




- @weixin_42917352
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
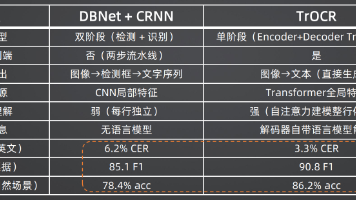
OCR的全称是Optical Character Recognition(光学字符识别),本质上是一种从视觉信号中恢复语言符号的任务。从底层技术来看,它是一个典型的计算机视觉任务:输入是图像信号(像素矩阵),输出是文本符号序列。但从上层目标来看,OCR更是一种视觉与语言的跨模态映射——模型需要将图像中的视觉特征(笔画、形状、布局)映射到人类可理解的语言空间。从1920年代的模板匹配到今天的多模态大
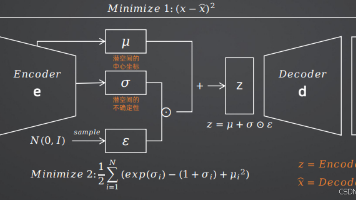
从VAE和GAN的奠基,到扩散模型的爆发,再到ControlNet和LoRA等可控生成技术的成熟,AI生成技术在短短几年内取得了令人瞩目的进步。今天,我们已经可以用AI生成高质量的图像、视频、音频和3D模型,这些技术正在深刻改变设计、影视、游戏、教育等众多行业。更高的效率:随着LCM等加速技术的不断进步,AI生成将从"秒级"进入"实时级",实现真正的交互式生成更强的可控性:更精细的结构控制、更准确
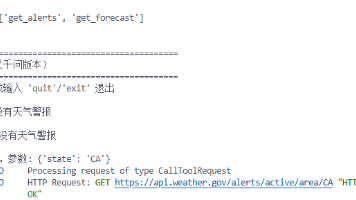
MCP(Model Context Protocol)是标准化的 LLM 工具调用协议。场景:用户问 AI “纽约天气怎样?方案实现方式问题方案 1:拒绝“我不知道”LLM 知识库有限,无法处理实时数据方案 2:散乱集成写 if/else 判断调用哪个 API每个 LLM 都要重新适配,维护困难方案 3:标准协议遵循 MCP 规范,让 LLM 自动发现并调用工具✅ 优雅、可扩展、LLM 无关MCP
OCR(Optical Character Recognition,光学字符识别)的核心本质,是从视觉信号中恢复语言符号的跨模态任务。底层属性:计算机视觉任务,输入为图像信号,输出为文本符号序列;上层目标:视觉与语言的跨模态映射,将像素级的视觉特征,映射到可计算的语言空间;像素(Pixel) → 字符(Character) → 结构化可读文本(Text) → 语义理解(Meaning)
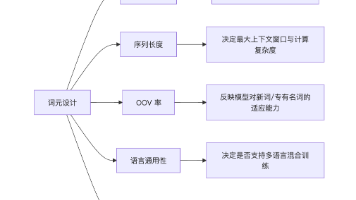
维度BPEWordPieceUnigram训练方向自底向上合并自底向上合并自底向上或自顶向下自顶向下裁剪合并标准频率最高似然增益最大频率/似然裁剪损失最小推理方式贪心匹配贪心匹配贪心/ViterbiViterbi 最优语言依赖需预分词需预分词语言无关语言无关代表模型BERTT5, LLaMAT5, XLM-R分词器选择影响资源消耗:粗粒度分词减少 token 数,但可能损失语义;细粒度保留语义,但
从1920年代的专用字体模板匹配,到1970年代的通用字体模式识别,再到2010年代的深度学习两阶段架构,OCR技术已经走过了近百年的发展历程。而生成式与Transformer式OCR的出现,标志着OCR技术进入了一个全新的时代——文档智能时代。在这个时代,OCR不再是简单的"像素转文字"工具,而是成为了连接现实世界与数字世界的智能接口。它不仅能"看清"文字,还能"看懂"文档的内容、布局和逻辑;不
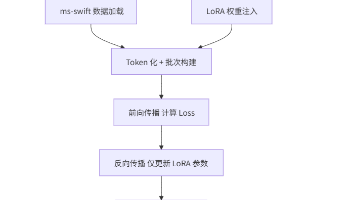
大语言模型(LLM)拥有强大的通用能力,但在特定领域任务上,往往需要"微调"来适配。概念说明对比全量微调更新模型所有参数显存需求大,1.5B 模型约需 12GB+LoRA 微调冻结原始权重,仅训练低秩分解矩阵仅训练 0.6% 参数,显存需求降低 70%+在输入端添加可学习 token不修改模型权重,能力有限不直接修改原始权重矩阵WWW,而是学习一个低秩增量ΔWBAΔWBA,其中B∈Rd×rB∈Rd
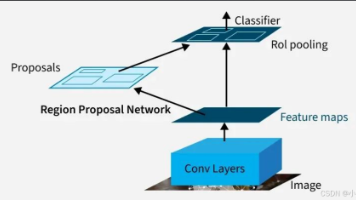
视觉定位完成了自然语言到图像空间的精准锚定,是跨模态感知的关键基石。从传统的锚点+NMS架构,到DETR的无锚框Transformer革新,再到GLIP、Grounding DINO的开放词汇突破,以及UniVG-R1的视频时空定位升级,视觉定位不断突破封闭场景限制,向开放世界、动态时序、多模态融合方向发展。如今,视觉定位已广泛应用于图像标注、智能交互、机器人感知、视频监控等场景,成为多模态AI落

视觉问答(VQA)作为多模态AI的核心基础任务,完成了从像素级视觉信息到语义级文本答案从ViLBERT的双流协同注意力,到BLIP-2的双塔+Q-Former桥接,再到LLaVA-Next的极简MLP桥接,高效化、轻量化是VQA模型的核心发展方向。指令微调让VQA从单一问答任务,升级为通用多模态指令遵循任务,泛化能力与推理能力大幅提升。冻结预训练视觉/语言大模型、仅训练轻量级桥接模块,成为当前VQ

跨模态融合策略决定了多模态模型的架构效率与能力上限。早融合交互最深但成本高、对齐难;晚融合简单稳健但丢失深层关联;中融合平衡效果、效率、成本,成为约80%以上产品与论文的首选方案。在视觉-语言模型设计中,选择中融合搭配交叉注意力、适配器等轻量化机制,既能实现精准的跨模态对齐,又能满足训练与推理的工程化需求,是当前多模态感知的最优融合路线。