




- @tianjuewudi
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
数据结构,编程基础,找工作必备,提升代码上限
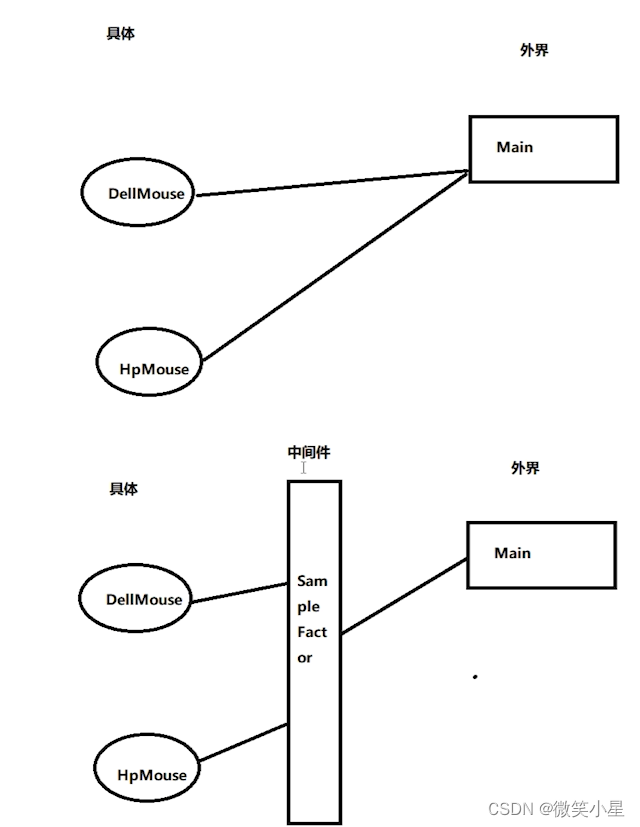
本文的代码基于书本《机器学习实战》概念k-近邻算法采用测量不同特征值之间距离的方法进行分类。工作原理是:存在一个样本数据集合,称作训练样本集,样本中每个数据都存在标签。输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,算法提取样本集中特征最相似数据(最近邻)的分类标签,我们只选择样本数据集中前k个最相似的数据,使用的是欧式距离的计算公式,通常k是不大于20的整数,选择k个
首先,傅里叶分析是指把一个周期或非周期函数展开成一个个三角函数的叠加,如果是对其还没有基本概念的,可以看看傅里叶分析之掐死教程,这篇文章不依赖数学公式却又十分透彻地讲述了傅里叶分析的基本概念,十分值得一读。但如果先深入探讨其中的数学由来,接下来会讲述详细的数学推导。傅里叶级数三角函数系的正交性三角函数系:{1,sinx,cosx,sin2x,cos2x,…,sinnx,cosnx,…},它由无数个
D4PG全称Distributed Distributional Deterministic Policy Gradient,是总所周知的DDPG的分布式版本。因此学习D4PG之前,需要了解DDPG。首先DDPG是DQN在连续空间的版本,DQN只能处理离散动作空间的问题,对于连续动作空间是无法处理的,因此我们引入了DDPG。DDPG是actor-critic的结构,并且借鉴了DQN的技巧,也就是目
阅读本文前可以先了解我前三篇文章《强化学习之DQN》《强化学习之DDQN》、《强化学习之 Dueling DQN》。Rainbow结合了DQN算法的6个扩展改进,将它们集成在同一个智能体上,其中包括DDQN,Dueling DQN,Prioritized Replay、Multi-step Learning、Distributional RL、Noisy Net。加上原版的DQN,凑齐七种因素,召
参考视频:李宏毅强化学习系列参考论文:Large-Scale Study of Curiosity-Driven LearningCuriosity-driven Exploration by Self-supervised PredictionCuriosity-driven Exploration for Mapless Navigation with Deep Reinforcement L
论文原文:Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments论文翻译:MADDPG翻译阅读本文需要强化学习基础,可以参考我前面的文章:多智能体强化学习入门关于MADDPG强化学习算法的基础DDPG的可以查看我的文章:强化学习实践教学对于MADDPG推荐的博客有:探秘多智能体强化学习-MADDPG算法原理及简