




- @weixin_42001089
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
前言最近做了很多数据清洗以及摸底的工作,由于处理的数据很大,所以采用了spark进行辅助处理,期间遇到了很多问题,特此记录一下,供大家学习,。由于比较熟悉python, 所以笔者采用的是pyspark,所以下面给的demo都是基于pyspark,其实其他语言脚本一样,重在学习思想,具体实现改改对应的API即可。这里尽可能的把一些坑以及实现技巧以demo的形式直白的提供出来,顺序不分先后。有了这些d
通过本篇我们快速学习了如何使用Qwen2-VL来训练自己的业务,如果大家有类似的需求,可以动手尝试啦~,快去试试吧!咱们下期再见!
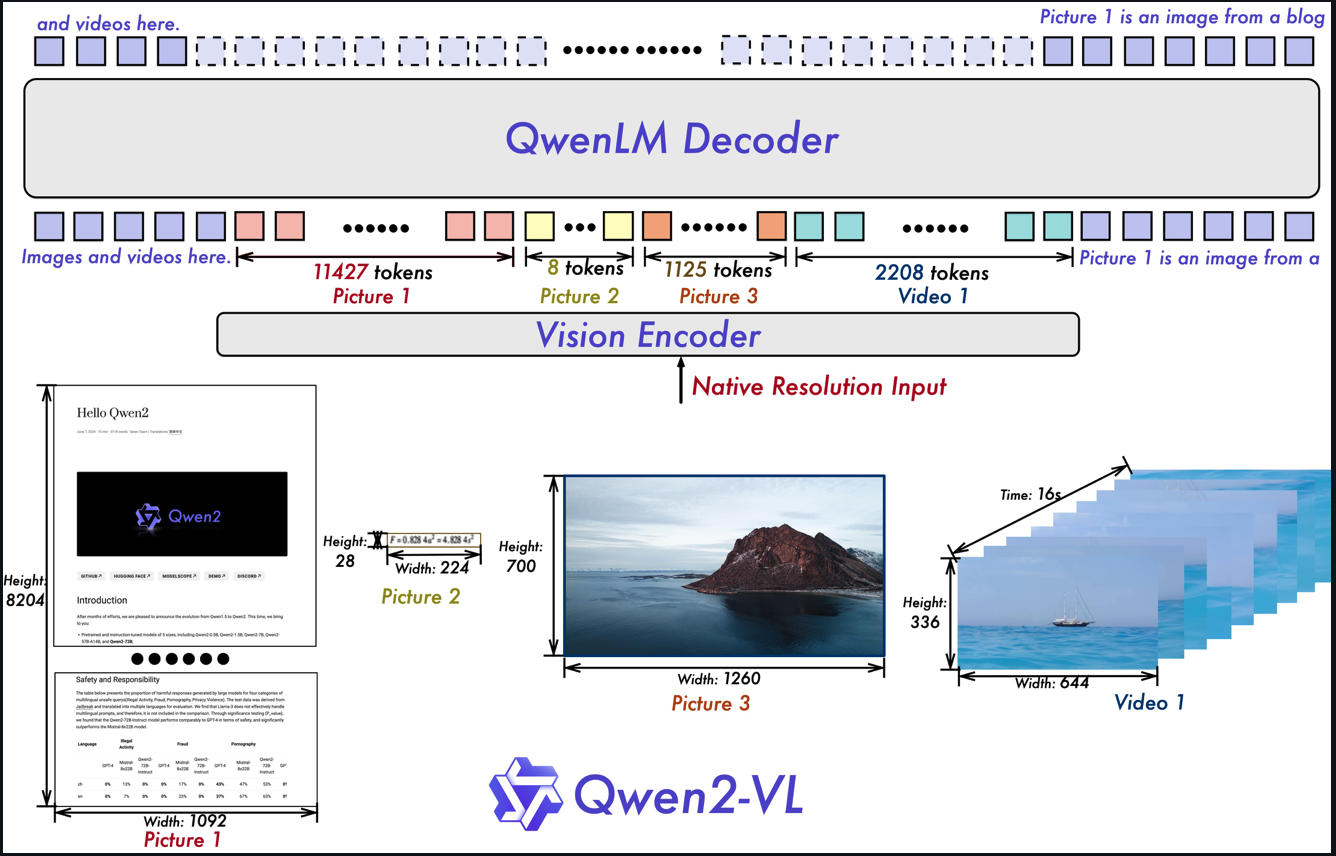
前言多模态已是当下比较热的研究方向了,基于transformer框架的预训练多模态模型也是百花齐放,比如VILBERT等等。关于当前多模态的模型,笔者之前在微信公众号写过一篇综述,感兴趣的可以看一下:多模态预训练模型综述紧跟研究热点,快来打卡多模态知识点吧~https://mp.weixin.qq.com/s?__biz=MzkzOTI4ODc2Ng==&mid=2247485865&am
(1)模态、任务的大统一是趋势,这个方向段时间内应该还会继续有很多工作,甚至把语音一款融合进来。但是大的框架应该是相同的即【输入】每个模态(任务)可能有自己对应的encoder进行分别编码【主框架】主框架应该都还是用LLM,毕竟他的推理能力强,当然这里可以有各种花样比如dense、moe等等。但大概率都是复用目前一些训练好的强大推理能力的参数【输出】每个模态(任务)可能有自己对应的encoder进
本文主要目的是通过一段及其简单的小程序来快速学习python 中sklearn的RandomForest这一函数的基本操作和使用,注意不是用python纯粹从头到尾自己构建RandomForest,既然sklearn提供了现成的我们直接拿来用就可以了,当然其原理十分重要,下面最简单介绍:集成学习是将多个模型进行组合来解决单一的预测问题。它的原理是生成多个分类器模型,各...
