




- @sulin123123
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
此前分享了卷积神经网络相关知识,今天实战下:搭建一个卷积神经网络来实现图像分类任务。

smooth L1说的是光滑之后的L1,是一种结合了均方误差(MSE)和平均绝对误差(MAE)优点的损失函数。:与MAE相比,Smooth L1在小误差时表现得像MSE,避免了在训练过程中因使用绝对误差而导致的梯度不连续问题(影响模型的收敛性和稳定性)。:当误差较大时,损失函数会线性增加(而不是像MSE那样平方增加),因此它对离群点的惩罚更小,避免了MSE对离群点过度敏感的问题;在多分类任务通常使
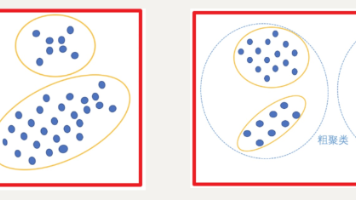
在聚类算法中根据样本之间的相似性,将样本划分到不同的类别中,对于不同的相似度计算方法,会得到不同的聚类结果,常用的相似度计算方法有欧式距离法。聚类算法常用于用户画像,广告推荐,Data Segmentation,搜索引擎的流量推荐,恶意流量识别等方面。一种典型的无监督学习算法,主要用于将相似的样本自动归到一个类别中。2.使用k-means进行聚类,并使用CH方法评估。(一)根据聚类颗粒度分类。(二
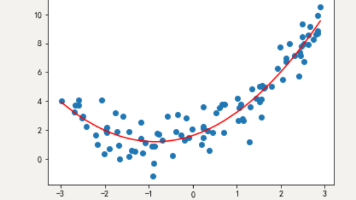
2)增大数据的训练量,还有一个原因就是我们用于训练的数据量太小导致的,训练数据占总数据的比例过小。1)重新清洗数据,导致过拟合的一个原因有可能是数据不纯,如果出现了过拟合就需要重新清洗数据。,模型过于简单时的常用套路,例如将线性模型通过添加二次项或三次项使模型泛化能力更强。原始特征过多,存在一些嘈杂特征, 模型过于复杂是因为模型尝试去兼顾所有测试样本。,有时出现欠拟合是因为特征项不够导致的,可以添
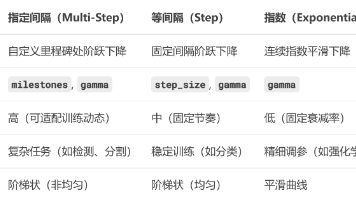
前言:上一篇文章讲解了部分人工神经网络优化方法,这篇文章接着讲述从学习率角度出发的优化方法和其它方法。
**前言**:前面讲述了PyTorch人工神经网络的激活函数、损失函数等内容,今天讲解优化方法。简单来说,优化方法主要是从两个角度来入手,一个是**梯度**,一个是**学习率**。
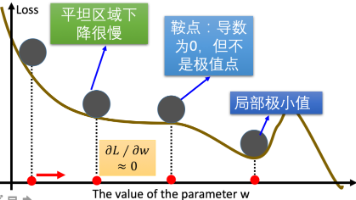
前言:前一篇文章我们讲解了人工神经网络的激活函数,接下来讲解参数初始化和损失函数。
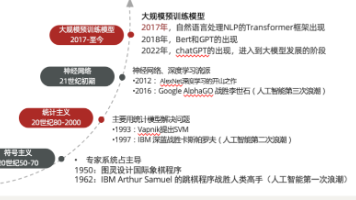
1956年夏季,以麦卡赛、明斯基、罗切斯特和申农等为首的一批有远见卓识的年轻科学家在一起聚会,共同研究和探讨用机器模拟智能的一系列有关问题,并首次提出了“人工智能”这一术语,它标志着“人工智能”这门新兴学科的正式诞生。DL:深度学习,也叫深度神经网络,大脑仿生,设计一层一层的神经元模拟万事万物。ML:机器学习,让机器自动学习,而不是基于规则的编程(不依赖特定规则编程);:让特征更适配算法(如线性模
目前豆包(Doubao)已经集成了 **Seedream 4.0 图像模型**,支持“一句话”完成多种修图任务。

本文分享AI图像修复工具IOPaint
