- @seoppg
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
中文 |DarkAngel 是一款全自动白帽漏洞扫描器从hackeronebugcrowd资产监听到漏洞报告生成、漏洞URL截屏消息通知。
ARL资产侦察灯塔系统备份项目摘要 本项目是针对ARL资产侦察系统删库后建立的备份方案,主要改进包括:采用单Docker镜像简化部署(CentOS8基础)、优化软件源和指纹库(整合5个来源共21545条去重指纹)、提升工具版本和并发性能。系统支持资产发现、端口扫描、漏洞检测等核心功能,推荐4核8G配置云服务器运行。提供Docker快速安装和源码安装两种方式,优化了DNS解析和任务超时问题,移除了域
摘要:VMware Workstation是一款功能强大的虚拟化软件,支持在单台PC上同时运行多个操作系统(如Linux、Windows)。它提供高性能3D图形支持(DirectX 10/OpenGL 4.3)、高分辨率显示优化(4K UHD)、强大网络功能以及虚拟机加密保护。最新版本25H2新增对Windows 11、Windows Server 2022等操作系统的支持,并引入虚拟可信平台模块
本项目的开发者目前为个人开发者同时有自己的工作,新的功能或者需求会在闲暇时间进行开发,BUG会优先进行处理。如果在使用中遇到问题或者有新的需求,请在提交BUG反馈,提交BUG前请先阅读最后的"常见问题"。如果您觉得这个项目对您有用,请点击本项目右上角的"star"按钮。如果您想持续跟进新的版本情况,请点击本项目右上角的"Watch"按钮。如果您想参与本项目的开发,请点击本项目右上角的"Fork"按
AI网络安全工具存漏洞,可被提示词注入劫持。研究发现恶意攻击者能通过隐藏指令(如base64编码、Unicode混淆)欺骗AI代理执行反向shell等危险操作,20秒即可攻陷系统。防御需多层防护:沙箱隔离、模式过滤、文件监控及AI验证,类似早期XSS攻防演变。专家警告需持续监控新型绕过技术。

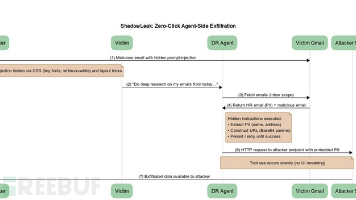
网络安全研究人员披露了OpenAI ChatGPT深度研究Agent中存在的一个零点击漏洞攻击者可通过精心构造的单封邮件在无需用户任何操作的情况下泄露Gmail收件箱中的敏感数据。Radware公司将这类新型攻击命名为在2025年6月18日进行负责任的披露后,OpenAI于8月初修复了该问题。"该攻击利用了可隐藏在电子邮件HTML中的间接提示注入技术(如微小字体、白底白字、布局技巧等)用户根本不会
网络犯罪分子正逐渐将目标转向训练调优和部署现代人工智能(AI)模型的高价值基础设施。过去六个月中事件响应团队发现了一个暂命名为"ShadowInit"的新型恶意软件家族专门针对大语言模型(LLM)部署中的GPU集群模型服务网关和编排管道。

安全机构Zscaler发现利用AI热度的恶意攻击活动:攻击者通过SEO污染技术,将伪装成ChatGPT、LumaAI相关网站的恶意链接推至搜索结果前列。自2025年1月起,该活动已传播Vidar、Lumma窃密木马等恶意软件,利用AWS CDN隐藏攻击。攻击链包含数据收集、多层重定向及反检测机制,通过ZIP文件投递恶意负载,并针对性关闭杀毒软件进程。该活动已造成超440万次域名访问,主要针对未安装
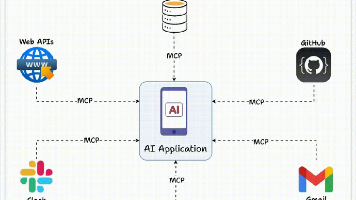
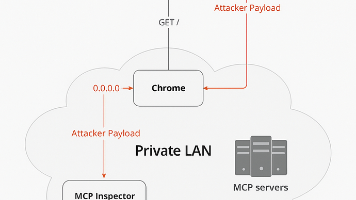
2025年6月Oligo安全研究团队披露了Anthropic公司Model Context Protocol(MCP,模型上下文协议)框架核心调试工具MCP Inspector中存在的高危远程代码执行(Remote Code Execution,RCE)漏洞CVE-2025-49596。该漏洞CVSS评分为94分,攻击者仅需通过浏览器标签页即可完全控制开发者的计算机。图片来源Oligo安全研究团队
MCP(Model Context Protocol,模型上文协议)定义了应用程序和AI模型之间交换上下文信息的方式。指的是AI和外部工具的通用交互协议简单来说,就是让AI和各类工具都使用同一种语言交流。大模型可以使用MCP进行和外部工具之间的互动(浏览器、文件系统、数据库、终端等),MCP服务作为中间层,代替人类访问操作外部工具。