




- @weixin_42209537
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
举例说明SQL的抗干扰性:假设已经找到了最佳的路径,但是突然出现干扰,如果是Q-learning这种输出靠着最大Q对应的动作,那么agent就会一直在干扰处徘徊,但是SQL就会不一样,对于所有动作都会被选择到,只不过概率有高低罢了,那么当遇到干扰时,agent就有机会找到另一条合适的路径。增加信息熵项,那么优化时,就会使得输出的每一个动作的概率尽量分散,因为在一个集合中,体系越混乱,种类越趋于平均
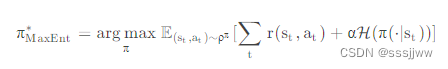
使用状态值函数和优势函数计算Q,为防止网络输出优势函数A的期望不为0,需要减去A的期望,由于动作无穷多,通过采样计算均值来估计A的期望。结合了演员-评论家方法和经验回放的算法,是一种带经验回放的off-policy的actor-critic模型,A3C是on-policy的,其实 ACER 是 A3C 的off-policy 版本。②实时学习:由于它使用当前策略的数据,因此同策略学习通常需要实时与

global network下面有n个worker线程,每个线程里有和公共的神经网络一样的网络结构,每个线程会独立的和环境进行交互得到经验数据,线程之间互不干扰,独立运行。每个线程和环境交互到一定量的数据后,就计算在自己线程里面的神经网络损失函数的梯度,但是这些梯度并不更新自己先线程里的神经网络,而是去更新公共的神经网络。A3C中可以将两个网络放到一起,输入状态s,可以输出状态价值和策略,也可以将
1、变量试图中的名称首字母:汉字、英文或@开头,变量名称不区分大小写,必须唯一。不可以用$、空格,变量名最后一个字符不可以是.和_。2、离散缺失值:在缺失那边设置,设定后,系统分析时碰到就会当作缺失值来处理。3、测量:1、度量:等距等比变量(年龄);2、有序:等级变量(大小顺序、等级、满意度);3、名义:称名变量,不能比较大小的。

年—季度—月创建分层结构,命名为中心拖动部、组、班如下图如此可以通过点击加号进行层级下钻平均呼入通话时长注:层级不可以嵌套。

一块又一块地图形成矩阵形式。

TRPO——Trust Region Policy Optimization置信域策略优化算法。②信任域约束:限制策略更新的幅度,保证算法的稳定性。①策略梯度:衡量当前策略与目标策略之间的差异。是一种改进的自然梯度策略优化算法。①性能好,能够有效学习复杂策略。②稳定性强,不易陷入局部最优。

通常可以用马尔可夫决策过程来定义强化学习任务,并将其表示为四元组,分别是状态集合、动作集合、状态转移函数和奖励函数,假设这四元中组中所有元素已知,且状态集合和动作集合在有限步数内是有限集,则机器学习可以对真实环境进行建模,通过学习状态转移函数来构建一个虚拟环境,以模拟真实环境的状态和交互和反映,这就是。然而在实际应用中,智能体并不是那么容易就能知晓马尔可夫决策过程中的所有元素的,通常情况下,状态转

GPU:图形处理单元,最初设计用于处理图像和视觉渲染任务,但随着技术的发展,GPU也被广泛用于并行计算任务,特别是在深度学习和大规模数据处理领域。通常用于执行程序的流程控制和数据处理,CPU通常包含少量的核心(通常4-32个),每个核心能够处理复杂的任务和多任务操作。CUDSS:库函数,实现矩阵分解,但是性能不是很好,性能不稳定,分解的结果很随机,无法实现多卡并联。ORLM:可以私有化部署,任何基

总体分布的卡方检验适用于配合度检验,是根据样本数据的实际频数推断总体分布与期望分布或理论分布是否有显著差异。
