




- @qq_64605578
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
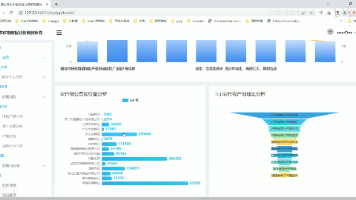
字节跳动 DeepSeek R1 语言模型的对话交互能力、Bert 模型的文本理解优势,结合 Django3 与 Vue2 的前后端开发架构,能够实现就业数据的多维度分析、可视化呈现与精准推荐,构建高效、智能的就业服务生态,因此开发基于深度学习的大学生就业数据分析可视化推荐系统。
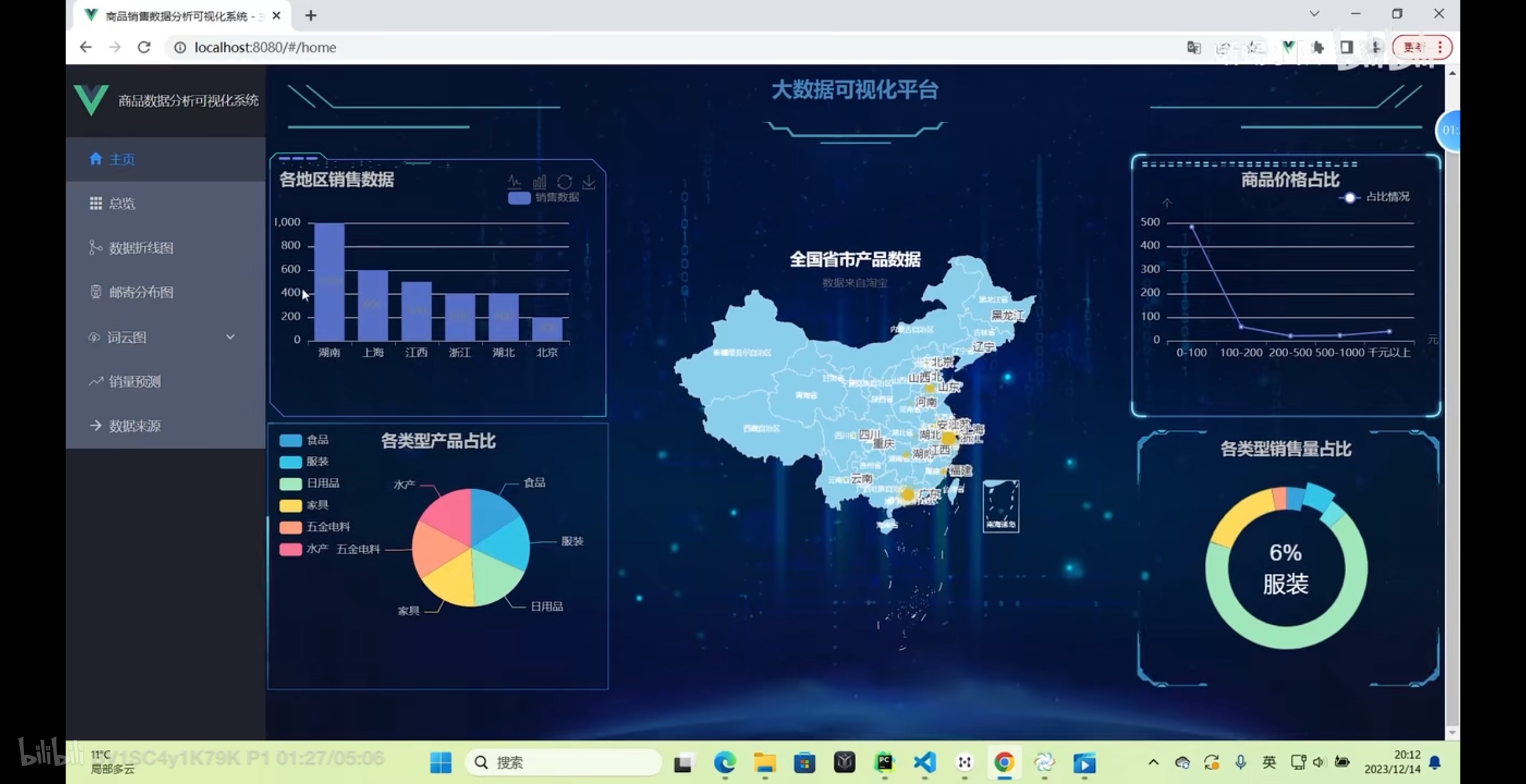
前端框架:Vue,Echats后端:Django大数据处理框架:Spark数据存储:Mysql编程语言:Python数据可视化:Echarts五、项目功能展示登录页面首页大屏后台登录后台管理六、权威视频链接【数据分析大屏】基于Django+Vue汽车销售数据分析可视化大屏,计算机毕业设计实战项目,免费全集教学。源码文档等资料获取方式需要全部项目资料(完整系统源码等资料),主页+即可。需要全部项目资