前言先说一下写这篇文章的动机,事情起因是笔者在使用pytorch进行多机多卡训练的时候,遇到了卡住的问题,登录了相关的多台机器发现GPU利用率均为100%,而且单卡甚至是单机多卡都没有卡住的现象,这就非常奇怪了。于是乎开始搜索相关的帖子,发现很多帖子虽然也是卡住话题,但是和笔者的情况都不一样,最后开始去查一些国外的帖子以及pytorch github issue等等,发现了类似问题,而且这个问题确

前言:情感分析也是nlp常见的任务之一,这里单独开一篇博客,来罗列一些最新的研究论文,供学习EMNLP 2021 情感分析论文汇总https://mp.weixin.qq.com/s/EA_e2LpFwxMzMgegz7Sq1A欢迎关注笔者公众号,定期更新一些工程上的trick或者前言paper以及代码解读:...
通过本篇我们快速学习了如何使用Qwen2-VL来训练自己的业务,如果大家有类似的需求,可以动手尝试啦~,快去试试吧!咱们下期再见!
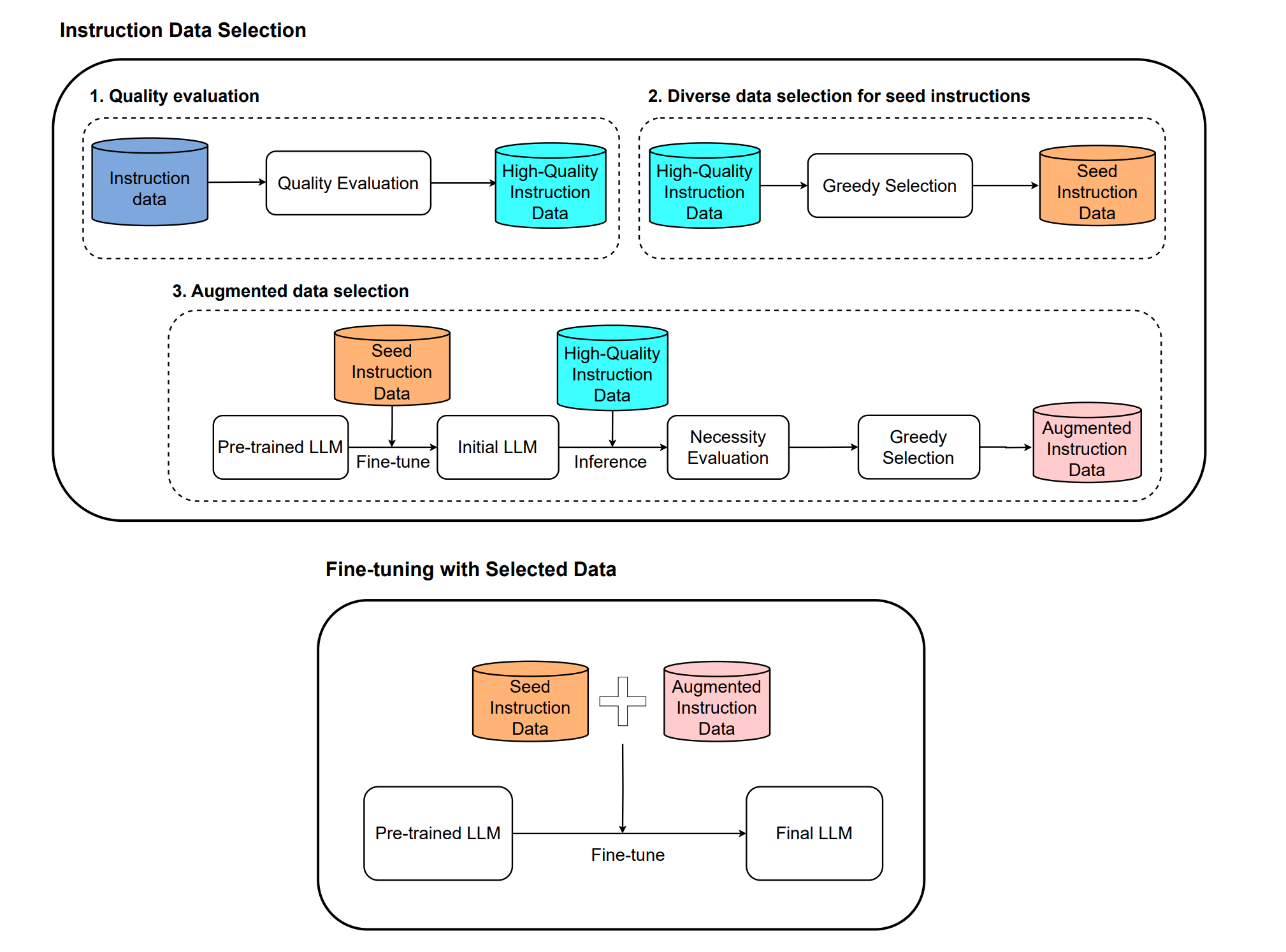
如何得到高质量的SFT数据?
前言有许多场景,我们只有少量样本,而训练网络模型时是需要吃大量数据的,一种方法就是迁移学习,比如预训练模型等方法,但是这里我们从另外一个角度来看看,那就是数据增强,关于数据增强方法已有很多,这里说说一些常见的方法,尤其是最新的(当前时间是2021.1.28)一些方法。传统常见的比如对于文本数据来说,最容易的就是shuffle, drop, 同义词替换,回译,随机插入,等等,这些都是一些最基本的方法