
写文章




- @qq_63713328
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
python七行代码将九九乘法表写入Excel中
教你python用七行代码写九九乘法表放入到excel中
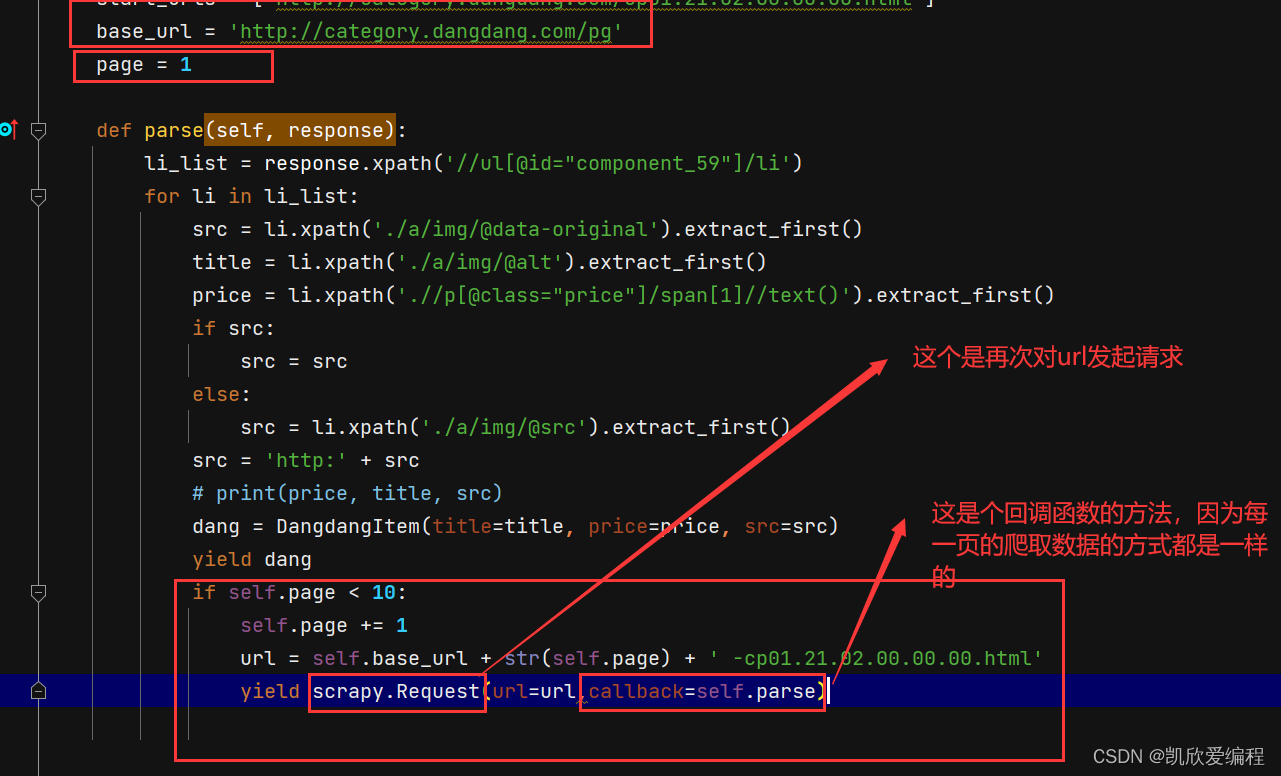
scrapy框架的安装与基本使用,scrapy分页数据的抓取
本章主要是讲解scrapy的安装与基本使用,讲解scrapy的实现基本流程,以及如何使用scrapy进行分页抓取数据
【鸿蒙开发从0到1 day08】
本章主要学习了arkTs中的联合类型和枚举,然后就是arkUI里面的基础知识点,认识了常用的一些组件,arkUI中字体的一些布局方式,字体的样式,以及图片组件和文本组件的的对齐方式,其次要注意文本组件中文本缩进和文本溢出的使用

【鸿蒙开发 day14】
本章主要学习了ArkTs中的条件分支语句和循环的一些语法,让我们使用分支去实现控制渲染,用循环去遍历数组.
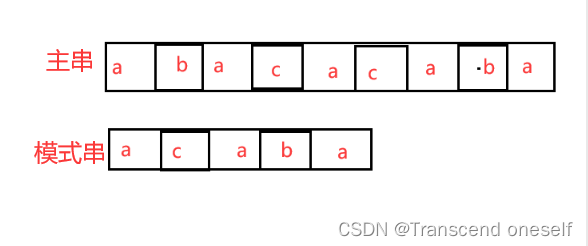
KMP算法(快速手算求模式串的next),超详细KMP的子串匹配流程并用伪代码实现KMP算法
KMP算法是一种字符串匹配算法,用于在一个文本串中查找一个模式串的出现位置。它通过预处理模式串,利用已知信息来避免在文本串中不必要的回溯,从而提高匹配效率。具体来说,KMP算法使用一个部分匹配表(即next数组)来记录模式串中每个前缀子串的最长公共前后缀长度,然后根据这个表进行匹配。时间复杂度为O(m+n),其中m和n分别为模式串和文本串的长度。
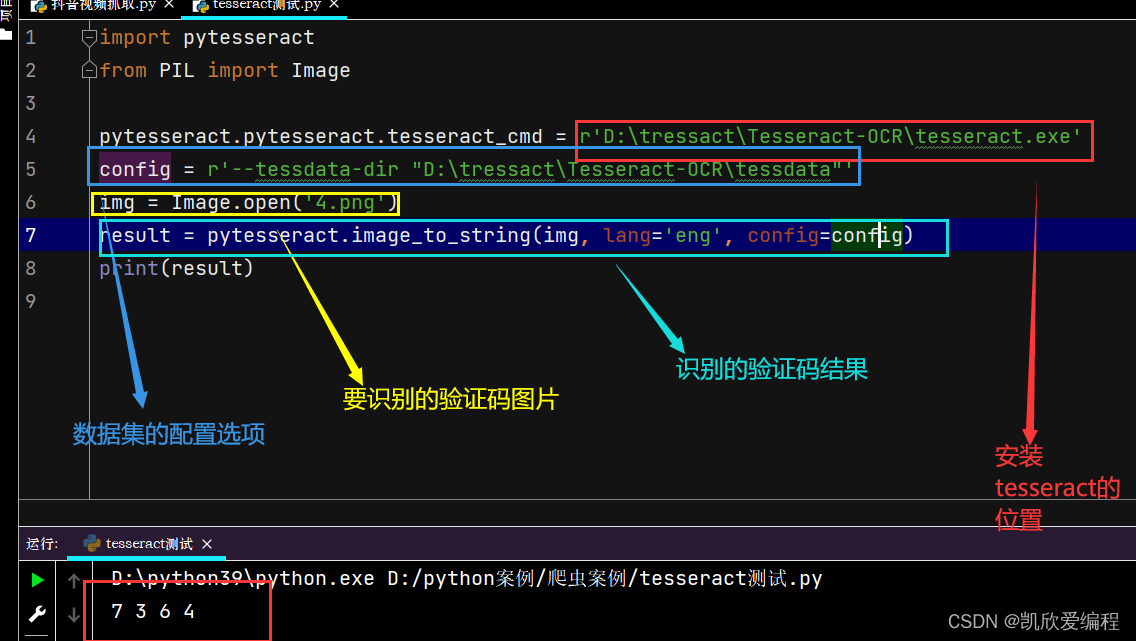
tesseract第三方图文验证码识别用法
利用开源的tesseract快速识别图文验证码
到底了