TensorFlow作为开源机器学习框架,广泛应用于自然语言处理(NLP)领域。舆情分析通常结合文本分类、情感分析和主题建模技术,核心算法包括深度学习模型如LSTM、BERT和Transformer。后端:Django大数据处理框架:数据存储:MySQL编程语言:Python自然语言处理:随机森林算法数据可视化:Echarts数据采集:Requests爬虫。
多元线性回归(Multiple Linear Regression)是一种用于预测目标变量与多个特征变量之间关系的统计分析方法。以下是对多元线性回归算法的介绍及其相关公司的一些信息。多元线性回归算法介绍概述多元线性回归是一种扩展的线性回归模型,旨在预测一个因变量(目标变量)与多个自变量(特征变量)之间的线性关系。其基本模型形式为:YYY 是因变量(目标变量)。β0β_0β0 是截距(当所有自变量

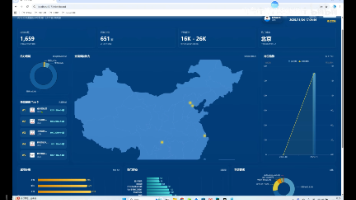
本项目在构建一套基于 Spark+Hive 的旅游景点数据分析可视化推荐系统,解决传统旅游推荐与数据分析存在的核心问题。
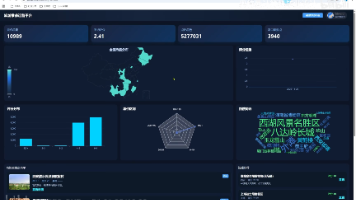
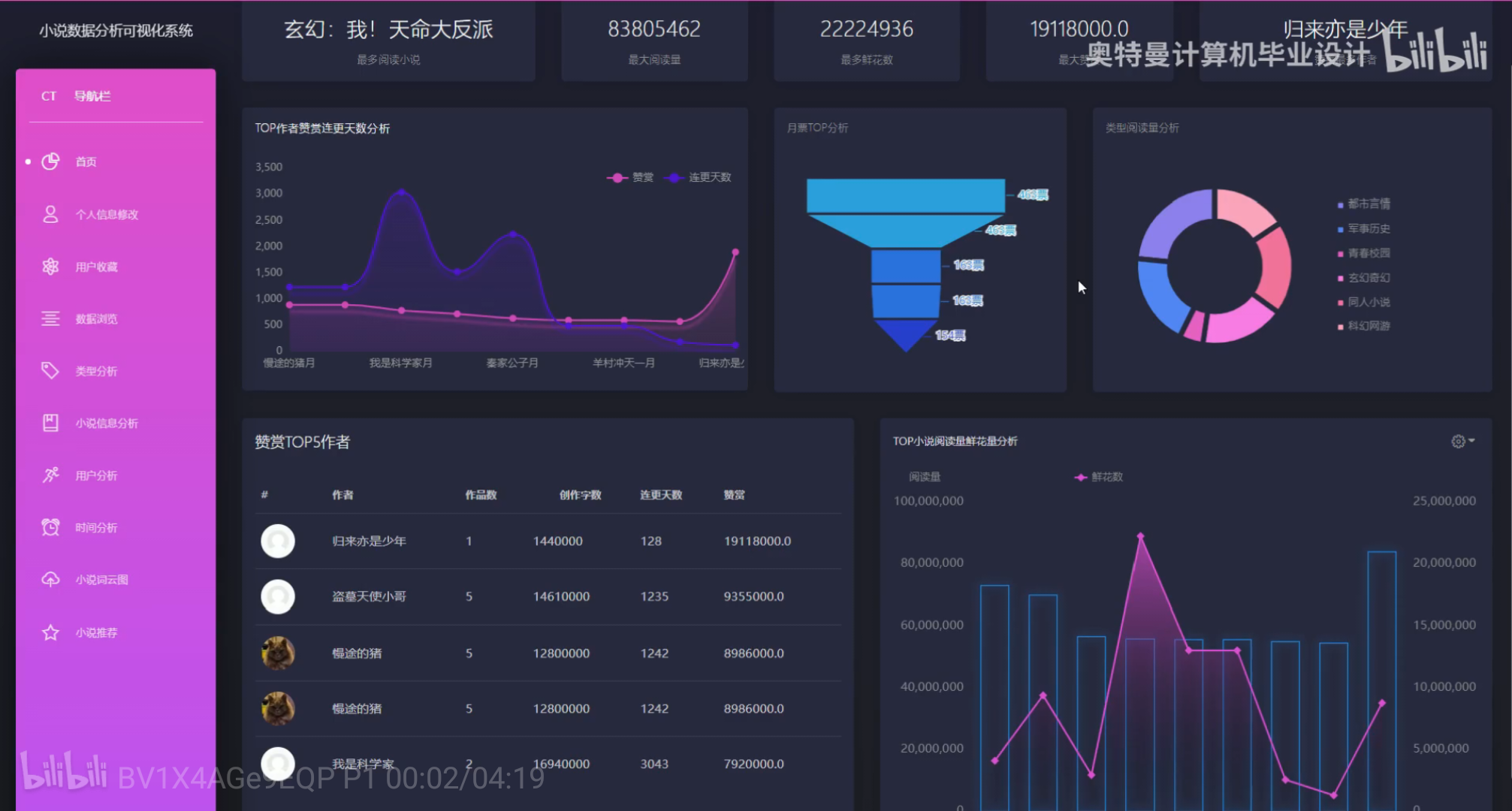
