




- @weixin_42357472
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文记录了一个基于 FastMCP+FastAPI+SSE的旅游AI Agent在生产环境压测时遇到30-40并发容量悬崖的完整优化过程。系统采用多工具调用的架构,包含意图分类、LLM编排等功能模块。通过逐段排查,识别出四个关键瓶颈:client单worker启动方式错误、MCP Server单点瓶颈、ES同步写入等待消耗容量、nginx配置权重与容量上限不匹配。针对这些问题实施了五项优化措施:修
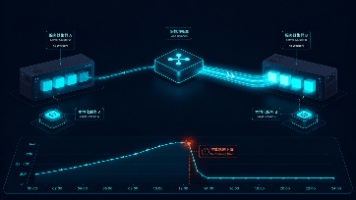
本文记录了一个基于 FastMCP+FastAPI+SSE的旅游AI Agent在生产环境压测时遇到30-40并发容量悬崖的完整优化过程。系统采用多工具调用的架构,包含意图分类、LLM编排等功能模块。通过逐段排查,识别出四个关键瓶颈:client单worker启动方式错误、MCP Server单点瓶颈、ES同步写入等待消耗容量、nginx配置权重与容量上限不匹配。针对这些问题实施了五项优化措施:修
【代码】FTP ftplib链接文件上传下载。

参考:https://blog.csdn.net/universsky2015/article/details/127181579https://blog.csdn.net/qq_39505065/article/details/107234211

import pyspark.sql.functions as Fimport pyspark.sql.types as Tfrom pyspark.sql.functions import splitfrom pyspark.sql.functions import regexp_replace, coldate_format、concat_ws、datediff** cast 时间格式转化df
1、pyspark增加config设置java heap错误增加内存2、spark-submit 参数参考:https://www.cnblogs.com/weiweifeng/p/8073553.htmlnohup spark-submit--class com.tcl.video.search.recommend.SparkQueryApplication--executor-memory 6
1、pyspark 读取与保存参考:http://www.manongjc.com/detail/15-vfxldlrjpphxldk.htmldt1 = spark.read.parquet(r'/home/Felix/pycharm_projects/test/testfile.parquet')print(dt1.show())保存的时候主要文件夹权限,不然报错ERROR FileOutpu
大数据hadoop三块***大数据可视化工具:hue1、hdfs(存储):hbase、kudu、druid等2、mapreduce(计算):hive、spark、flink、kylin、impala等3、yarn(分布式部署)1、docker 安装hadoop参考:https://github.com/kiwenlau/hadoop-cluster-dockerhttps://caidao.git
参考:https://www.cnblogs.com/maolonglong/p/12512989.html1、安装c++插件2、下载c++编译器g++下载链接:https://sourceforge.net/projects/mingw-w64/3、加压编译器并加入环境变量4、配置vscode c++编译器先创建个cpp文件#include <iostream>using names
参考 :https://blog.csdn.net/qq_35349114/article/details/1057716741、下载docker pull yandex/clickhouse-serverdocker pull yandex/clickhouse-clinet2、启动server如果想指定目录启动,这里以clickhouse-test-server命令为例,可以随意写mkdir