




- @weixin_41021342
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了三款AI芯片(AX630C、AX650N、RK1126BP)的关键参数和上市时间,重点说明了不同芯片的模型编译流程、量化方式和性能特点。其中AX630C支持W8A16量化,RK1126BP支持W4A16量化,RK182X支持多种量化配置。文章还分析了上下文长度对模型大小的影响,比较了不同芯片在小模型和大模型上的数据类型支持差异,并提供了估算大语言模型首个令牌生成时间的方法参考。

我们在 Qwen3-VL 中采取了 t,h,w 交错分布的形式,实现对时间,高度和宽度的全频率覆盖,这样更加鲁棒的位置编码能够保证模型在图片理解能力相当的情况下,提升对长视频的理解能力;这里与Qwen2-VL的不同之处在于,每个视频帧在位置编码中被视为独立的"图像",时间维度固定为0,这是由于在是预处理的时候在文本里引入了显式的时间戳,因此不需要处理动态变化的时间维度。论文的模型能够处理4倍多的视
本文介绍了三款AI芯片(AX630C、AX650N、RK1126BP)的关键参数和上市时间,重点说明了不同芯片的模型编译流程、量化方式和性能特点。其中AX630C支持W8A16量化,RK1126BP支持W4A16量化,RK182X支持多种量化配置。文章还分析了上下文长度对模型大小的影响,比较了不同芯片在小模型和大模型上的数据类型支持差异,并提供了估算大语言模型首个令牌生成时间的方法参考。
关于tinyBERT论文的解读已经有很多文章了,本文仅仅说明数据增强的步骤。
本文说明了 如何对大型语言模型LLMs部署, 常见指标和参数 进行基准测试,以及测试的步骤。使用本指南,LLM应用程序开发人员和企业系统所有者将能够回答以下问题:测量LLM推理延迟和吞吐量最重要的指标是什么?针对LLMs应该使用什么基准测试工具?它们之间的主要区别是什么?如何使用来测试LLM应用程序的延迟和吞吐量?过去几年见证了生成式人工智能和大型语言模型LLMs的普及,作为更广泛的人工智能革命的
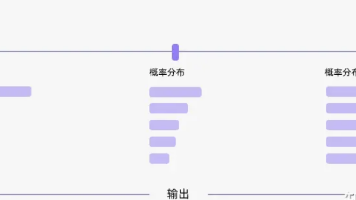
摘要:本文系统介绍了自然语言生成中的多种采样策略。核心方法包括:1)贪心搜索(高效但缺乏多样性);2)集束搜索(保留多个候选序列,平衡质量与效率);3)Top-k采样(前k个候选随机选择);4)Top-p采样(动态候选集)。重点分析了vLLM框架的参数设置技巧,如temperature调节质量/多样性平衡,length_penalty控制生成长度,以及repetition_penalty避免重复。
国内语音合成服务提供商语音合成简称TTS,以下是语音合成公司清单阿里云 标贝科技 思必驰 京东 腾讯云 云知声 科大讯飞 百度开放平台 捷通华声2. 国外语音合成服务提供商微软:提供英文,中文,中英文混合亚马逊:支持多语言3. 国内各大厂商定价对比猎户星空不提供TTS服务腾讯云内测期间,暂时未公开报价...