该系统利用Hadoop强大的分布式存储和计算能力,结合Spark的高效数据处理速度,能够快速分析海量小说内容和用户行为数据。通过Mysql数据仓库进行高效管理和查询,系统为个性化推荐提供了坚实的数据基础。同时,系统采用协同过滤等机器学习算法,精准挖掘用户喜好,实现个性化推荐。
该项目旨在基于Spark大数据处理框架,对哔哩哔哩平台的数据进行舆情分析和推荐系统的设计与实现。利用爬虫技术获取哔哩哔哩的相关数据,并使用Spark进行数据清洗、转换和存储。通过NLP技术对用户评论和弹幕进行情感分析,识别热点事件和用户情感倾向。基于用户的兴趣和舆情分析结果,构建个性化的推荐系统,向用户推荐相关内容。利用Spark Streaming对实现弹幕和评论进行分析,实现实时舆情监控与推荐

深度学习框架使用TensorFlow或PyTorch作为深度学习框架,构建和训练卷积神经网络模型,支持高效的计算和灵活的模型设计。卷积神经网络(CNN)应用CNN技术进行图像分类和特征提取,利用多层卷积、池化和全连接层提升模型的识别能力。数据增强技术采用图像增强技术(如旋转、缩放、裁剪等)扩展训练数据集,提升模型的鲁棒性和泛化能力。计算机视觉算法集成计算机视觉算法(如边缘检测、图像分割等)提高交通

前端框架:后端:Django数据处理框架:Spark数据存储:Hive编程语言:票房预测算法:Scikit-learn随机森林预测算法推荐算法:协同过滤推荐算法数据可视化:Echarts。
