- @sinat_52032317
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
机器人系统仿真:是通过计算机对实体机器人系统进行模拟的技术,在 ROS 中,仿真实现涉及的内容主要有三:对机器人建模(URDF)、**创建仿真环境(Gazebo)以及感知环境(Rviz)**等系统性实现。URDF是 Unified Robot Description Format 的首字母缩写,直译为统一(标准化)机器人描述格式,可以以一种 XML 的方式描述机器人的部分结构,比如底盘、摄像头、激
Arbotix:Arbotix 是一款控制电机、舵机的控制板,并提供相应的 ros 功能包,这个功能包的功能不仅可以驱动真实的 Arbotix 控制板,它还提供一个差速控制器,通过接受速度控制指令更新机器人的 joint 状态,从而帮助我们实现机器人在 rviz 中的运动。实现流程:1.2 创建新功能包,准备机器人 urdf、xacro 文件参考上一讲.【ROS】—— 机器人系统仿真 —URDF优
Apollo中对路径规划解耦,分为路径规划与速度规划两部分。并将规划分为决策与优化两个部分。•路径规划—— 静态环境(道路,静止/低速障碍物)•速度规划—— 动态环境(中/高速障碍物)路径规划的配置文件在中//路径规划 stage_type : LANE_FOLLOW_DEFAULT_STAGEtask_type : PIECEWISE_JERK_PATH_OPTIMIZER //速度规划 tas

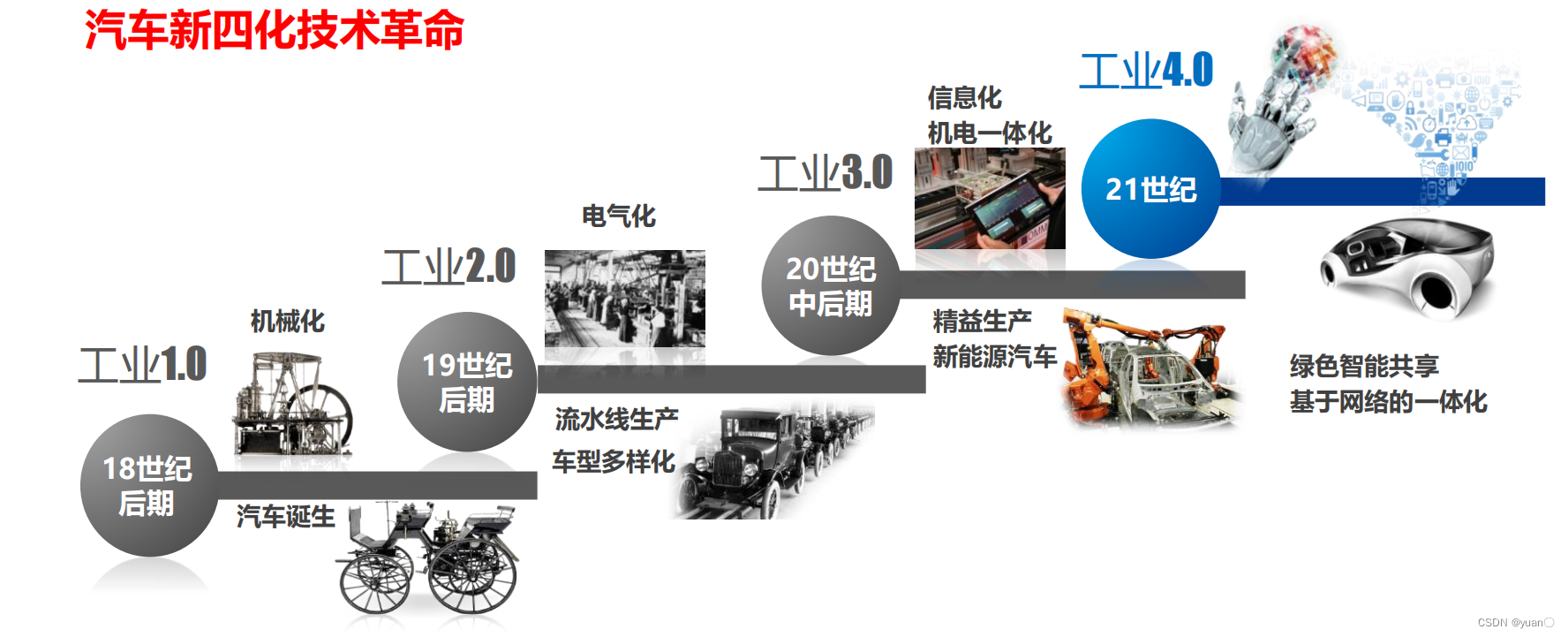
从工业1.0的机械化、2.0的电气化到3.0的机电一体化,汽车工业每次都发生重大变革;以CPS为标志的工业4.0时代,将使汽车在未来10 ~20年中发生革命性的变化.工业4.0时代,传统汽车产业正在迎来一场全新的技术变革,即 “新四化”:电动化(低碳化)、智能化、网联化及共享化,传统汽车企业面临新的机遇和挑战。环境感知、智能决策、控制执行是智能网联汽车的关键技术,下图为智能网联汽车“三横两纵”技术