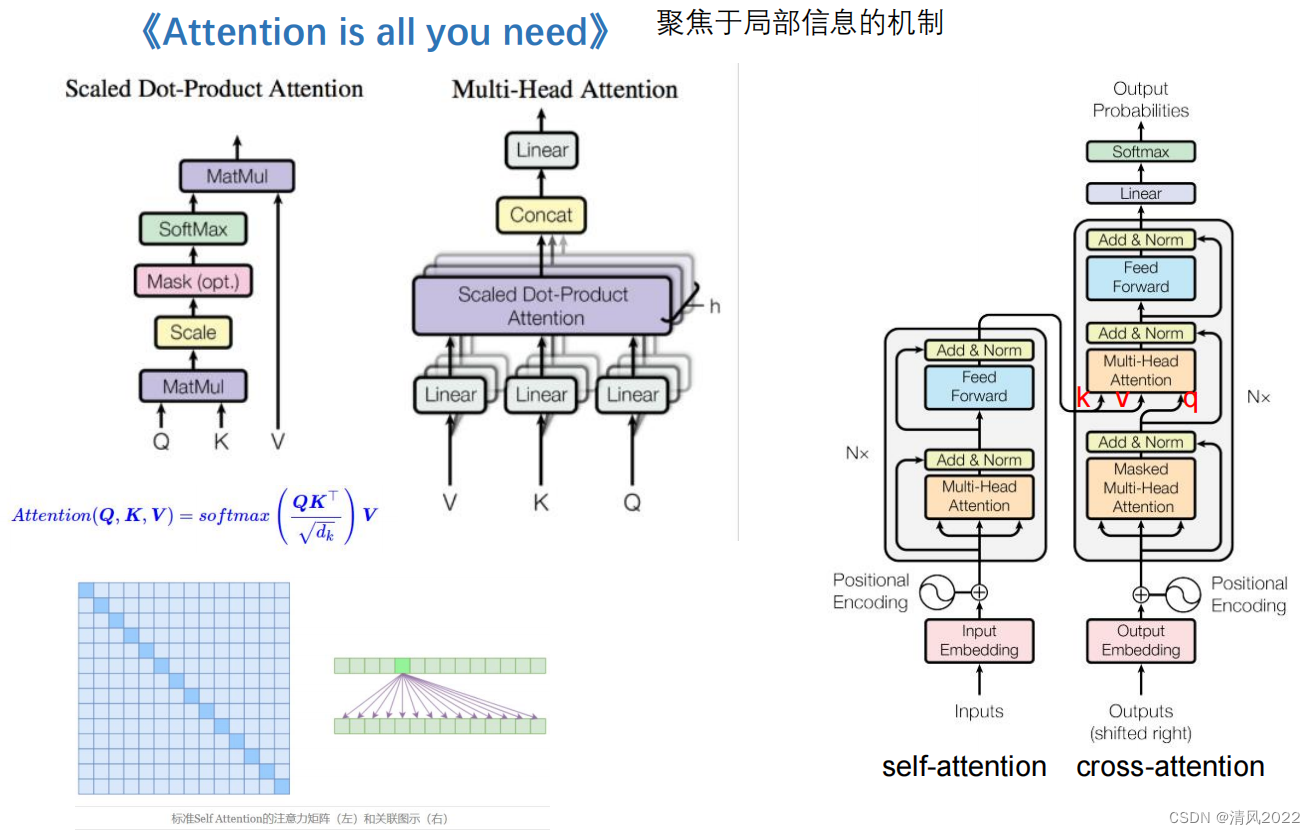
注意力机制,Attention
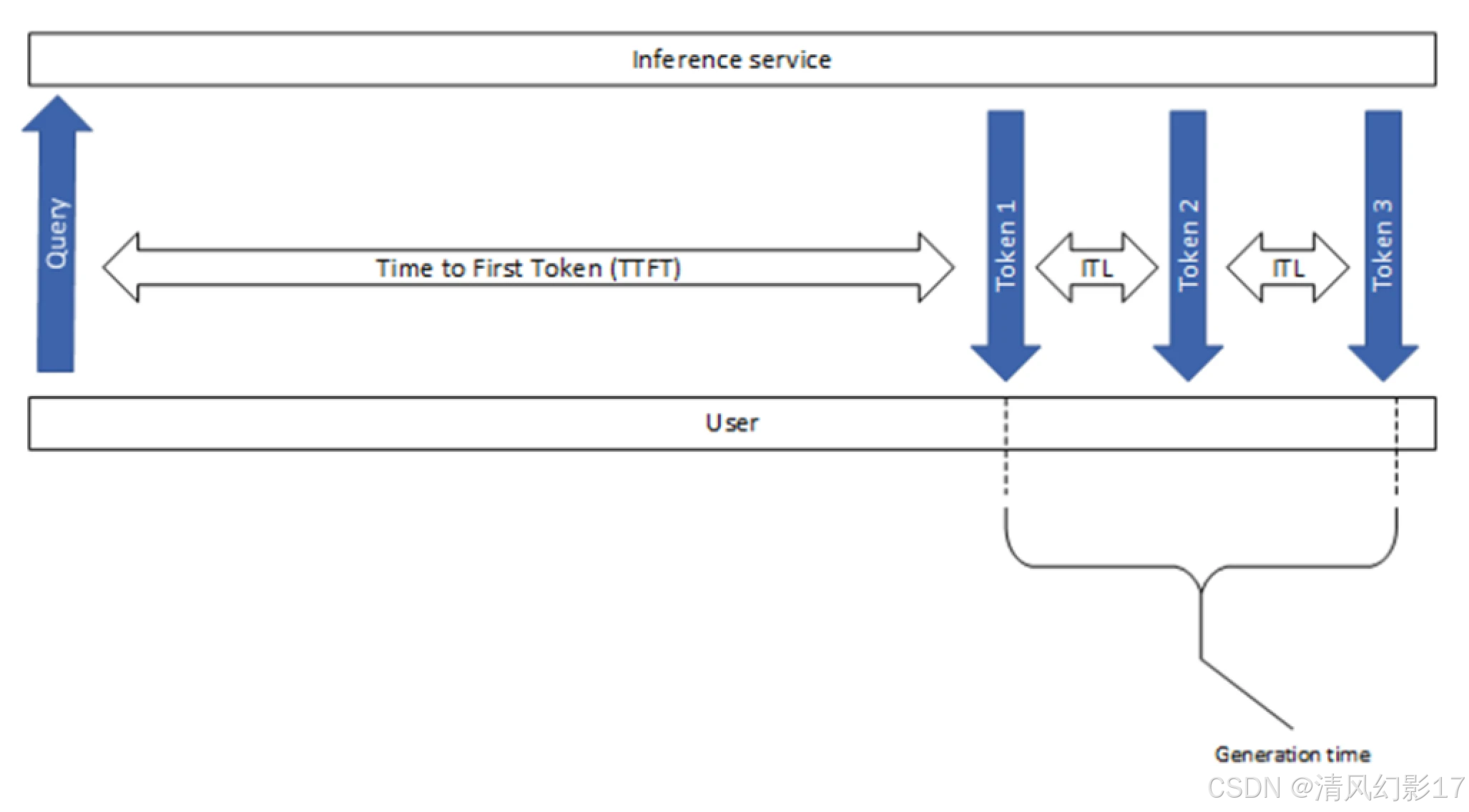
本文说明了 如何对大型语言模型LLMs部署, 常见指标和参数 进行基准测试,以及测试的步骤。使用本指南,LLM应用程序开发人员和企业系统所有者将能够回答以下问题:测量LLM推理延迟和吞吐量最重要的指标是什么?针对LLMs应该使用什么基准测试工具?它们之间的主要区别是什么?如何使用来测试LLM应用程序的延迟和吞吐量?过去几年见证了生成式人工智能和大型语言模型LLMs的普及,作为更广泛的人工智能革命的
本文说明了 如何对大型语言模型LLMs部署, 常见指标和参数 进行基准测试,以及测试的步骤。使用本指南,LLM应用程序开发人员和企业系统所有者将能够回答以下问题:测量LLM推理延迟和吞吐量最重要的指标是什么?针对LLMs应该使用什么基准测试工具?它们之间的主要区别是什么?如何使用来测试LLM应用程序的延迟和吞吐量?过去几年见证了生成式人工智能和大型语言模型LLMs的普及,作为更广泛的人工智能革命的