- @weixin_36488653
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
【代码】鸿蒙HarmonyOS NEXT 5.0开发(2)—— ArkUI布局&组件。

这篇文章是北航提出的一篇预测论文,在实际预测过程中,大多数需要基于长期的数据,否则根据短期数据预测出来的结果是不置信的,近年来的研究表明,transformer在时序序列预测上的潜力。
文章目录Vocoder1. Spectrogram2. Neural Vocoder2.1 WaveNet2.2 FFTNet2.3 WaveRNN2.4 WaveGlowVocodervocoder就是通过模型或方法将语音特征转换成对应的声音信号。1. Spectrogram频谱图的计算过程如下,和振幅相位有关,一段完整的声音包含振幅和相位的信息,因此要还原出原始声音不能仅包含频率信息,还应该包
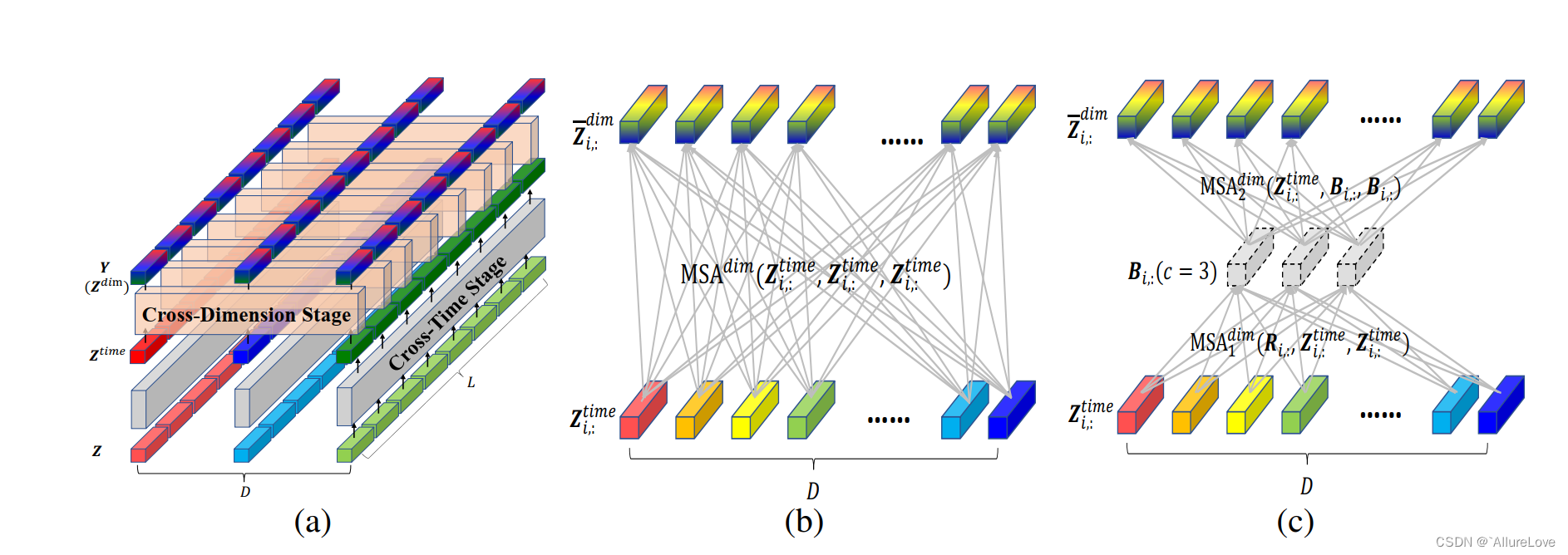
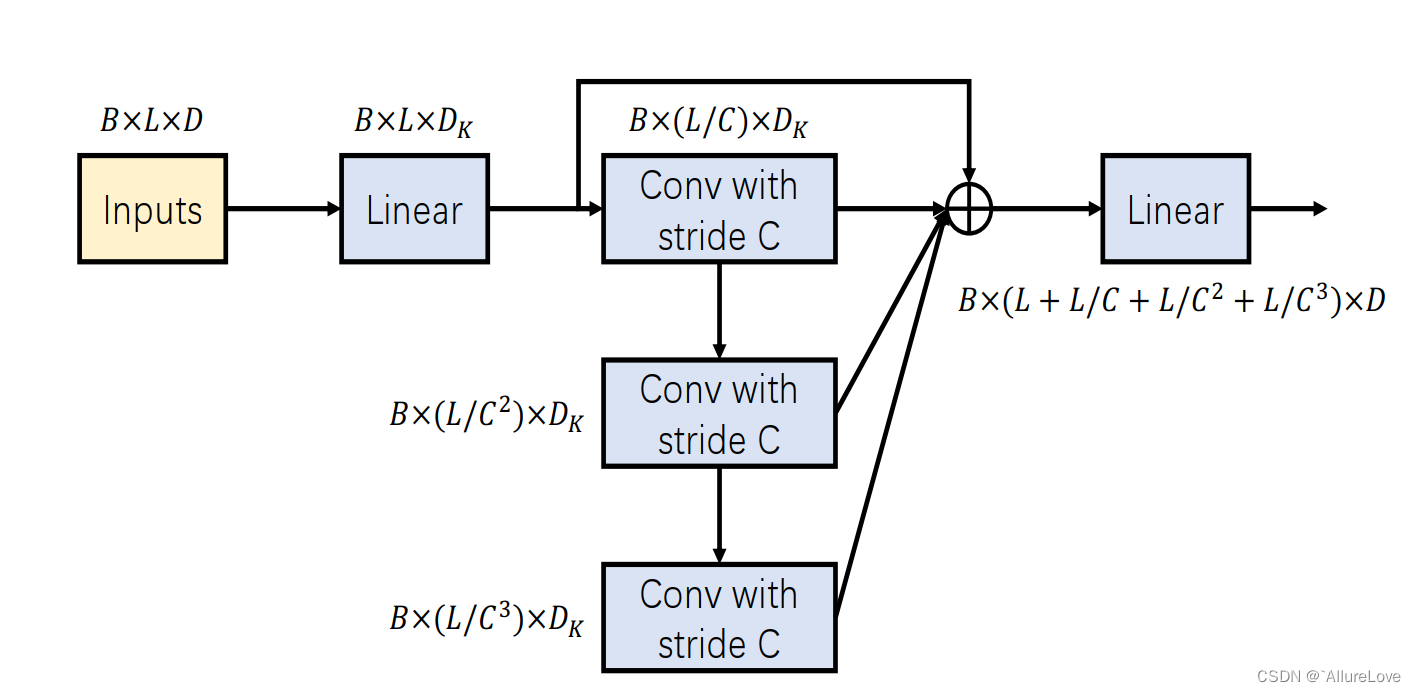
多层级Encoder-Decoder:由于上一步会进行two-stage的注意力运算,因此在Decoder中会分别对不同阶段的结果进行解码,模型的输入最开始是细粒度patch,随着层数增加逐渐聚合成更粗粒度的patch。Dimension-Segment-Wise Embedding:对于多维时间序列,应该对每个维度的数据进行单独的数据表征,而不是在每个点位基于所有维度的数据进行数据表征,因此本文
Transformer笔记一、Transformer概览二、Encoder详解三、Decoder详解本文是根据哔哩哔哩up主视频讲解所写,加入了一些个人理解。