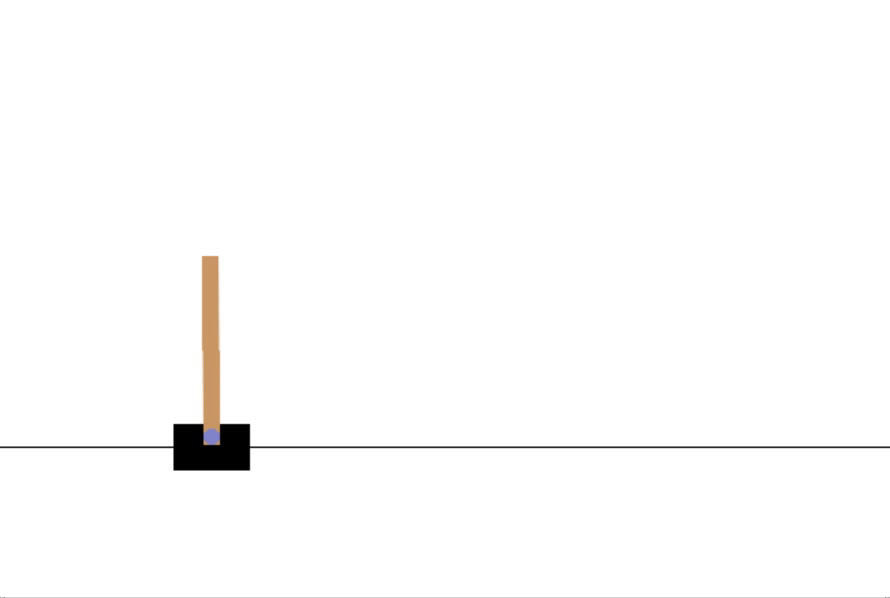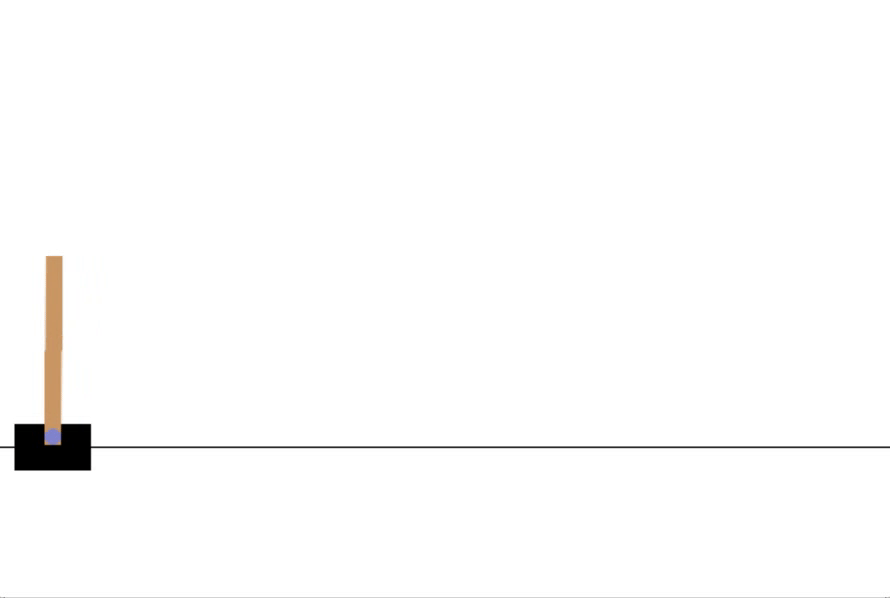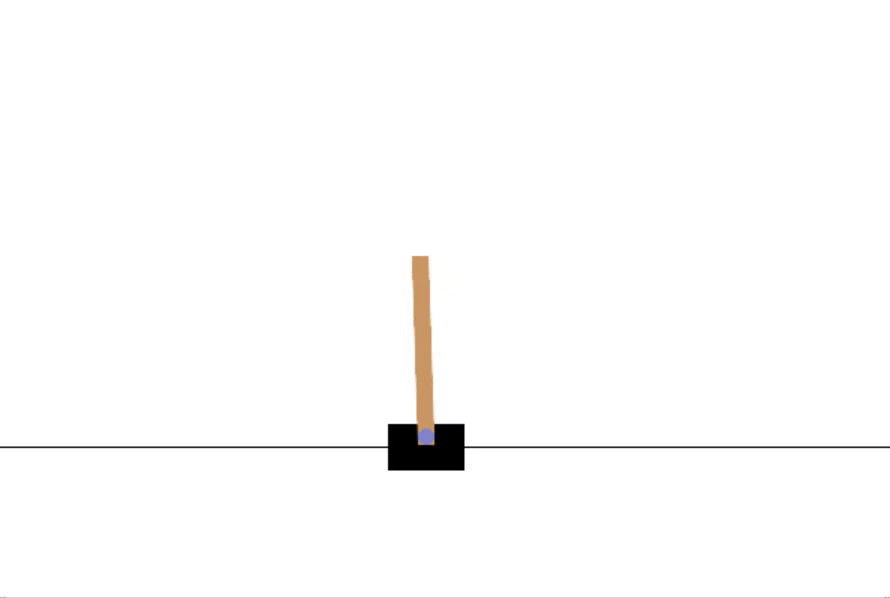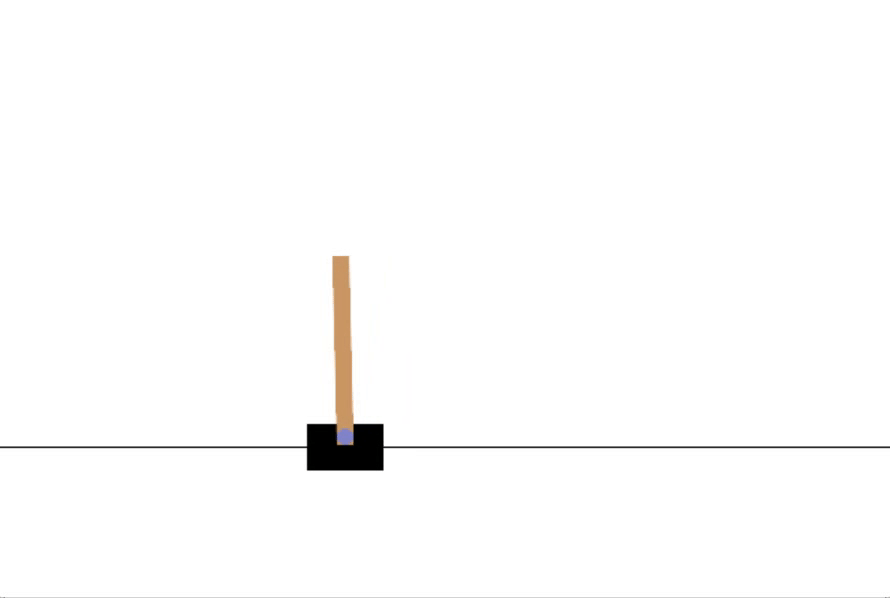
在车杆环境中,有一辆小车,智能体的任务是通过左右移动保持车上的杆竖直,若杆的倾斜度数过大,或者车子离初始位置左右的偏离程度过大,或者坚持时间到达 500 帧,则游戏结束。智能体的状态是一个维数为 4 的向量,每一维都是连续的,其动作是离散的,动作空间大小为 2。的,我们每次训练神经网络的时候从训练数据中随机采样一个或若干个数据来进行梯度下降,随着学习的不断进行,每一个训练数据会被使用多次。如果两套
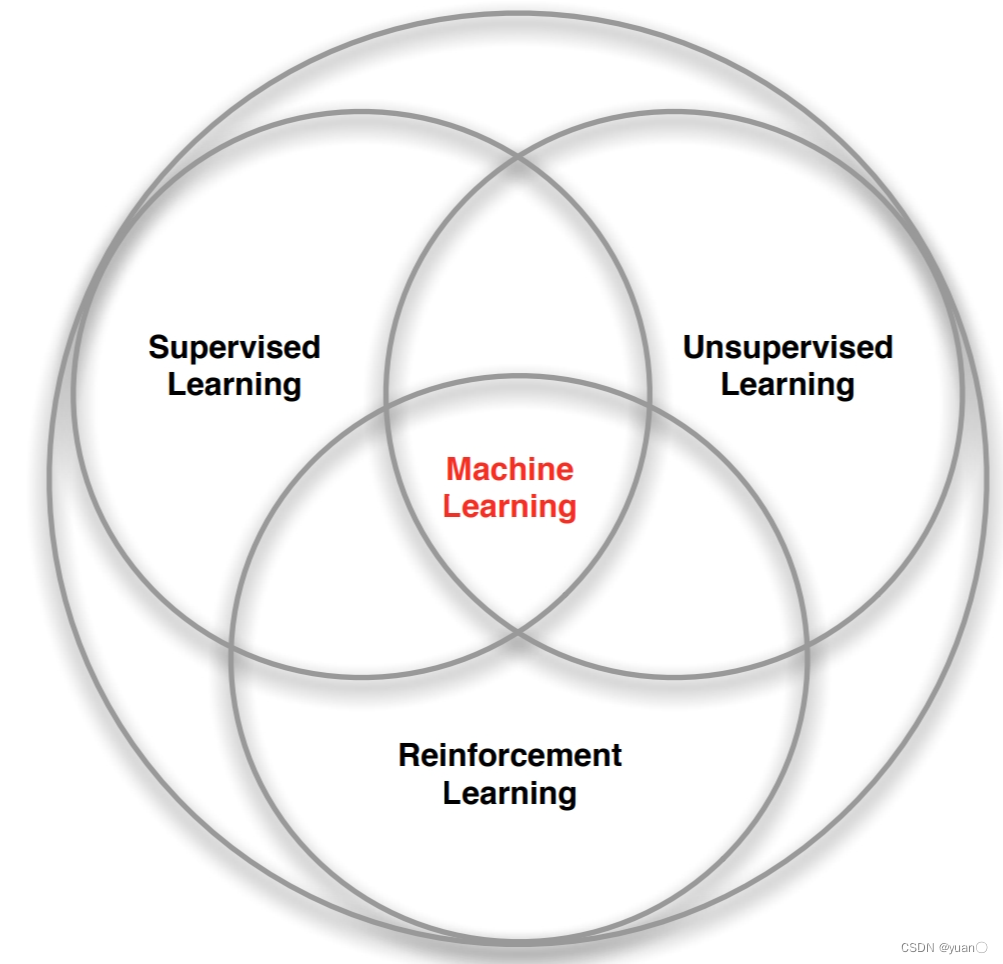
