- @sjkflw121150
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
不知道最近面试是否顺利,是否会经常问到一些自己不熟悉的问题,不知道怎么去回答这些问题,今天小编给大家整理了 2026 年大厂经常问到了的一些面试真题及解析,内容点包含有 java 集合,jvm,并发编程,spring,mybatis,springMVC,微服务,Dubbo,netty,网络,zookeeper,kafka,rabbitMQreadis 缓存,数据库,设计模式。等一线大厂互联网大厂常

我有许多朋友就已经成功的跳槽,有的还在家等候下一步的面试通知。我托朋友们收集了他们面试时所问道的问题,并进行了系统性的整理,找出了一些高频面试题。主要分为三部分,为了不影响阅读,在这以截图形式展示目录与部分内容数据库三范式是什么?有哪些数据库优化方面的经验?请简述常用的索引有哪些种类?什么是聚簇索引和非聚簇索引?Mysql 支持的复制类型?mysql 支持的复制类型?
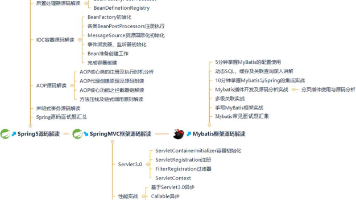
面试中总结了 1000 道经典的 Java 面试题,里面包含面试要回答的知识重点,并且我根据知识类型进行了分类,可以说非常全面了~由于文章篇幅问题,以下只展示部分题目内容,需要完整文档的朋友可以在文末获取。
春招,秋招,社招,我们 Java 程序员的面试之路,是挺难的,过了 HR,还得被技术面,鄙人在去各个厂面试的时候,经常是通宵睡不着觉,头发都脱了一大把,还好最终侥幸能够入职一个独角兽公司,安稳从事喜欢的工作至今...近期也算是抽取出大部分休息的时间,为大家准备了一份通往大厂面试的小捷径,准备了一整套 Java 复习面试的刷题以及答案,我知道很多朋友不知道怎么复习,不知道学习过程中哪些才是重点,其实

从实际情况看,如果你做研发,那首选还是应该去大厂。第一,大厂更尊重技术,也愿意为技术人付更高的薪水。不吹不黑,大部分小公司老板根本意识不到技术的重要性。第二,大厂有更大的用户量,更好的技术应用场景,嗯,高并发、大流量。相信以上的这份大厂面试参考指南能够成为你进入 BATJMZ 等大厂的垫脚石。

最后想说的是,无论你是小白菜鸟,还是技术大牛,日常都不能够落下学习这件事情。机会都是留给有准备的人,只有充足的准备,才可能让自己可以在候选人中脱颖而出。大厂面试远没有我们想的那么困难,摆好心态,做好准备,你也可以的。
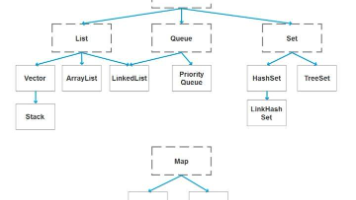
false。初次看到这个结果时其实挺疑惑的,明明都是赋值 128,为什么用==判断却不相等?翻阅资料后才发现,这背后本质是 Integer 底层机制在起作用。顺着这个问题往下深挖,就绕不开Class 文件、字节码指令与包装类缓存的核心原理。下面我们就从根源入手,一步步拆解底层逻辑。本文通过字节码,通俗易懂拆解了三个经典Java问题。借助jclasslib插件能直观看到,Integer自动装箱会调用
总的来说,大多数公司的面试都有共同之处,有些重复的我可能就没写了。另外还有一个小技巧可以分享给大家就是,当面试官问你有什么问题的时候,尽量不要就这么过了,平时准备的时候多积累问题最好是偏应用方向的问题,可以在这个时候询问,既可以为自己答疑解惑,也可以有机会给面试官留下好的印象。以上就是我在面试前后整理搜集的面试资源和一个学习路线规划,希望能对大家有所帮助。

多面试,不要害怕失败,多总结经验。尽早准备,不论是找工作前、面试前还是面试后。熟悉自己的简历。电话和视频面试很平常,面试前提前准备一下。坚持!offer 虽然可能会迟到,但是只要不放弃,就一定不会缺席。
2026 年,全世界都不安定,国内虽然看着和往常没有多大的区别,但对于经济的冲击,不知道又倒退了多少年?大大小小的公司面临倒闭或已破产,对于职场上的我们而言,无疑是致命的打击,好了,回到主题,作为 JAVA 博主,看下 JAVA 近况~今年,从 java 转到别的行业的人不少,也有不少人挤进这个市场想要分得一杯羹。年复一年,年年如此。当然,Java 程序员市场需求依然是比较大的,而且 Java 岗