
写文章




- @u013699308
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
32个Java面试必考点-08高并发架构基石-缓存
运行一段时间后,用户信息增加了一个属性,单个对象的大小变成了 500 字节,这时再保存对象需要使用 768 字节的 Slab,而 MC中的容量大部分创建了 384 字节的 Slab,所以 768 的 Slab 非常少。不管是本地缓存还是分布式缓存,为了保证较高性能,都是使用内存来保存数据,由于成本和内存限制,当存储的数据超过缓存容量时,需要对缓存的数据进行剔除。本地缓存就是在进程的内存中进行缓存,
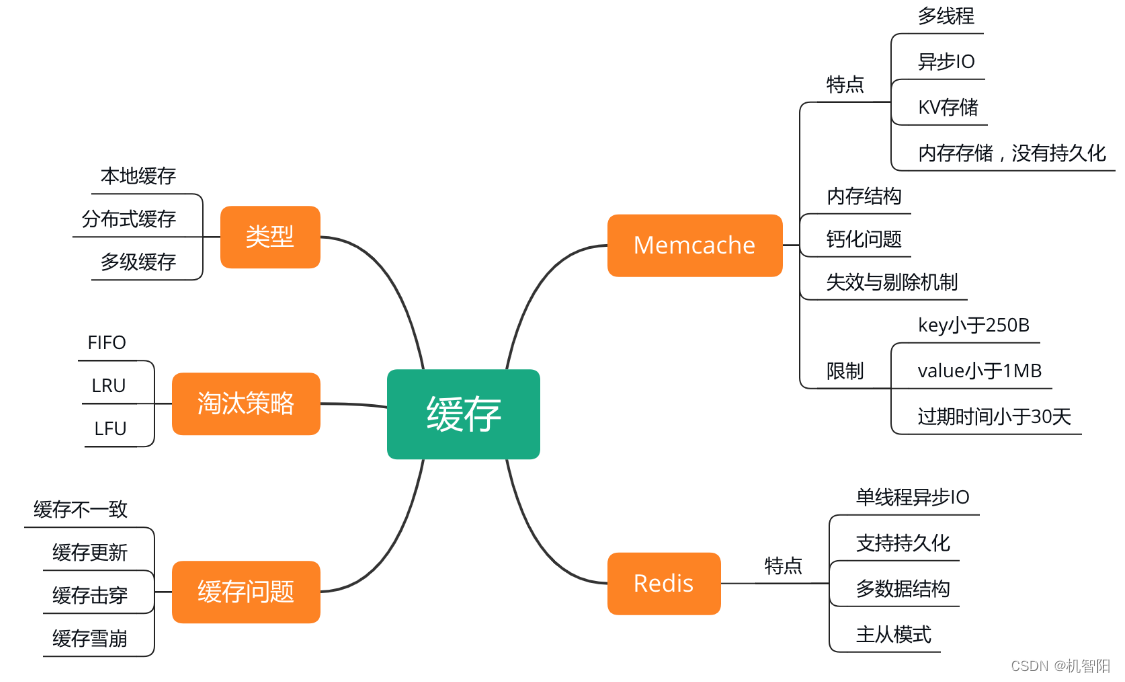
300分钟吃透分布式缓存-24讲:Redis崩溃后,如何进行数据恢复的?
这样即便 Redis 被 crash 或异常关闭后,再次启动,也可以通过加载 AOF,来恢复最新的全量数据,基本不会丢失数据。但是,由于 Redis 会记录所有写指令操作到 AOF,大量的中间状态数据,甚至被删除的过期数据,都会存在 AOF 中,冗余度很大,而且每条指令还需通过加载和执行来进行数据恢复,耗时会比较大。随着时间的推移,AOF 持续记录所有的写指令,AOF 会越来越大,而且会充斥大量的
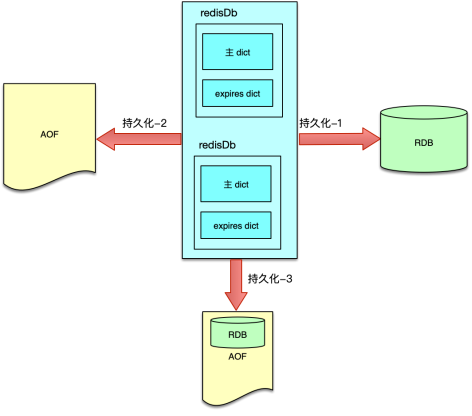
DevOps落地笔记-18|团队能力:团队能力=交付能力
不同于上层应用程序的部署,私有云的部署是需要从操作系统开始安装,还会涉及改交换机的网卡,规划网络的 Vlan 范围,规划分布式存储的存储池等,这些都需要非常底层的专业知识,哪怕一个小问题都会影响整个云的部署和业务的可用性。我们都知道,软件开发是团队成员完成的,团队成员的能力在一定程度上代表了软件的交付能力。在搭建部署流水线的过程中,遇到过非常多的底层问题,当遇到问题时只能求助基础设施团队的专业同事
到底了