通过从交互学习中实现目标的计算方法感知:在某种程度上感知周围环境行动:采取行动来影响状态或者达到目标目标:随着时间的推移,最大化奖励。
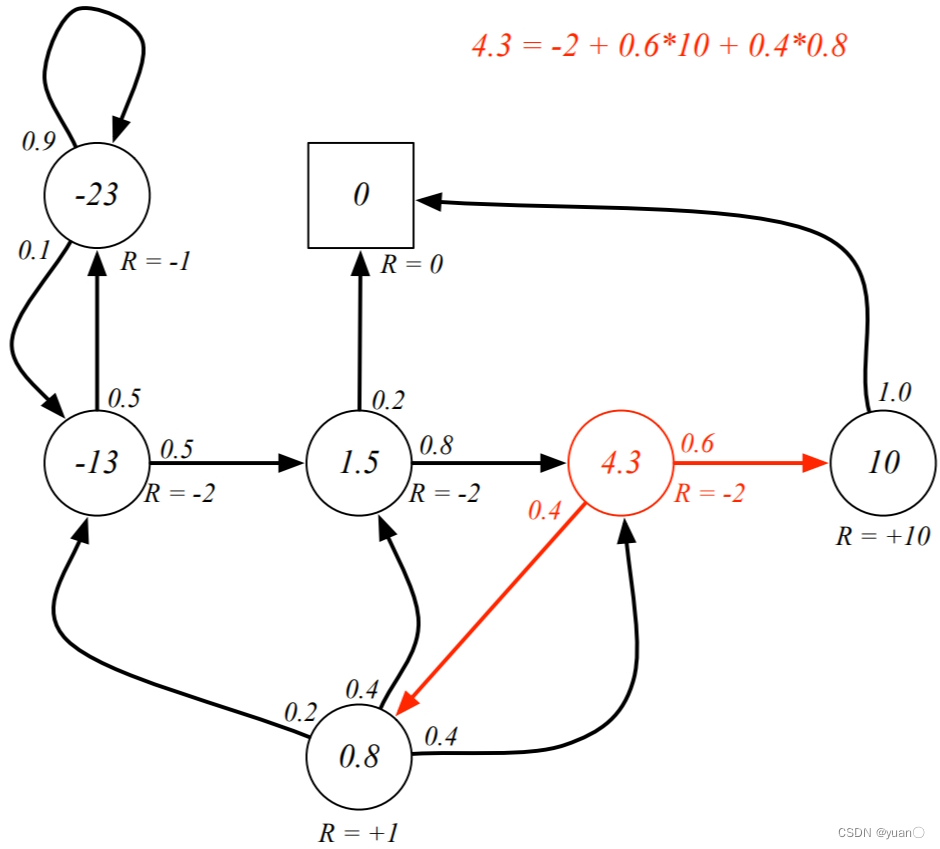
在此推荐另一篇文章【自动驾驶决策规划】POMDP之Introduction“The future is independent of the past given the present”未来状态的概率分布只与当前状态有关,而与过去状态无关。定义:性质:Pss′\boldsymbol{P}_{ss^{\prime}}Pss′为从状态sss转移到状态s′s's′的概率,又称一步状态转移概率。P\b
动态规划)是程序设计算法中非常重要的内容,能够高效解决一些经典问题,例如背包问题和最短路径规划。动态规划的基本思想是将待求解问题分解成若干个子问题,先求解子问题,然后从这些子问题的解得到目标问题的解。最优子结构:最优解可以被分解为子问题。最优性原理适用:重叠子问题:子问题经常重复出现。解决方案可以被缓存和重复使用。马尔可夫决策过程符合这两个属性。贝尔曼方程提供了递归分解。价值函数存储和重用解决方案
探索和利用是强化学习试错型学习(trial-and-error)中不可少的一部分;多臂老虎机问题与强化学习的一大区别在于其与环境的交互并不会改变环境,即多臂老虎机的每次交互的结果和以往的动作无关,所以可看作无状态的强化学习多臂老虎机是研究探索和利用理论的最佳环境(理论渐进最优收敛为OlogTO(\log T)OlogT各类探索和利用方法在RL,特别是在多臂老虎机中常用。

之前的章节提到过在线策略算法的采样效率比较低,我们通常更倾向于使用离线策略算法。然而,虽然 DDPG 是离线策略算法,但是它的训练非常不稳定,收敛性较差,对超参数比较敏感,也难以适应不同的复杂环境。2018 年,一个更加稳定的离线策略算法 Soft Actor-Critic(SAC)被提出。SAC 的前身是 Soft Q-learning,它们都属于最大熵强化学习的范畴。Soft Q-learni