- @sara_han
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
ChatGPT为何懂礼貌、不胡编、会自省?背后是RLHF“人类驯化术”——通过三步:SFT教标准回答、奖励模型学人类偏好、PPO+KL惩罚优化行为,让AI从“野性天才”变“知书达理”。LLaMA-2等模型也靠它对齐价值观。新方法DPO更轻更快,跳过奖励模型直接学偏好。核心不是教知识,而是教“做人”——AI的温度,源于人类定义的“好”。
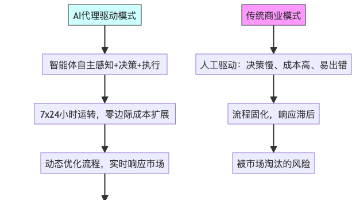
AI代理正在快速重塑商业模式,从客服到决策层全面渗透。传统依赖人力的模式面临效率低、成本高等问题,而AI代理能自主感知、思考、执行并进化,实现指数级效率提升。三大核心改变包括:个性化客户体验、自动化运营流程和快速创新迭代。企业需警惕"伪AI代理",选择合适场景切入,搭建代理中台并重构人机协作。AI代理不是替代人类,而是构建"智能增强型组织"的关键,正在成为商
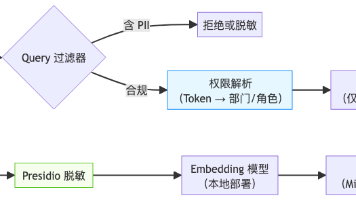
摘要:在企业部署RAG(检索增强生成)系统时,合规与隐私保护成为关键挑战。本文提出五大核心措施:1)文档摄入和用户查询双阶段PII识别与脱敏;2)全链路本地化部署确保数据不出境;3)完整审计日志记录并脱敏存储;4)禁用境外LLM并实施最小权限控制;5)定期合规演练。通过融合技术先进性与合规性,构建符合GDPR、个保法等要求的RAG系统,为金融、医疗等强监管行业提供安全的AI解决方案。(149字)
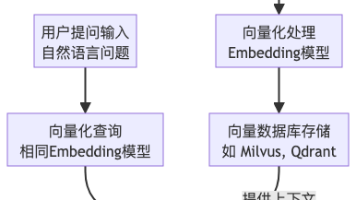
RAG(检索增强生成)是一种结合大模型与私有知识库的AI架构,通过先检索相关信息再生成回答,提升准确性。其核心流程包括文档分块、向量化、存储、检索和生成,其中向量数据库是关键组件。混合检索(关键词+语义)能进一步提高效果。评估RAG需关注召回率、答案相关性等指标。实战中可使用Python、Qdrant和OpenAI构建企业知识库问答系统,未来可探索动态分块、查询改写等进阶方向。RAG的价值在于解决
摘要: ModelContextProtocol(MCP)是一种标准化协议,旨在解决大模型(LLM)无法直接操作现实世界的“知而不能行”问题。通过统一工具调用方式,MCP使模型能够动态调用外部工具(如数据库、API等),获取真实数据或执行动作,而非依赖幻觉生成。其核心优势在于平台无关性,支持工具动态注册和上下文传递,与RAG、LangChain等技术互补。目前,MCP生态处于早期阶段,但已被Ade
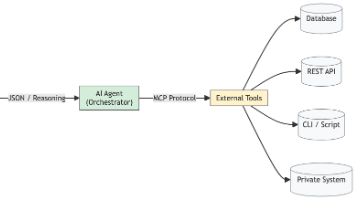
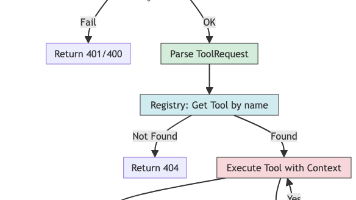
本文详细介绍了如何使用Go语言构建一个生产就绪的MCP Server,用于支持AI Agent调用后端服务能力。文章从项目结构设计入手,采用典型Go微服务架构,重点实现了线程安全的工具注册中心、HTTP接口处理、会话级上下文管理以及完善的错误处理机制。通过单元测试和集成测试确保协议合规性,并提供了Docker和CI/CD部署方案。该架构具有高内聚、低耦合的特点,支持动态工具注册和跨工具协作,使后端
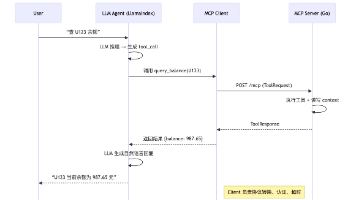
本文详细介绍了如何将自研MCPServer接入主流LLM Agent框架(以LlamaIndex为例),实现工具调用功能。主要内容包括:1)Agent执行引擎的工作原理;2)MCPClient的核心设计要点(连接管理、请求构造、容错控制);3)具体集成步骤和代码示例;4)动态工具发现机制;5)性能优化策略;6)实用调试技巧。通过实现MCPClient,开发者能将后端服务转化为AI Agent可调用
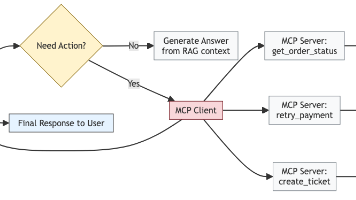
摘要: 大模型落地需结合RAG(检索增强生成)与MCP(模型上下文协议),前者扩展知识,后者执行动作。以智能客服为例,RAG检索流程文档,MCP调用API处理支付失败等任务,形成“感知→决策→执行”闭环。需支持工具串行/并行/DAG编排,设计幂等性与补偿机制保障可靠性,并通过压测验证高并发性能。RAG+MCP协同架构实现从“问答”到“行动”的跃迁,是企业级AI落地的关键。
摘要: 本文对比了四种主流AI Agent工具调用协议(OpenAI Function Calling、Google Tool Use、AWS Bedrock Agents和开源MCP)的设计哲学、扩展性、生态支持和标准化前景。前三者为厂商绑定方案,适合单一云平台快速部署,但存在锁定风险;MCP作为开放协议,支持多模型、混合云及动态工具扩展,长期灵活性更优。生态上,OpenAI成熟但封闭,MCP社
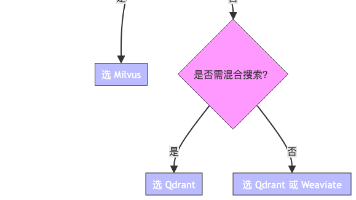
本文对比了主流向量数据库Milvus、Pinecone、Weaviate和Qdrant的核心功能、部署模式、性能表现和运维成本。从功能看,Milvus和Qdrant适合强标量过滤,Weaviate和Qdrant适合混合检索。Pinecone为托管服务适合初创团队,Milvus适合大规模K8s部署,Qdrant轻量适合中等规模。性能测试显示Qdrant延迟最低,Milvus吞吐量最高。运维上Milv