转换类型安全较低较高底层类型默认int,可指定默认int,可指定推荐使用旧代码兼容新项目推荐最佳实践建议在新代码中优先使用enum class为枚举指定合适的底层类型以节省内存为枚举提供相关的工具函数避免使用魔术数字,使用有意义的
文章目录2019RoadNet:2019RoadNet:code: https://github.com/yhlleo/RoadNet论文的贡献该文提出了一个多任务像素端到端CNN,道路网,以同时预测路面,边缘和中心线。 道路网自动学习多尺度和多级特征,并在一个专门设计的级联网络中进行整体训练,可以处理各种场景和尺度的道路。上述子任务在训练阶段是相关的,其中路面分割的预测被应用于道路边缘检测和道路
文章目录前言方法介绍参考前言之前简单介绍了水平框的裁剪方法,感兴趣的点击这里。这篇博文将介绍旋转框的裁剪方法。方法介绍使用DOTA_devkit工具包中的imageSplit.py。# example usage of ImgSplitsplit = splitbase(r'example',r'examplesplit')split.splitdata(1)example中的文件路径格式裁剪效果
1、https://github.com/PRBonn/agribot2、https://github.com/ros-mobile-robots/diffbot

文章目录前言2018Deep Extraction of Cropland Parcels from Very High-Resolution Remotely Sensed Imagery前言本博文是对关于农田提取论文的简单汇总。有比较新颖的方法,欢迎大家在下面留言。2018Deep Extraction of Cropland Parcels from Very High-Resolution

你可以在yolo中这样使用。
前言在目标检测推理过程中,经常出现误检的情况。将误检的目标引入样本集中,会大幅降低误检率。思路找出误检的目标,并将其裁成切片;将负样本切片粘贴到原先的样本集中。原样本切片引入负样本后的切片代码small_objects_paste.pyimport aug as amimport globimport randomimport osfrom shp2imagexy import shp2image
code: https://github.com/open-mmlab/mmdetection3d/tree/main/configs/fcaf3d解析:https://py1995.blog.csdn.net/article/details/154793542?spm=1001.2014.3001.5502code:https://github.com/open-mmlab/mmdetectio
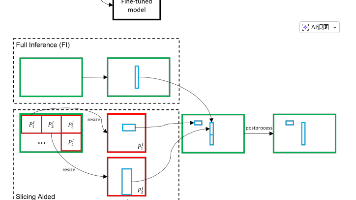
code: https://github.com/obss/sahi概要:这篇论文提出了一种名为切片辅助超推理(SAHI) 的通用框架,通过切片辅助微调 和切片辅助推理 两种方法,显著提升了小目标检测的性能。其核心贡献在于:无需修改现有检测器结构,即可通过图像切片与重叠推理策略有效增强小目标的检测能力,并在VisDrone和xView数据集上实现了最高达14.5%的平均精度提升。该方法已集成至主流
实例分割任务是众所周知的目标检测任务的扩展,在许多领域都有很大的帮助,如精确农业:能够自动识别植物器官及其可能相关的疾病,可以有效地扩大规模和自动化作物监测及其疾病控制。为了解决与葡萄藤植物早期疾病检测和诊断相关的问题,我们建立了一个新的数据集,目的是通过实例分割方法推进疾病识别的技术水平。这是通过收集在自然环境中受疾病影响的叶子和葡萄簇的图像来实现的。该数据集包含10种物体类型的照片,其中包括有