




- @weixin_39589455
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要 GitHub已停止支持账号密码的HTTPS推送方式。本文介绍了使用SSH密钥进行长期推送的解决方案:1) 使用ssh-keygen命令生成ED25519算法密钥;2) 将公钥添加到GitHub账户的SSH设置中;3) 通过ssh -T命令测试连接;4) 首次推送时使用git push -u origin master建立分支关联。该方法比传统RSA更安全高效,配置成功后无需每次输入密码,后续
这个错误表明Git客户端无法通过443端口连接到GitHub服务器,通常是由于网络连接问题、代理配置问题或DNS解析问题导致的。方案:配置Git代理。
将里面的内容复制,进入你的github账号,在settings下,SSH and GPG keys下new SSH key,title随便取一个名字,然后将id_rsa.pub里的内容复制到Key中,完成后Add SSH Key。提示:Hi xxx!改为自己的邮箱即可,途中会让你输入密码啥的,不需要管,一路回车即可,会生成你的ssh key。(如果重新生成的话会覆盖之前的ssh key。6.最后一

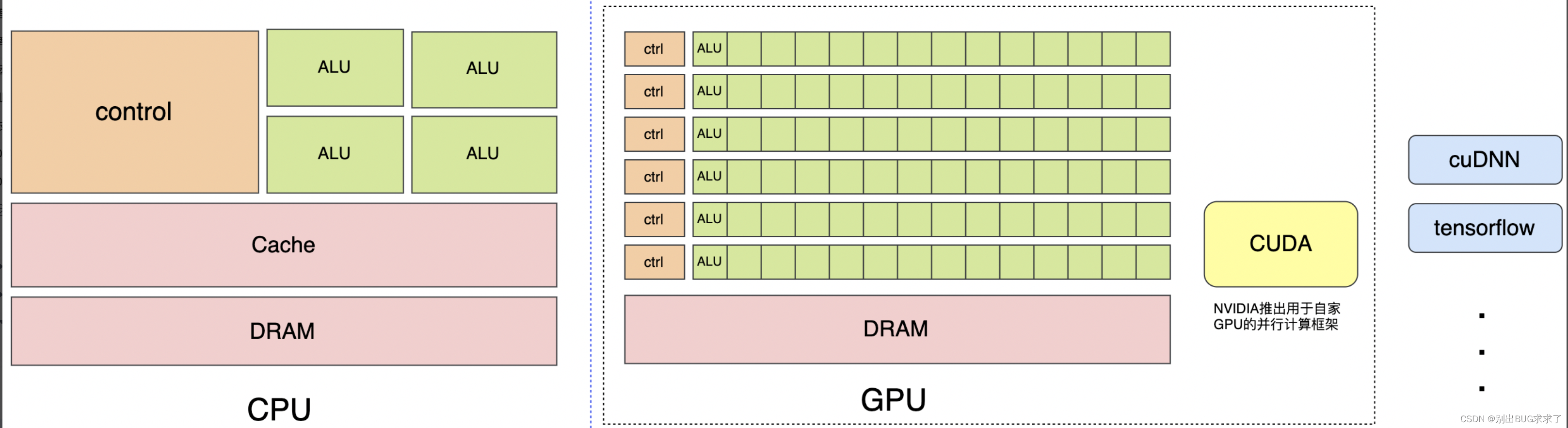
TensorFlow 在新款 NVIDIA Pascal GPU 上的运行速度可提升高达 50%,并且能够顺利跨 GPU 进行扩展。如今,训练模型的时间可以从几天缩短到几小时TensorFlow 使用优化的 C++ 和 NVIDIA® CUDA® 工具包编写,使模型能够在训练和推理时在 GPU 上运行,从而大幅提速TensorFlow GPU 支持需要多个驱动和库。为简化安装并避免库冲突,建议利用
计算机网络体系结构中的物理层、数据链路层以及网络层它们共同解决了将主机通过异构网络互联起来所面临的问题,实现了主机与主机的通信。但实际上在计算机网络中进行通信的真正实体是位于通信两端主机中的进程。如何为运行在不同主机上的应用进程提供直接的通信服务是运输层的任务,运输层协议又称为端到端的协议。运输层向高层用户屏蔽了下面网络核心的细节,它使应用进程看见的就好像是在两个运输层实体之间有一条端到端的逻辑通

注意miDebuggerPath这一项也要把路径改成刚才g++的安装路径:找到刚刚的安装文件夹->MinGW->bin->gdb,exe ,然后复制或者手动把gdb.exe的路径敲上去,格式要跟上面代码段一样。注意compilerPath这一项要把路径改成刚才g++的安装路径:找到刚刚的安装文件夹->MinGW->bin->g++,exe ,然后复制或者手动把g++.exe的路径敲上去,格式要跟上

可以通过pip直接下载,授权本人的百度云账号后,就可以直接使Linux电脑本地文件与百度网盘的apps(我的应用数据)/bypy目录下的文件进行上传与下载的交互了。本文简单介绍其相关的使用方式,仅限于命令行使用。在Python程序中的调用请另行查阅。
2. 查看已创建的虚拟环境3. 修改某个虚拟环境的名字anaconda中没有重命名的命令,使用克隆删除的方法4. conda的环境管理5. anaconda的包管理,类似Python的pipconda将conda、python等都视为package,因此可以使用conda管理conda和python的版本6. 安装需要的包安装指定版本的包
目标检测是计算机视觉上的一个重要任务,下面这篇文章主要给大家介绍了关于Yolov5训练意外中断后如何接续训练的相关资料,文中通过实例代码介绍的非常详细,需要的朋友可以参考下操作系统:Ubuntu20.04CUDA版本:11.4Pytorch版本:1.9.0TorchVision版本:0.7.0IDE:PyCharm硬件:RTX2070S*2在训练YOLOv5时由于数据集很大导致训练时间十分漫长,这
在推理的协同工作中,可能需要将中间层的输出传输给其他设备进行计算,此时则需要计算中间层输出的图像尺寸 进而计算中间输出的大小,以计算其传输的时间和速度。