视频地址:Transformer从零详细解读一、Transformer概览Transformer最初用于机器翻译,具体功能可以看成:进一步细分:再进一步细分:Encoder-Decoder结构,多个Encoder和Decoder个数可以自行设
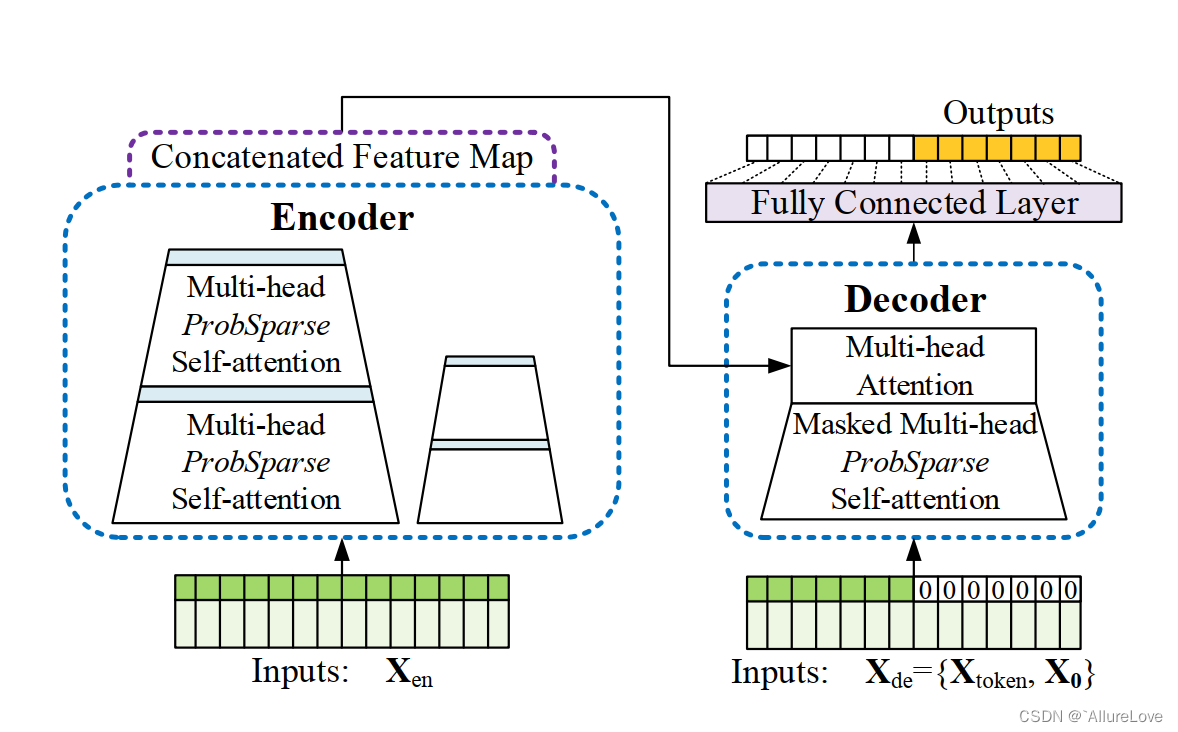
本文是上海交通大学的团队发表的,背景仍然是如何降低计算复杂度&更好地进行长期依赖性关系的表征。
文章目录Speech Separation1. Evaluation1.1 Signal-to-noise ratio(SNR)1.2 Scale invariantsignal-to-distortion ratio(SI-SDR)2. Deep Clustering2.1 Masking3. Permutation Invariant Triaining(PIT)4. TasNet - Tim
