




- @weixin_37958272
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
fill:#333;color:#333;color:#333;fill:none;敏捷开发方法XPCrystalScrumASDAgileUP严格流程, 适应性灵活适配, 以人为本迭代增量, 自组织动态适应, 试错学习轻量UP, 结构化迭代。
随机梯度下降算法SGD参考:为什么说随机最速下降法 (SGD) 是一个很好的方法?假如我们要优化一个函数f(x)f(x)f(x) ,即找到它的最小值,常用的方法叫做 Gradient Descent (GD),也就是最速下降法。说起来很简单, 就是每次沿着当前位置的导数方向走一小步,走啊走啊就能够走到一个好地方了。如上图, 就像你下山一样,每一步你都挑最陡的路走,如果最后你没摔死的话,一般你很快就
强化学习介绍从本质上看,强化学习是一个通用的问题解决框架,其核心思想是 Trial & Error。强化学习可以用一个闭环示意图来表示强化学习四元素策略(Policy):环境的感知状态到行动的映射方式。反馈(Reward):环境对智能体行动的反馈。价值函数(Value Function):评估状态的价值函数,状态的价值即从当前状态开始,期望在未来获得的奖赏。环境模型(Model):模拟环境
强化学习AC、A2C、A3C算法
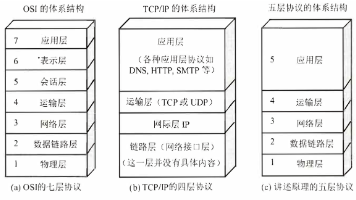
计算机网络性能与体系结构摘要 网络分类: LAN(建筑级):高速(Gbps)、低延迟,采用以太网/WiFi MAN(城市级):光纤/MPLS技术,中高速(Mbps~Gbps) WAN(广域):高延迟,依赖运营商(SDH/MPLS),成本高 性能指标: 速率/带宽(bit/s)、吞吐量(实际传输量) 时延=发送时延+传播时延+处理/排队时延 时延带宽积=传播时延×带宽(信道容量指标) 体系结构: 物
使用动量(Momentum)的SGD、使用Nesterov动量的SGD参考:使用动量(Momentum)的SGD、使用Nesterov动量的SGD一. 使用动量(Momentum)的随机梯度下降虽然随机梯度下降是非常受欢迎的优化方法,但其学习过程有时会很慢。动量方法旨在加速学习(加快梯度下降的速度),特别是处理高曲率、小但一致的梯度,或是带噪声的梯度。动量算法累积了之前梯度指数级衰减的移动平均,并
Sub-center ArcFace: Boosting Face Recognition by Large-scale NoisyWeb FacesMargin-based的深度人脸识别方法(如SphereFace、CosFace和ArcFace)在无约束的人脸识别中取得了显著的成功。然而,这些方法容易受到训练数据中大量标签噪声的影响,因此需要费力的人力来清理数据集。在本文中,我们放宽了ArcF
CBAM我们提出了卷积块注意力模块(CBAM),这是一个简单而有效的前馈卷积神经网络的注意力模块。给定一个中间特征图,我们的模块沿着通道和空间两个独立的维度依次推导注意力图,然后将注意力图乘以输入的特征图,进行自适应的特征细化。由于CBAM是一个轻量级的通用模块,它可以无缝集成到任何CNN架构中,开销可以忽略不计,并且可以和基础CNN一起进行端到端训练。我们通过在ImageNet-1K、MS CO
Neural Machine Translation by Jointly Learning to Align and Translate神经机器翻译是最近提出的一种机器翻译方法。与传统的统计机器翻译不同,神经机器翻译的目的是建立一个单一的神经网络,可以共同调整,使翻译性能最大化。最近提出的神经机器翻译的模型通常属于编码器-解码器家族,并将源句编码成一个固定长度的向量,解码器从中生成译文。在本文中
Playing Atari with Deep Reinforcement Learning我们提出了第一个利用强化学习直接从高维感官输入成功学习控制策略的深度学习模型。该模型是一个卷积神经网络,用Q-learning的一个变种进行训练,其输入是原始像素,其输出是一个估计未来奖励的价值函数。我们将我们的方法应用于街机学习环境中的七个Atari 2600游戏,没有调整结构或学习算法。我们发现,它在其