- @sunghosts
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
https://blog.csdn.net/weixin_44344462/article/details/89337770https://scikit-learn.org.cn/view/74.html
转:https://blog.csdn.net/qq_33876194/article/details/98943383自回归根据上文内容预测下一个可能跟随的单词,就是常说的自左向右的语言模型任务,或者反过来也行,就是根据下文预测前面的单词,这种类型的LM被称为自回归语言模型。(GPT,ELMO)GPT 就是典型的自回归语言模型。ELMO尽管看上去利用了上文,也利用了下文,但是本质上仍然是自回归L
调研可供选择的方案并不多,解决思路可以分成两类。一类是直接使用工具将pdf转成word,另一类是先用工具将pdf中的内容提取出来,再使用其他工具将内容创建到新的word中。目前,着重尝试了第一类方案。第一类方案中最流行的方法是使用pdfbox工具包,另一种方法是使用COM技术,利用java调用windows平台的COM组件完成转换。第一种方法完全使用java库,没有平台限制,第二种方法则依赖于wi
转:https://www.cnblogs.com/herosoft/p/8294856.htmlpom.xml文件中增加:<dependency><groupId>com.hankcs</groupId><artifactId>hanlp</artifactId><scope>system</scope><
Python Mysql开发有使用原生SQL语言和ORM框架两种方式。下面介绍下其中涉及到的知识点。Python连接mysql的驱动包python的mysql驱动包常用的有三个,分别是: pymysql, mysql-connector, MySQLdb。三个包都遵循PEP 249使用方式大同小异。mysql-connector 是 MySQL 官方提供的驱动器, 它在Python中重新实现MyS
大部分情况下,我们不需要关注背后具体所选择的kernel,因为它背后已经做了最优的选择。V100卡属于sm 7.0,不支持Flash attention,但是我们可以看到默认采用的kernel是sdpd_mem_eff,它相比sdpd_math,速度提升非常明显(6ms vs 16ms)。这里我在batch_size=8下,跑出来运行时间大约是16s(A100下是6.6s),而只采用SDPA的版本

转:https://zhuanlan.zhihu.com/p/343529491有些可视化以及清晰的见解来自ICLR 2020: Yann LeCun and Energy-Based Models。所谓的能量模型并不是一种新的技术,而是LeCun的一种尝试:将当前的DL,ML统一在能量模型的框架中。我们先理解一下何为能量函数,能量函数通常写作 E(x,y)E(x, y)E(x,y) 用于衡量 x
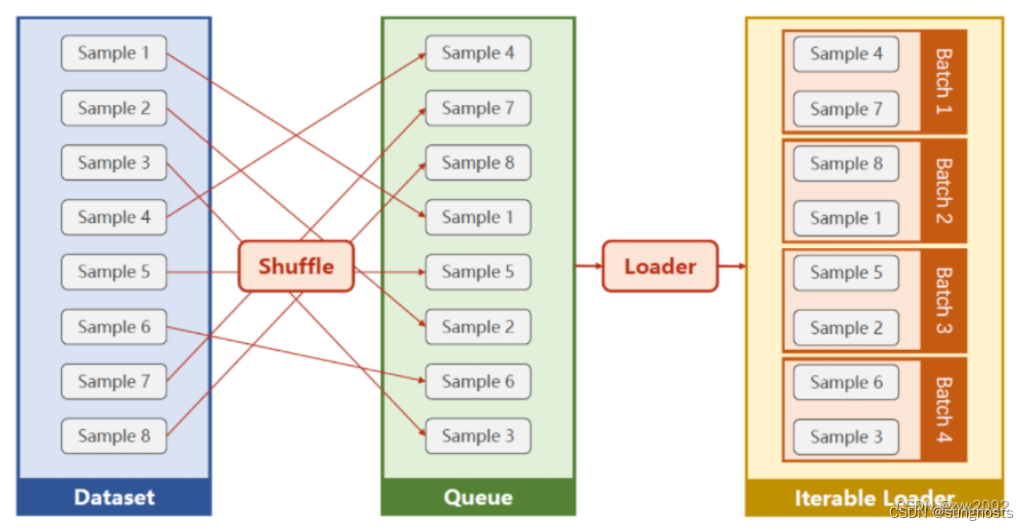
Pytorch中的Dataset和Dataloader。Dataset允许你自定义自己的数据集,用来存储样本及其对应的标签。而Dataloader则是在Dataset的基础上将其包装为一个可迭代对象,以便我们更方便地(小批量)访问数据集。Data SizeBatch SizeIterationEpochDataLoader到这里应该就PyTorch的数据集和数据传递机制应该就比较清晰明了。Data