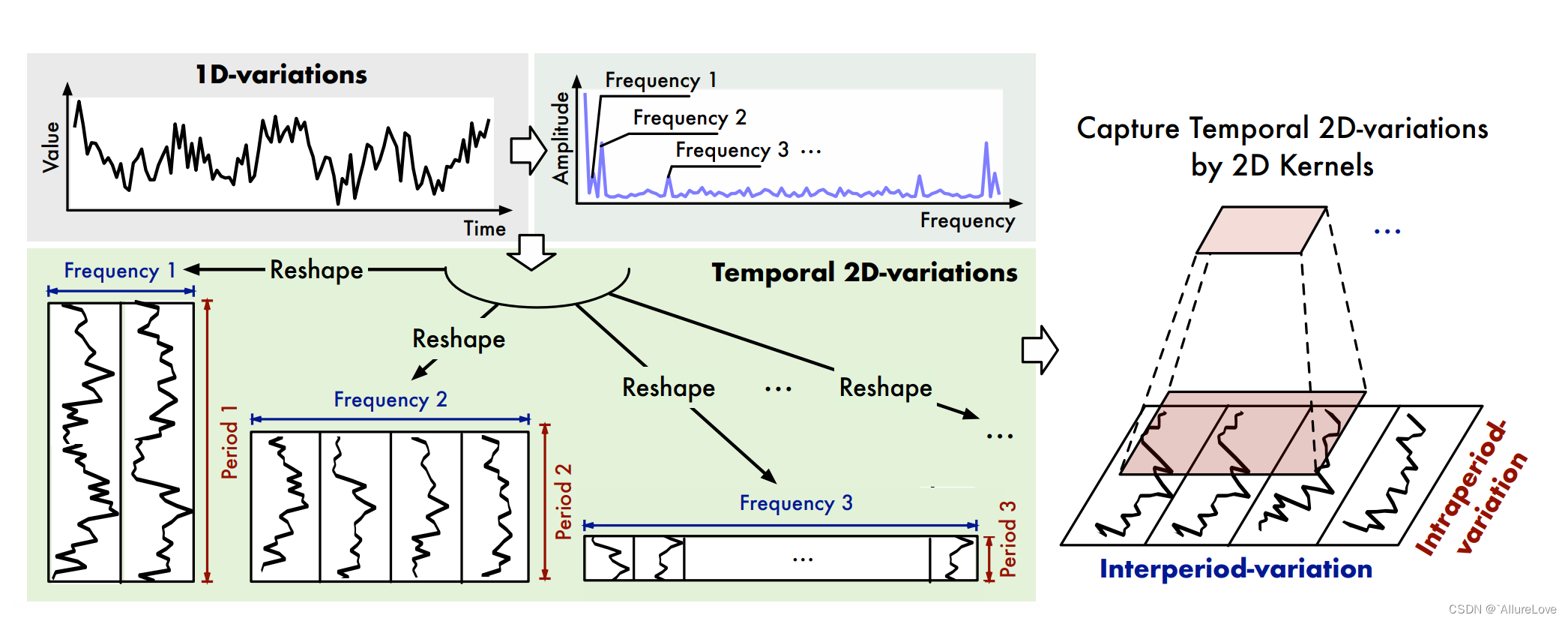
基于深度学习的异常检测-TimesNet
文章目录1. 语音识别概述1.1 Token的表示1.2 Acoustic Feature2. 语音识别深度学习模型2.1 Listen,Attend,and Spell(LAS)2.2 CTC2.3 RNN-T2.4 Neural Transducer2.5 MoChA3. 语音识别传统模型3.1 隐马尔可夫模型3.2 Tandem3.3 DNN-HMM Hybrid4. alignmentB站
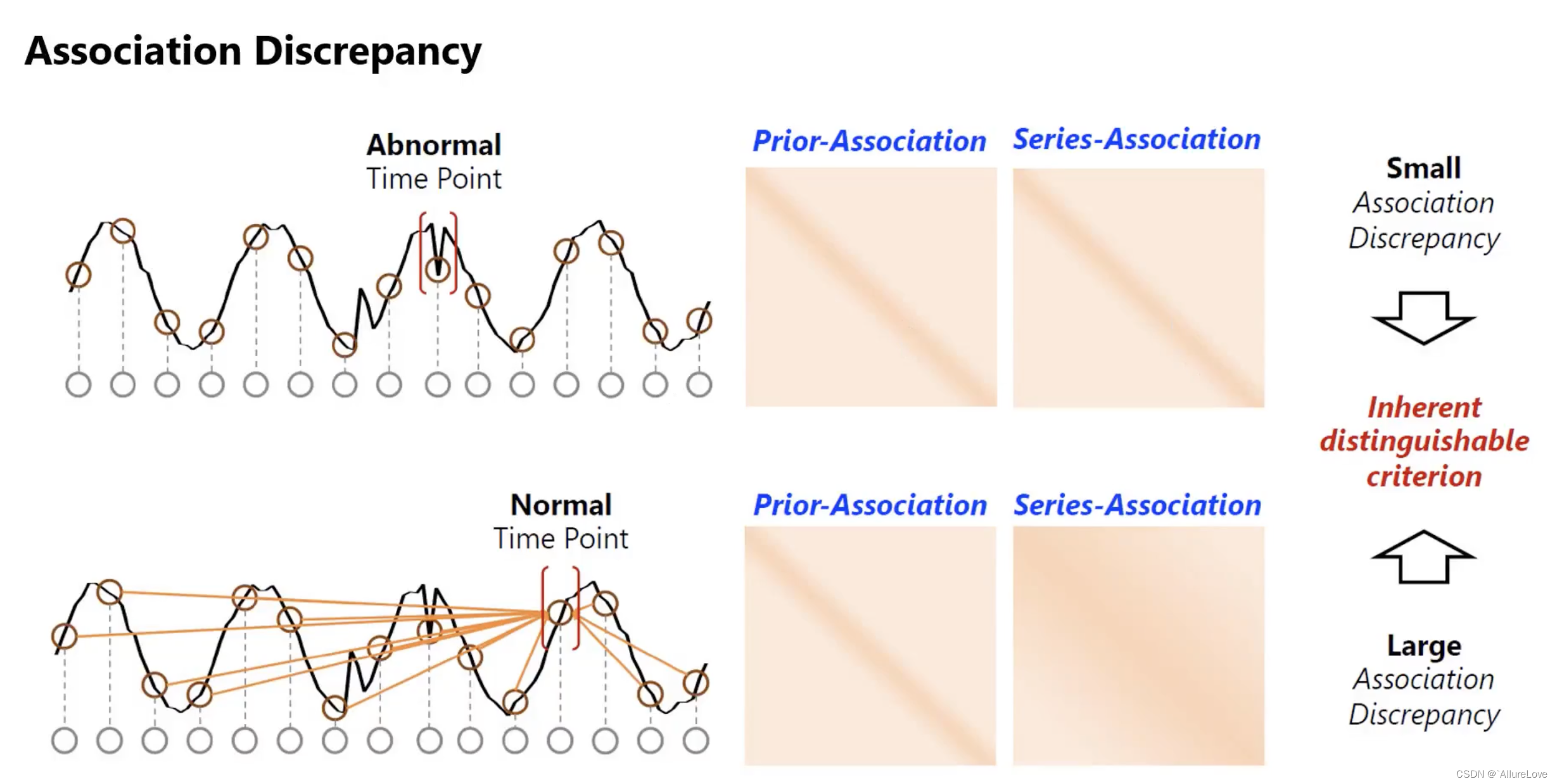
基于深度学习的异常检测:Anomaly Transformer