




- @u012946256
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
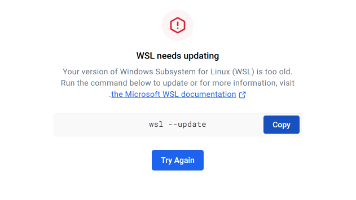
最近在本地Windows电脑,使用Docker Compose本地部署开源AI应用平台Dify。原本以为跟着官方文档几分钟就能搞定,结果全程连环踩坑不断:Docker启动WSL更新失败、Git命令无法识别、源码克隆卡住、自己改配置越改越崩、80端口占用打开Nginx默认页、杀完端口进程Docker反而起不来等一系列问题。本文严格按照我本人真实操作先后顺序完整复盘。
React+TS前端面试题集锦摘要: React核心与Hooks部分: 介绍React 18.x关键特性及常用UI库(Ant Design、Material-UI等) 详解useState、useEffect等基础Hooks及useMemo、useCallback优化技巧 分析自定义Hooks数据隔离问题及共享解决方案 解释"闭包陷阱"现象及其防范措施 附带组件封装思路、性能优
这篇指南系统性地介绍了提示词(Prompt)的设计策略与应用方法。主要内容包括: 提示词基础:定义提示词为与大模型交互的输入内容,强调其质量直接影响输出结果,学习提示词设计能显著提升工作效率。 核心策略: 按任务复杂度设计提示词 采用迭代优化原则 运用分隔符和占位符结构化内容 明确执行步骤和参考示例 拆分复杂任务和分段处理长文本 五大实用模板:详细介绍了3WEH、QBR、GCE、STAR和定位-现
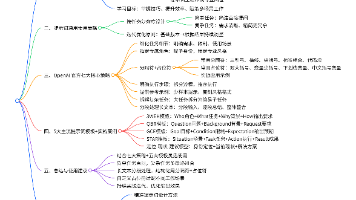
DeepSeek 模型技术解析(精简版) 核心架构:采用MOE混合专家架构(任务拆分+专家协同)和MLA多头潜在注意力(分组处理降算力),实现高效推理与长文本处理。 双模型对比: V3:通用生成型,响应快,适配多轮对话/代码生成 RE:深度推理型,擅长逻辑推演,但速度慢且稳定性较差 蒸馏技术:通过师生模型架构,利用大模型API生成训练数据,低成本产出轻量化模型(1.5B-14B),支持本地部署。
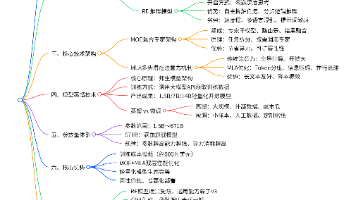
DeepSeek 模型技术解析(精简版) 核心架构:采用MOE混合专家架构(任务拆分+专家协同)和MLA多头潜在注意力(分组处理降算力),实现高效推理与长文本处理。 双模型对比: V3:通用生成型,响应快,适配多轮对话/代码生成 RE:深度推理型,擅长逻辑推演,但速度慢且稳定性较差 蒸馏技术:通过师生模型架构,利用大模型API生成训练数据,低成本产出轻量化模型(1.5B-14B),支持本地部署。